



- 相关博文
- 最新资讯
-
基于Spring AI的抽奖系统智能运营助手设计与实现:介绍了一个企业级抽奖系统中AI运营助手的工程化实现方案。该系统在传统抽奖业务基础上,通过集成Spring AI框架和DeepSeek模型,为运营人员提供智能问答、活动草稿生成、通知文案生成等功能。核心创新点包括: 采用Tool Calling机制,将自然语言查询转换为后端只读接口调用,确保数据准确性; 严格权限控制,所有AI操作需管理员身份验证; 完善的熔断机制和审计日志,保证系统可靠性; 配置化管理,支持一键关闭AI功能。
-

- 刘小八
- 昨天
-
-
ZooKeeper是Apache开源的分布式协调服务,主要用于解决分布式系统中的一致性问题。其核心特性包括高可用、强一致性和高性能,采用树形结构的ZNode数据模型,支持四种节点类型(持久/临时节点及其顺序变体)。ZooKeeper集群通过主从架构和ZAB协议实现数据一致性,包含Leader、Follower和Observer三种角色。Watch机制提供事件驱动通知功能,适用于分布式锁、配置中心、服务注册发现等场景。部署时建议使用奇数台服务器(如3/5/7台),通过ZAB协议保证数据一致性,其中Leader
-

- 江晓鱼未暖
- 昨天
-
-
WPF相对于WinForms,是更现代化的架构,在构建复杂、视觉效果丰富、界面精美的应用程序时,具备压倒性的能力。WPF使用矢量图形,可无级缩放并保持清晰。对于有一些3D视觉的项目是更好的选择,WPF原生支持3D、动画、渐变、透明等高级效果,而WinForms实现这些非常困难。注:为了方便演示,本节示例中全部代码在按钮的UI进程中执行的,实际使用时UI线程和后台进程要分开处理。Source(图片来源):这是最重要的属性,用于指定要显示的图片。无论是简单的3D模型查看,还是复杂的3D功能,都是更好的选择。
-
- Bishop077
- 前天
-
-
本文总结了企业级物联网平台技术栈的学习要点,重点阐述了各组件功能定位及协同工作机制。技术架构包含多种数据库(MySQL、InfluxDB、Redis、Neo4j)、通信协议(MQTT)、安全认证(Shiro+JWT)、基础设施(MinIO/Quartz)及分析组件(Kafka/Drools)。核心认知在于:没有单一技术能解决所有问题,需根据数据类型(结构化/时序/关系)和业务场景(实时通信/规则计算/文件存储)选择合适组件。后续需深入理解组件间数据流转,掌握平台整体架构设计思路。
-

- 嘎仔的Coding日记
- 昨天
-
-
1. 检查共享文件夹是否挂载成功(通常在 /mnt/hgfs/ 下)# 如果看到 steam 或你起的名字,说明成功了。在VMware主界面,选中你的虚拟机,点击。# 2. 从共享文件夹复制所有CSV文件。# 2. 上传所有CSV文件到HDFS。你应该能看到6个CSV文件都在列表中。# 应该能看到你那6个CSV文件。# 2. 如果看不到,手动挂载。# 3. 确认文件已复制成功。# 3. 验证文件已成功上传。# 1. 创建本地工作目录。# 1. 创建项目数据目录。(如果正在运行,先关机)
-
- 你管我呢==
- 昨天
-
-
KoiWeave 知识中枢体系是一个解决 AI 开发中知识碎片化和传承问题的解决方案。它通过两个核心技能(koi-weave-wiki 和 koi-weave-dev)构建知识管理闭环:前者负责知识中枢的维护与更新,后者确保微服务开发时加载正确知识并回流新知识。系统采用标准化目录结构和严格的操作流程,使 AI 必须遵循"读历史-写代码-存知识"的规范,实现跨服务的知识同步和防退化。该方案不绑定特定 AI 工具,通过 Git/Markdown 实现知识流动,有效解决了多服务间经验无法共享、设计决策遗忘等问题。
-

