



- 相关博文
- 最新资讯
-
Kafka-Console是一款轻量高效的Kafka管理工具,专为解决常见操作痛点设计。它提供可视化界面和Linux风格命令行双模式,支持消息查询/发送、Offset查看、Topic管理等核心功能,无需额外依赖即可运行。特色功能包括Tab补全、命令历史、管道过滤等,适合开发、测试和运维人员快速操作Kafka。该工具以"简单直接、开箱即用"为理念,让Kafka管理更高效便捷。下载地址:https://gitee.com/Bree_DU/kafka-console.git
-

- tiaokee
- 昨天
-
-
文章摘要 本文深入探讨了OpenClaw框架的多模型支持架构,详细介绍了如何配置和管理不同AI模型提供商(包括OpenAI、Anthropic、Qwen和Ollama)的认证与集成方式。文章重点解析了openclaw.yaml配置文件的结构,展示了灵活的多模型配置策略,包括主模型选择、备用模型回退机制以及模型路由优化方案。通过OpenClaw的多模型支持,开发者可以实现任务与模型的最佳匹配,在保证性能的同时优化成本,并确保敏感数据的隐私保护。文章还提供了各种模型提供商的具体配置示例和认证方法,帮助开发者快速
-

- 七夜zippoe
- 前天
-
-
Python基础知识摘要(150字) Python是一门易学高效的编程语言,适合数据分析、AI等领域开发。核心内容包括:变量与数据类型(整数、字符串等)、条件语句(if/else)和循环结构(for/while);函数定义(def)实现代码复用;列表和字典管理数据集合;文件读写(open)处理文本;try/except捕获异常确保健壮性;通过import调用模块(如math)扩展功能。示例代码展示了基础语法,完整教程可参考Gitee文档。Python以简洁语法和丰富库支持,成为初学者入门编程的理想选择。
-

- ️学习的小王
- 昨天
-
-
本文基于 C++ 从零自研高并发消息队列,采用MessageMapper-QueueMessage-MessageManager三层架构,实现消息内存管理与磁盘持久化。通过最小临界区细粒度锁设计,仅共享容器查询加锁,IO 与业务逻辑锁外执行,规避高并发锁竞争;内置消息 GC 垃圾回收机制,满足阈值自动整理磁盘文件、清理无效消息、释放空间。同时实现 VirtualHost 虚拟主机层,聚合交换机、队列、绑定、消息四大管理器,完成业务隔离、服务重启消息恢复、交换机 / 队列级联资源清理。配套 GTest 单元测
-

- _F_y
- 昨天
-
-
本文深入解析了Warp AI Agent的上下文管理系统,揭示了其作为Agent"感知系统"的核心地位。文章首先指出上下文管理决定了Agent的智能水平,对比了不同级别Agent的上下文处理能力差异。随后详细剖析了Warp采用的9种上下文源(AIAgentContext)分类体系,包括环境类、执行类、代码类等,以及它们的动态注入机制。 重点介绍了BlocklistAIContextModel状态机的设计,包括其核心结构和关键不变量,特别是Block与SelectedText的互斥原则。文
-

- qcx23
- 昨天
-
-
在从左到右的选择过程中,一旦在某个位置选择了小于n对应位的数字,后面所有位的数字都要取允许集合中的最大值,这样求得的结果就一定是在该前缀下的最大的。过程:第一位要找 <= 3的最大允许数字 -> 最大是2,并且2 < 3,所以第一位直接选2,后面直接全部选允许集合中的最大值, 得到299 < 333,成功。(3)如果没有办法构造一个和n的位数相同、但值小于n的数字,那么就退一步,构造一个比n少一位,且每一位都取允许集合中的最大数字的数。(1)示例1:n = 333,允许数字 = {2,5,9}。
-
- 风筝在晴天搁浅
- 21小时前
-
-
第一,消息中间件的本质是"可靠性的跃升"。Spring Event 是一个优秀的进程内事件机制,但它解决的是"解耦"问题,不解决"可靠投递"问题。引入 Kafka 之后,消息有了持久化载体、有了确认机制、有了重试和死信兜底——这些才是生产环境中不可或缺的能力。第二,迁移成本可以控制在很小范围内。通过合理的分层设计(独立出mq包),业务层的改动仅限于替换一个依赖注入对象和两处调用。原有的事件类和监听器代码可以暂时保留作为对照,待新方案稳定后再清理。渐进式改造的风险远小于推倒重来。第三,技术选型没有银弹。
-
- love8888_cnsd
- 20小时前
-
-
小递查查快递查询API是一款高性能物流跟踪服务接口,提供40+详细物流字段、7大超时预警标记和6大时效分析指标,支持1000+物流商实时查询。接口采用IP认证+签名双重安全机制,通过MD5加密和Base64编码生成数据签名,确保传输安全。请求需POST JSON格式数据,平均响应时间200ms。返回数据包含揽收、转运、派送等全链路信息,以及快递员、网点电话等详细字段,并附带时效分析和超时标记功能。接口严格遵循UTF-8编码规范,提供完整的物流状态监控和异常预警能力。
-
如果某个 Skill 的 description 写的是"审查 Pull Request,检查代码质量和安全问题",匹配度足够高,Claude 就会自动加载并执行这个 Skill。),或者 Claude 判断当前任务匹配某个 Skill 的 description 时,才会加载该 Skill 的完整 SKILL.md 内容、模板文件和脚本。:用户说"帮我检查代码",同时匹配了"代码审查" Skill 和"安全扫描" Skill,Claude 选了一个不合预期的。后,Skill 会在一个隔离的上下文中执行。
-

