



- 相关博文
- 最新资讯
-
本文详细介绍了Hadoop分布式系统搭建及HBase数据库配置的操作流程。首先通过创建3台虚拟机(v1、v2、v3)完成网络配置和主机名设置,实现v1免密登录其他节点。随后安装配置JDK、Hadoop和Zookeeper环境,包括核心配置文件的修改和环境变量设置。第二部分重点演示了HBase分布式数据库的安装与操作,包括创建major表(含inf和other两个列族)、数据插入/查询/删除操作,以及表结构的修改(设置单元格数目、删除列族、设为只读)和最终的删除验证。整个实验完整展示了从系统搭建到数据库操作的
-

- 无限-无畏
- 昨天
-
-
摘要:本文介绍了使用Anaconda创建Python虚拟环境并部署PySpark任务的完整流程。首先在本地安装Anaconda并创建指定Python版本的虚拟环境(如Python 3.7),调试PySpark脚本确保单机运行正常。然后将虚拟环境打包为zip文件,与脚本一起上传至HDFS。最后通过spark-submit命令提交任务,其中关键配置包括指定虚拟环境路径、Python解释器路径以及各类资源参数(内存、核心数等)。文末还提供了常用Spark参数说明(如driver/executor资源配置)
-

- C.R.xing
- 昨天
-
-
举个例子,如果第一条消息A过期时间30秒,第二条消息B过期时间10秒,即便消息B先过期了,基于RabbitMQ TTL的。3,队列A没有消费者,这样队列A中的消息会在TTL到期时自动经过死信交换机转发到死信队列B。如上所述,消息过期会被转发到死信队列,这样我们可以按照以下步骤实现延迟队列。4,消息会在交换机中等待到达延迟时间后再路由到绑定队列。1,创建普通队列A,设置消息TTL,没有消费者。机制,也是消息A进入死信队列后,才会检查消息B。4,消费者监听死信队列B,实现延迟消费。2,给队列A设置死信交换机。
-
- 秦小郎
- 前天
-
-
本文将介绍Java方向与Elasticsearch(ES)的集成应用。ES是一款分布式搜索分析引擎,具有实时搜索、高性能等特点。文章首先概述ES核心概念如文档、索引、分片等,然后详细讲解Java客户端API的两种类型(低级和高级REST客户端),以及通过Maven添加依赖和配置连接的具体步骤。接着提供了Java操作ES的代码示例,包括创建索引、插入数据和查询数据的关键API使用。全文旨在帮助Java开发者快速掌握ES集成与应用技术。
-
- 编程界的彭于晏qaq
- 昨天
-
- 数据错误
-
针对 Elasticsearch 6.8.23 在 Kubernetes 中运行、每节点 64GB 内存、曾出现 OOM 的情况,分析内存使用过高的原因,并提供一份详细的优化建议清单,内容将包括配置参数建议(如 jvm.options、elasticsearch.yml、limits.conf 以及 Pod 配置)。综上,在每节点64GB可用内存情形下,可以考虑将堆调整到约30GB(Xms=30g, Xmx=30g),剩余约34GB留给操作系统缓存和其他非堆用途。同时,应在容器启动脚本或宿主机设置。
-

- 喝醉酒的小白
- 17小时前
-
-
解决 docx文档 复杂表格合并问题
-
本文介绍了如何在本地部署阿里Qwen3大模型并连接到Elasticsearch实现RAG应用。主要内容包括: 创建Elasticsearch API key获取访问凭证 编写Python代码实现RAG流程,包括Elasticsearch查询、上下文构建和Qwen3模型调用 配置环境变量和证书,确保代码正常运行 测试Qwen3模型接口工作正常 修改代码适配最新Elasticsearch版本的数据结构 最终成功运行示例查询"哪些人在茶会",Qwen3准确识别出故事中的角色并给出详细回答 文章
- 数据错误
-
函数是组织好的、可重复使用的,用来实现单一、或相关功能的代码段。函数可以提高应用的模块性和代码的可重复性。python 有许多内置的函数比如 print 打印函数,python 也支持用户实现自己的函数,这类函数也称之为自定义函数。定义一个函数需要遵循以下规则:函数代码块以def关键词开头,后接函数标识符名称和圆括号()。任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。函数的第一行语句可以选择性地使用文档字符串 — 用于存放函数说明。函数内容以冒号。
-

- 程序员水冠
- 昨天
-
-
基于上述的项目背景和难点, 最终决定采用 Spark,首先数据量大及计算方式复杂, 如果使用传统的服务方式, 需要大量的服务器资源, 而目录不固定, 使数据读取变的复杂, 且普通服务不太可能在 4h 内处理完毕;2、 Drvier 的字节级别代码会分发至将要执行的 Executor 上, 这些计算过程实际上是在每个节点本地计算并完成,每个spark会在集群中有一个或多个Executor,Executor 之间也可能会有数据的传输,比如一些聚合函数执行。过少,并行度不足,任务处理数据量大,影响作业完成时间;
-

