



- 相关博文
- 最新资讯
-
文章摘要 本文深入探讨了OpenClaw框架的多模型支持架构,详细介绍了如何配置和管理不同AI模型提供商(包括OpenAI、Anthropic、Qwen和Ollama)的认证与集成方式。文章重点解析了openclaw.yaml配置文件的结构,展示了灵活的多模型配置策略,包括主模型选择、备用模型回退机制以及模型路由优化方案。通过OpenClaw的多模型支持,开发者可以实现任务与模型的最佳匹配,在保证性能的同时优化成本,并确保敏感数据的隐私保护。文章还提供了各种模型提供商的具体配置示例和认证方法,帮助开发者快速
-

- 七夜zippoe
- 前天
-
-
本研究基于某校全寄宿制高中46万余条消费记录,采用"双层筛选模型"从1,730名学生中精准识别出130名核心困难学生(占全校7.5%),并通过孤立森林交叉验证(重叠率43.08%),验证了识别结果的稳健性。从"经验判断"到"数据驱动",从"统一发放"到"分层滴灌",教育大数据正在让校园资助工作变得更精准、更有温度。本文构建的双层筛选模型和三层资助体系,仅是一个起点。我们相信,每一份助学金都应当精准抵达最需要它的学生手中,每一顿早餐都不应因贫困而被迫省去。
-

- _Akira_
- 前天
-
-
在 Elasticsearch 底层,FST(Finite State Transducer,有限状态转换器)是支撑高性能、低内存占用的核心数据结构。ES 之所以能在数十亿 Term 下仍做到毫秒级检索,根本原因就是 FST。很多人知道 ES 快,但不知道为什么快FST + 倒排索引压缩。本文用通俗语言 + 原理图 + 应用场景什么是 FST?它的原理是什么?在 ES 中用在哪里?为什么它这么强?有限状态转换器 → 一种极其节省内存、支持快速前缀查找、有序查询的紧凑字典数据结构。
-

- Seal^_^
- 前天
-
-
背压是 Flink 流处理中保障稳定运行的重要机制。当下游处理速度低于上游生产速度时,压力会沿链路向上传导,迫使上游减速。其本质通常是网络缓冲区不足,导致数据发送受阻。Flink 通过 Credit-Based 流控机制,由下游反馈可用容量,控制上游发送速率,避免内存堆积和链路失控。背压常表现为吞吐下降、延迟升高、Checkpoint 变慢等问题,可通过 Web UI 的 BackPressured 指标识别。常见优化方式包括提升并行度、增加网络内存、使用异步 I/O,以及处理热点 Key等。
-

- 码上滚雪球
- 昨天
-
-
Elasticsearch 的 Enrich 功能通过以下流程实现数据 enrichment:首先,基于源索引(source index)通过 Enrich Policy 提前生成中间缓存索引(enrich index),该缓存索引不支持实时或局部更新,只能全局更新;同时会对缓存索引进行优化以支持高效的反向查询。后续在目标索引(target index)的数据写入、更新或重建过程中,系统会反向查询中间缓存索引,将所需数据补充到目标索引中,从而实现数据的丰富处理。
-

- 逸Y 仙X
- 前天
-
-
SQLiteGo1.5版本发布,专注修复两大核心问题:优化数据显示条数时的异步处理,解决界面卡死问题;改进存储过程运行逻辑,防止SQL编辑器内容被覆盖。本次更新保持软件轻量、本地化特性,适配银河麒麟aarch64环境,不收集用户数据。用户可通过简单卸载安装完成升级。后续将继续优化细节体验,满足国产平台数据库管理需求。
-

- Quincy_Freak
- 前天
-
-
我们做过一个调研,国内90%的企业销售团队都面临3个核心痛点:第一是获客成本越来越高,线上投放一个线索成本从几十块涨到了几百块,但是转化率不到2%,大部分线索都浪费了;第二是销售人力成本高,新人要培训1-3个月才能上手,还经常情绪不稳定、漏跟进线索,离职了还带走客户资源;第三是全链路数据不通,线索在投放平台、客服系统、CRM里来回倒,数据丢失、重复跟进的问题层出不穷。
-

- AI Python 编程
- 前天
-
-
Kafka-Console是一款轻量高效的Kafka管理工具,专为解决常见操作痛点设计。它提供可视化界面和Linux风格命令行双模式,支持消息查询/发送、Offset查看、Topic管理等核心功能,无需额外依赖即可运行。特色功能包括Tab补全、命令历史、管道过滤等,适合开发、测试和运维人员快速操作Kafka。该工具以"简单直接、开箱即用"为理念,让Kafka管理更高效便捷。下载地址:https://gitee.com/Bree_DU/kafka-console.git
-