- ShyanZh
- 15小时前
-
-
本文介绍了如何通过Elastic的Model Context Protocol(MCP)解决开发中日志与代码脱节的问题。MCP作为开放标准,使AI客户端能连接外部数据源,实现生产日志与代码的直接关联。文章以电商搜索应用为例,展示了两种典型开发场景:通过Agent Builder创建工具分析前端筛选器使用情况,以及调试后端500错误。详细说明了工具创建过程、ES|QL查询语法,并提供了性能优化建议,如添加时间过滤参数和服务名参数化。整体架构上,Cursor通过mcp-remote桥接连接到Kibana的MCP
-

- 海兰
- 前天
-
-
本文探讨了AI训练任务与GPU算力梯队的匹配策略。首先将GPU按性能划分为入门级、中级、高端和超高端四个梯队,并分析了关键指标如计算能力、显存和能效比。同时根据任务复杂度将AI训练分为小型、中型和大型三类。文章提出了性能匹配、成本效益和可扩展性三大匹配原则,并给出具体策略:小型任务用入门级GPU,中型任务选中端GPU,大型任务需高端集群。通过实际案例验证了匹配方法的有效性,最终建议开发者按需选择GPU资源,关注云服务和未来技术趋势,以提升训练效率和可持续性。
-

- hwmxrhx
- 昨天
-
-
关于资产负债表类的匹配,系统预设了SGR01和SGR02两个方法,主要区别在于数据的来源范围,SGR01取自ACDOCA和ACDOCU,如果是0F类型的就会直接显示日记账分录(期间是000的除外,这类凭证是年结结转的,系统不再跨年追溯),如果是其他类型就显示合并分录。这里是我觉得SAP还需要优化的地方。基于ICMR的抵消任务中通常将抵销差异细分为交易差异、货币换算差异和其他差异,这在基于重分类抵消任务是无法实现的,基于重分类抵消只知道一个差异总额,很难从合并抵消凭证看出差异的来源,也没有审计线索可言。
-

- S4HANA云
- 昨天
-
-
《数据库与系统优化实战精要》摘要:针对深分页SQL导致的CPU过载问题,核心在于避免全表扫描和回表操作,可通过索引覆盖、ID分页等方案优化。高并发API统计推荐Flink+Kafka实时处理或ELK日志分析方案,前者实时性强后者维护简单。MVCC机制通过事务ID、UndoLog和ReadView实现读写并发控制,但需注意大事务带来的版本链问题。订单超时处理建议采用RedisZSet或RabbitMQ死信队列替代低效的定时任务。秒杀系统要重点防范对象创建过快引发的OOM,需建立从JVM调优到服务降级的立体防御
-