- 阳光下是个孩子
- 昨天
-
-
让我们以开放的心态拥抱变化,同时保持警惕,确保技术为人类福祉服务。产品个性化率超80%。工业化的特点是批量化、标准化(标品),只有标品,才能批量生产,才能提高效率,降低成本;数字化时代的特点是个性化、定制化(订制品)!5G将覆盖全球90%的人口,6G技术开始试点,实现毫秒级延迟和TB级传输速度。2100年前,人类将在火星建立永久定居点,开启星际殖民时代。22世纪,人类意识将实现数字化上传,实现“数字永生”。面对全球性挑战,人类将成立世界政府,协调各国行动。2045年前,AI将超越人类智能,引发技术奇点。
-

- 文火冰糖的硅基工坊
- 昨天
-
-
面试突击指南:高效备战Java岗位 针对Java面试,建议分三梯队学习:第一梯队(核心必会)包括Java基础、Spring框架、数据库和微服务,需精通原理并能手写代码;第二梯队(竞争力提升)涵盖Docker、Git、Kafka等工具,需熟悉应用场景;第三梯队(加分项)如设计模式、监控工具等,了解概念即可。 突击技巧:整理高频面试题(如String不可变性、Spring事务原理),模拟面试练习,克服紧张。心态上避免完美主义,优先掌握核心技能,遇到不会的问题可引导至熟悉领域。抓重点+实战,足以应对初/中级岗位。
-

- Jasmine65590
- 昨天
-









-
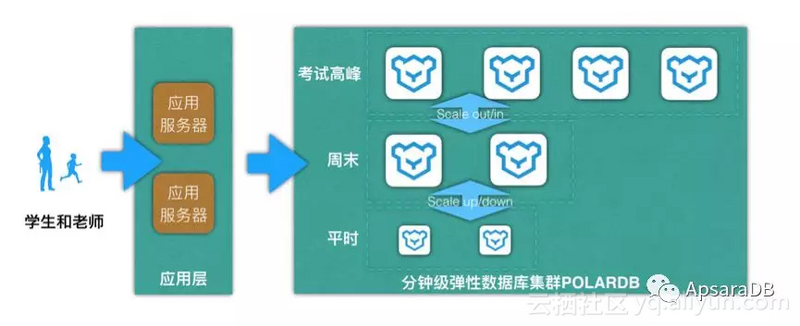
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

在任何以数据为中心的工作中,对SQL有深刻的理解都是成功的关键,尽管这不是工作中最有趣的部分。事实上,除了SELECT FROM WHERE GROUP BY ORDER BY之外,还有更多的SQL方法。你知道的功能越多,操作和查询所需的内容就越容易。
-

你的企业混合云了吗?来看看评估混合云解决方案时要注意的6个原则!
混合云如今很流行。几乎每个IT公司都声称已部署了解决方案,但实际上实现的却很少。相反,它们拥有与多个云实例进行某种程度集成的私有云。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
-

在我们开始之前,作者想先声明一下,本文并非要从两者中分出一个胜负,所以无论你是哪一方的忠实支持者,都建议你仅客观看待本篇文章。
-

-

-

云应用程序是热门话题。很多时候,我们会遇到像云原生应用程序和云计算应用程序这样的术语。首先,很少有人同时使用这两个术语。但两者之间存在着模糊的界线。云原生和云计算的区别到底是什么呢?为什么它如此重要?让我们来看看!
-

-

最近,Jrebel公布了一份2020 Java生态系统报告,这份报告主要关注开发人员在开发过程中使用的技术。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

超级干货!31 条2020 年最新版 ZooKeeper面试题,先收藏再看
金三银四,虽然受疫情影响,大多数企业还未正式复工,但没有条件,创造条件也要上,许多企业已经开始物色合适的人才了,我们怎么能掉队?趁着在家里,赶紧预习一下面试题,只要一复工,马上就开始“打仗”了!
-

相信对于大部分的大数据初学者来说,一定遇见过Hadoop集群无法正常关闭的情况。有时候当我们更改了Hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
-

这篇分享主要总结了数据从业人员在实践中可能遇到的陷阱与缺陷。跟其他新起的行业一样,数据科学从业人员需要不停的去考虑现在,考虑未来;需要不断的斟酌工作方法的合理性,正确性。思索不断,才能前行。
-

-

别再用那些已经淘汰的技术了!2020 年 9 大顶级 Java 框架出炉!!
诞生于1995年的Java,目前已在134,861个网站上广泛使用,包括ESPN、SnapDeal等。在其24年的成长史中,Java已经证明了自己是用于自定义软件开发的顶级通用编程语言。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

如今,Python真是无处不在。尽管许多看门人争辩说,如果他们不使用比Python更难的语言编写代码,那么一个人是否真是软件开发人员,但它仍然无处不在。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net