- Elcker
- 昨天
-
-
LBPH 的纹理统计EigenFaces 的 PCA 降维FisherFaces 的 LDA 投影。我们不仅弄懂了代码的每一行,更通过实际运行结果直观感受到了它们的优劣与适用场景。在人工智能浪潮席卷的今天,回归经典往往能给我们带来意想不到的灵感。希望本文能成为你探索人脸识别技术的坚实起点,无论是做课程作业、参加竞赛,还是打造一个有趣的智能家居项目,这些知识都将为你所用。文中所有源代码均可在文章内直接复制运行,请替换为你自己的图片路径。如果你觉得本文有帮助,欢迎,你的支持是我不竭的创作动力!
-
一张没有显示输出的矿卡,一张九年前的亮机卡。一块在暗无天日的矿场里燃烧过青春,一块在某个玩家的机箱里安静地老去。它们被从电子垃圾堆里打捞出来,插进同一块主板,接通电源,风扇重新转起。我曾试图让那个为 M4、DGX Spark 们准备量化模型的专用引擎接纳它们,结果换来一阵沉默的拒绝。而最终,是那个从不嫌弃任何硬件的通用运行器,伸出了手。此时此刻,在这两片废弃硅片的深处,一个拥有 2840 亿个参数的大脑正在运行。
-
- laot007
- 昨天
-
-
,不是两个工具的简单叠加,而是一种全新的自动化运维范式:表格优势说明🚀 提效AI 生成配置从小时级降到秒级🛡️ 安全GitOps 保证每一步变更可追溯、可回滚🔄 一致声明式配置 + 持续对账,消除配置漂移📈 可扩展从 1 个服务到 1000 个服务,模式不变适用场景✅ Kubernetes 集群管理✅ 微服务 CI/CD✅ 多环境配置管理✅ 基础设施即代码(Terraform + GitOps)如果你还在手动写 YAML、手动部署、手动回滚——。
-
- 漏洞狂
- 昨天
-
-
本文介绍了利用AI技术自动化生成技术视频的"Codex视频工厂"工作流。该系统通过五个核心模块实现视频生产流水线:Codex负责任务规划与脚本编排,HyperFrames处理HTML动画,OpenAI TTS生成配音,Pixabay Music提供背景音乐,FFmpeg完成音视频合成。文章详细说明了从内容策划、分镜设计、动画制作到音频处理和视频合成的完整流程,并提供了标准化的项目目录结构和关键代码示例。这种自动化工作流特别适合制作时长60秒左右的技术类短视频,能够显著提高视频生产效率,实现一次编排多次复用。
-

- 云栖梦泽在
- 昨天
-
-
本文介绍了Apache Kylin 4.0.4的完整安装配置流程:1)从官网下载安装包并解压;2)配置环境变量(KYLIN_HOME、Hadoop、Hive路径);3)MySQL数据库准备(降低密码强度、创建kylin数据库和用户);4)修改kylin.properties配置文件(设置Zookeeper、Hadoop、MySQL元数据存储等参数);5)将MySQL驱动放入bin目录;6)按顺序启动HDFS、YARN、Hive、Zookeeper和Kylin服务。配置重点包括元数据存储切换为MySQL、Sp
-
- lylbzw
- 前天
-
-
本文介绍基于Ansible的Kubernetes 1.28.15离线部署方案,主要特点包括: 提供Gitee源码仓库(https://gitee.com/wxd_ops/k8s-1.28-ansible-offline),包含完整的Ansible playbook和角色配置,但不包含约3GB的离线镜像包等大文件。 支持多种部署模式: 单Master+Worker部署 三Master高可用集群(内置/外部etcd) Worker节点扩容 单独组件部署(Harbor、HAProxy、Keepalived等) 包
-

- 50902636
- 前天
-
-
Elasticsearch插件现已在Grafana 13.0中新增对ES|QL查询语言的实验性支持,用户可通过功能开关启用这一基于管道的现代化查询方式。该集成提供语法高亮、自动补全和错误提示功能,支持日志分析、指标聚合和时间序列可视化等场景。用户只需在配置文件中添加elasticsearchESQLQuery=true即可体验,查询编辑器将支持Lucene、Raw DSL和ES|QL三种模式切换。ES|QL简化了过滤、聚合操作,特别针对时间序列数据优化,性能较QueryDSL提升显著。开发团队鼓励用户试用并