- 逻辑驱动的ken
- 17小时前
-





-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-
-
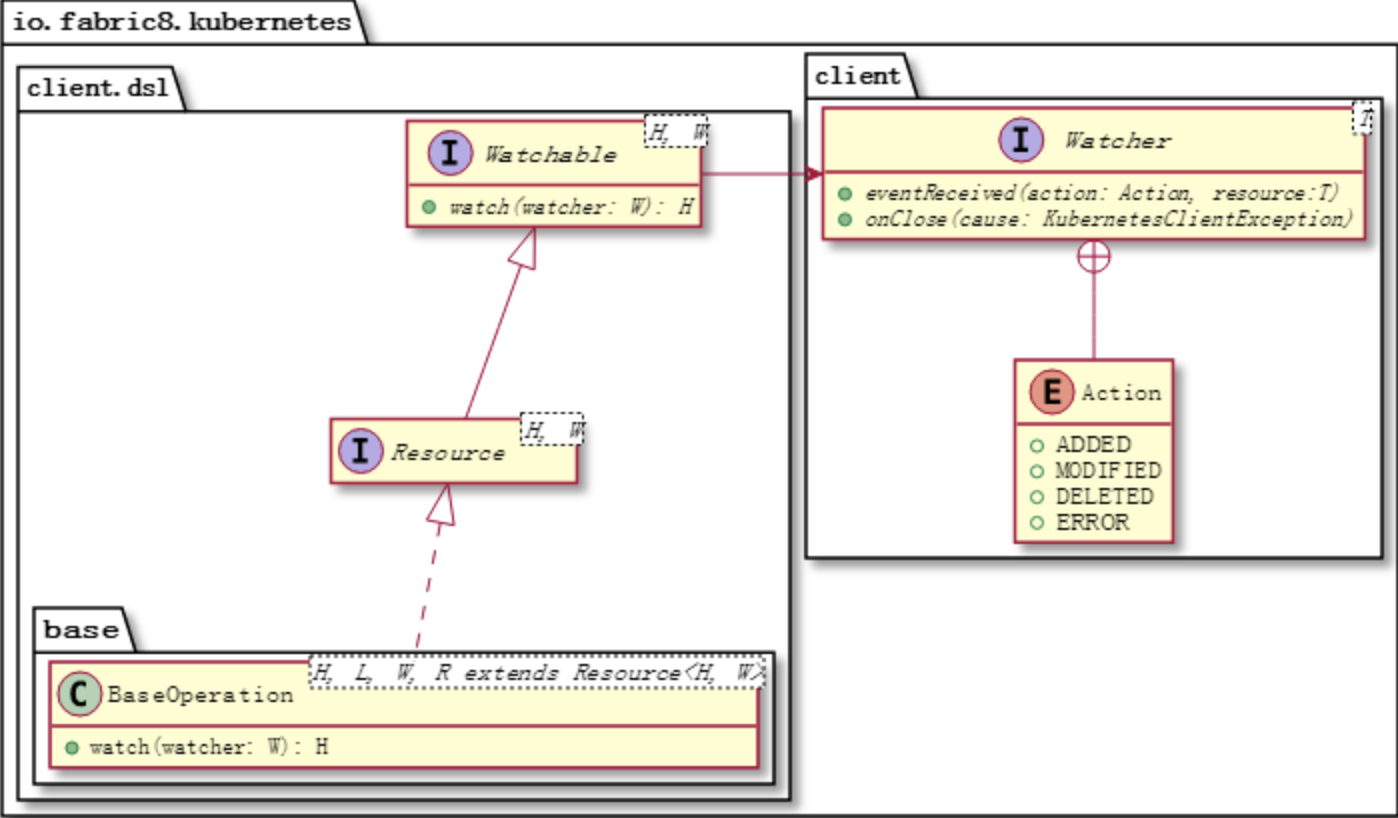
在本文中,我们将开始开发自己的Kubernetes控制器。 技术栈可以是Python、NodeJS或Ruby。因为这个博客被命名为为“ Java极客”,因此选择Java是很正常的。 作为一个用例,我们将实现sidecar模式:每当一个pod被调度时,sidecar pod也会随之被调度。如果将前者删除,则后者也必须删除。
-

果断拿下4000万美元D轮融资,Rancher发力中国本土化与国产化!
2020年3月17日,业界应用广泛的Kubernetes管理平台创建者Rancher Labs(以下简称Rancher)宣布完成新一轮4000万美元D轮融资。
-

什么是 CD 管道?一文告诉你如何借助Kubernetes、Ansible和Jenkins创建CD管道!
CI/CD(CI全名Continuous Integration,持续集成;CD全名Continuous Deployment,持续部署)这个术语常常和DevOps、Agile、Scrum以及Kanban、自动化等其他术语一起出现。
-

-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

-

【光说不练假把式】今天说一说Kubernetes 在有赞的实践
我们为什么选择 Kubernetes?因为 Kubernetes 几乎支持所有的容器业务类型,包括无状态应用、有状态应用、任务型和 Daemonset,Kubernetes 也逐渐成为容器编排领域不争的事实标准。同时,从资源利用率,开发测试运维和 DevOps 三方面出发,会极大的提升人和机器的效率。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐
关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net