- tiaokee
- 昨天
-
-
维度一:生命周期持久节点(Persistent)— 客户端断开后,节点依然存在临时节点(Ephemeral) — 客户端断开后,节点自动删除 ← 锁用这个维度二:是否有序普通节点 — 名字就是你指定的,重复创建会报错顺序节点(Sequential)— ZK 自动在名字后面追加递增编号 ← 锁用这个两者结合就是临时顺序节点,比如你创建断开连接后自动删除,且编号全局递增,天然有序。Watch 就是一次性监听客户端 B 对 order0000000001 注册 Watch↓。
-
- 星筏
- 前天
-
-
摘要: 本文详细介绍了Git分支管理与协作开发指南的核心概念和实践方法。主要内容包括:1) 分支合并策略,强调使用--no-ff参数保留分支历史;2) bug修复流程,演示如何通过stash保存工作现场并创建临时分支修复问题;3) 多人协作模式,讲解分支推送、拉取和冲突解决方法;4) 标签管理技巧,展示如何创建、推送和删除版本标签;5) 实用配置建议,包括颜色设置、文件忽略规则和命令别名配置。通过示例,系统性讲解了Git团队协作开发中的关键操作流程和最佳实践,特别适合需要规范Git工作流程的开发团队参考。
-

- 牛奶咖啡13
- 昨天
-
-
摘要:Elastic宣布与AI编码平台Cursor深化合作,推出Elastic插件,将实时可观测性、安全性和搜索数据直接集成到开发工作流中。该插件包含开源Elastic Agent Skills和Elastic Docs MCP服务器,使开发者能在编辑器内查询日志、处理告警和搜索语法,无需切换平台。这一合作旨在通过上下文工程,让AI代理基于实时生产数据进行精准决策,提升开发效率和AI应用可靠性。插件已在Cursor Marketplace上线,支持开发者构建更智能的AI应用。
-
保证顺序有四种方案:单消费者(简单但吞吐低)、按 key 路由到同一队列(局部有序,类似 Kafka partition)、序号窗口(并发处理按序号排序输出)、CompletionService + 序号重排。你用阻塞队列做生产者-消费者模型,生产者按顺序放了 1、2、3、4,结果消费者那边收到的是 3、1、4、2——顺序全乱了。1 号去了慢窗口(办贷款),2 号去了快窗口(存个钱)。2 号比 1 号先办完——队伍是排好了,但出银行的顺序乱了。如果后续流程看"谁先处理完",顺序就是 2、3、1——乱了。
-

- 落魄江湖行
- 前天
-
-
这一平台的诞生,植根于一个跨学科团队近十年的深耕与协作。在评测机制上,DoctorBench首创“2大核心维度(安全性和准确性)+3 项通用维度(交互质量、信息优先级、主动询问)+5 项专项模块(证据与引用、可解释推理、可执行性、个体化适配、情感支持)” 的多维架构,并搭载 “场景自适应权重”——根据不同临床场景的风险等级,动态调整各维度权重,使评分逻辑更贴近真实诊疗决策。“医疗AI的发展是一场关乎人类共同健康福祉的长跑,既需要颠覆式的技术创新和跨学科、跨地域的深度协作,更需要对生命健康的绝对敬畏与坚守。
-

- 财迅通Ai
- 前天
-
-
本文介绍了一个基于PostgreSQL、Kafka和Spring Boot的实时数据变更捕获(CDC)系统实现方案。系统通过Debezium连接器监控PostgreSQL表变更,将变更事件发送到Kafka,再由Spring Boot应用消费这些事件并执行Redis缓存失效操作。 主要内容包括: 环境准备:使用Docker Compose部署PostgreSQL、Redis、Kafka和Debezium Connect等组件 数据库初始化:创建示例表(uav_device、mission、user_info)
-