-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-

-
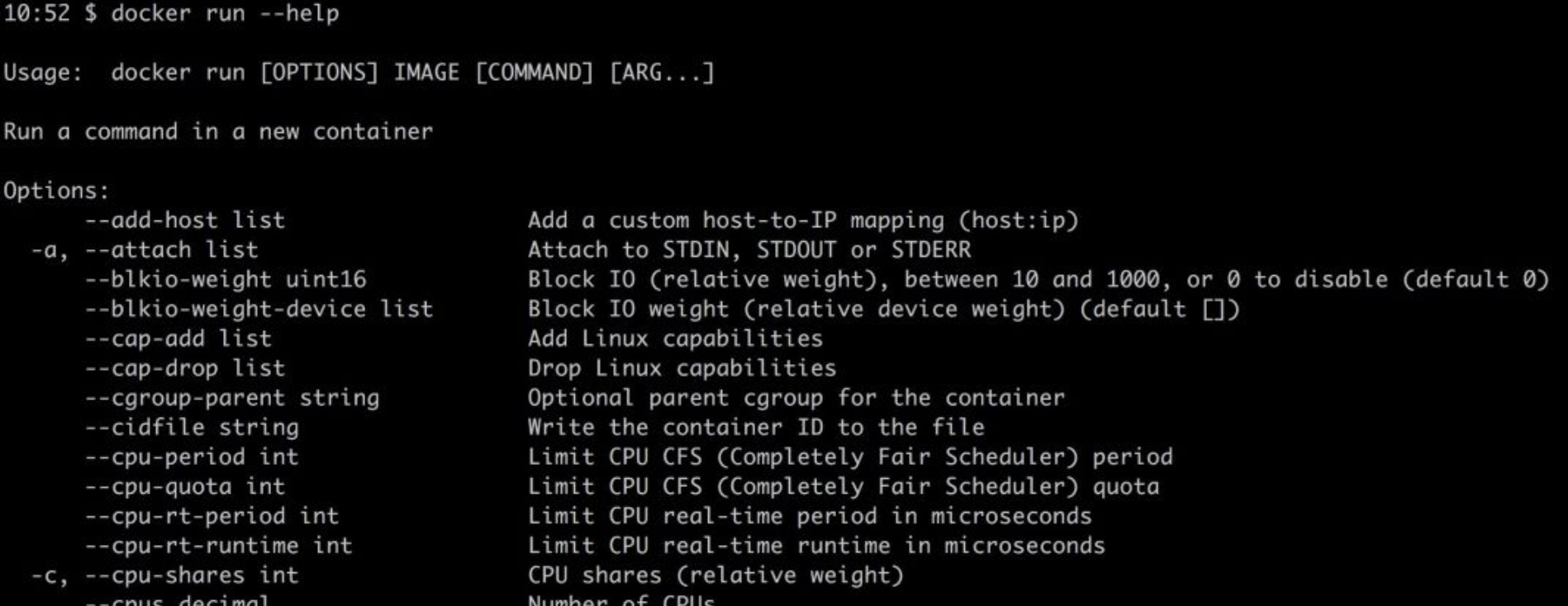
Docker容器已经从一种锦上添花的技术转变成了部署环境的必需品。有时,作为开发人员,我们需要花费大量时间调试或研究Docker工具来帮助我们提高生产力。每一次新技术浪潮来临之际,我们都需要花费大量时间学习。
-

最近,我构建了一个本地开发环境,该环境使用 Docker 进行一些关键的集成测试。 在我要完成这项工作时,我意识到在开始这项工作之前,我没有考虑到这么做的一些意义深远影响,如:
-

Docker 概念很难理解?一文搞定 Docker 端口绑定
作为初级开发人员的你,是不是参加过这样的面试,在面试中面试官希望你准确地回答Docker的工作原理?现今的面试官们希望应聘者能够深入了解8项、10项、甚至更多的技术。其实这有点疯狂。在大学或其他学校里,他们很可能根本不会教你任何关于Docker的知识。然而,如果你真的能够深入了解Docker,那么你就可以从一大群应聘者中脱颖而出。
-

6 个步骤,教你在Ubuntu虚拟机环境下,用Docker自带的DNS配置Hadoop | 附代码
最近,作者整理了一套Hadoop搭建方案。最后的镜像大小1.4G多,使用docker子网,容器重新启动不需要重新配置/etc/hosts文件。 配置过程中参考了如下博客,有些细节问题这些博客里面解释的更加详细。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐
关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net