- Knight_AL
- 前天
-






-

Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统, 使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点。
-
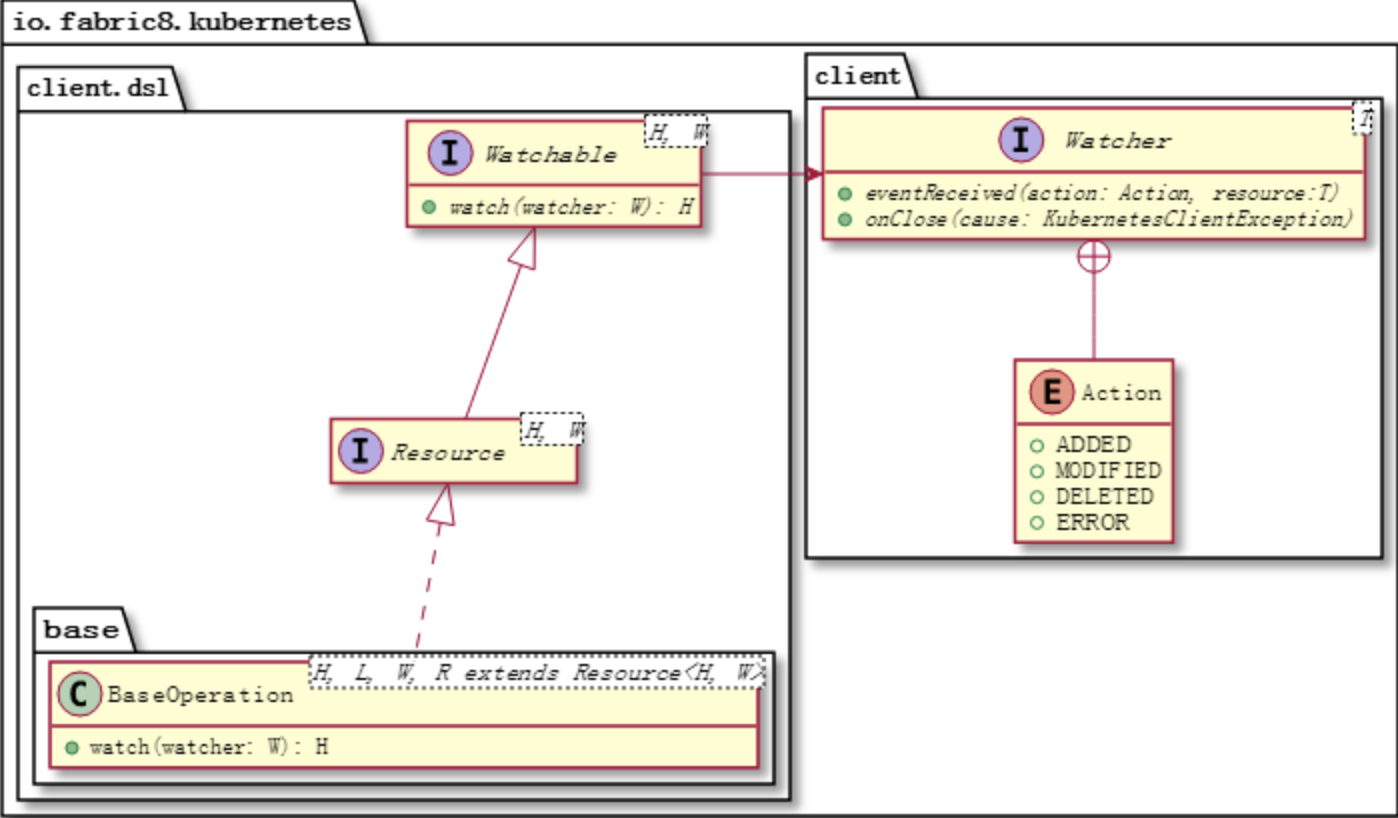
-
在本文中,我们将开始开发自己的Kubernetes控制器。 技术栈可以是Python、NodeJS或Ruby。因为这个博客被命名为为“ Java极客”,因此选择Java是很正常的。 作为一个用例,我们将实现sidecar模式:每当一个pod被调度时,sidecar pod也会随之被调度。如果将前者删除,则后者也必须删除。
-

Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统, 使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点,较之传统的消息中 间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容 错的特性,非常适合大规模消息处理应用程序。
-

-

从 10 年前我开始写第一行 Java 代码至今,一直觉得 null 在 Java 中是一个最特殊的存在,它既是好朋友,可以把不需要的变量置为 null 从而释放内存,提高性能;它又是敌人,因为它和大名鼎鼎且烦不胜烦的 NullPointerException(NPE)如影随形,而 NPE 的发明人 Tony Hoare 曾在 2009 年承认:“Null References 是一个荒唐的设计,就好像我赌输掉了十亿美元”。
-

为了提高 Java 编程的技艺,作者最近在 GitHub 上学习一些高手编写的代码。下面这一行代码(出自大牛之手)据说可以征服你的朋友,让他们觉得你写的代码很 6,来欣赏一下吧。
-

最近,Jrebel公布了一份2020 Java生态系统报告,这份报告主要关注开发人员在开发过程中使用的技术。
-

别再用那些已经淘汰的技术了!2020 年 9 大顶级 Java 框架出炉!!
诞生于1995年的Java,目前已在134,861个网站上广泛使用,包括ESPN、SnapDeal等。在其24年的成长史中,Java已经证明了自己是用于自定义软件开发的顶级通用编程语言。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐
关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net