



- 相关博文
- 最新资讯
-
本系统设计与实现了基于Python的网络小说数据可视化平台,旨在为用户提供一个集小说阅读、互动交流、智能推荐与个性化管理的综合性平台。用户可以通过平台浏览热门小说、查看详细信息、参与论坛讨论,并获得基于历史行为的个性化推荐。此外,系统集成了数据可视化功能,通过图表展示小说的阅读趋势、评论热度等关键数据,增强了用户体验。管理员则可以通过后台管理功能有效地管理小说内容、用户行为、举报记录及论坛互动等,确保平台的正常运营与内容的规范性。
-

- java李杨勇
- 前天
-
-
本文针对前端大数据导出导致Chrome内存崩溃的问题,分析了原因并提出5种优化方案:分批次导出、Web Worker多线程处理、轻量级CSV导出、后端生成文件以及浏览器兼容性调整。其中分批次导出和Web Worker方案能有效降低内存占用,CSV导出适合简单数据场景,后端生成是处理超大规模数据的理想选择。每种方案均附代码示例,开发者可根据数据量级和系统架构灵活选用,兼顾性能与兼容性。优化后即可实现百万级数据的安全导出,避免浏览器崩溃。
-

- 码农阿豪@新空间
- 前天
-
-
(1)开发者提交代码开发者从公共代码库或本地环境中提取代码进行开发。(2)推送到 Gerrit开发者将修改后的代码推送到 Gerrit,进入审核流程。(3)通知审核者Gerrit 通知项目的所有审核者,提醒他们有新的提交需要审核。(4)审核者进行审核审核者会查看提交的代码,并决定是否通过审核。在审核过程中,审核者可以添加评论。(5)状态检查审核者检查代码是否符合标准,如果符合,则标记为“code looks good”并添加评论。(6)验证代码。
-

- 物联网设计-妄北y
- 前天
-
-
本文聚焦 Kafka 集群基础环境搭建。内容包括创建 3 台 CentOS 虚拟机并配置静态 IP 与主机名,通过 Oracle 镜像安装 JDK 8、华为云镜像安装 Hadoop 3.1.3(Hadoop 为可选生态依赖),利用 scp、rsync 实现文件拷贝与差异更新,编写 xsync 集群分发脚本提升同步效率,以及通过生成 RSA 密钥对配置 SSH 免密登录实现节点间无密码通信。同时包括安装Kafka及启动
-

- TCChzp
- 前天
数据错误 -
-
scala编程运行spark报错:Exception in thread “main“ java.lang.ClassNotFoundException: scala.math.Ordering$Re
我的pom.xml文件导入依赖的版本为。用2.12.15版本的scala就行。-

- abdgh123456
- 前天
-
-
NoSQL数据库作为关系型数据库的重要补充,针对不同场景需求分为四大类型:1)K-V存储(如Redis),高效处理复杂数据结构但事务支持有限;2)文档数据库(如MongoDB),提供灵活的无schema存储;3)列式数据库(如HBase),优化大数据分析的I/O效率;4)全文搜索引擎(如Elasticsearch),实现毫秒级文本检索。各类NoSQL数据库分别解决了关系型数据库在数据结构、扩展性、大数据处理和全文搜索方面的短板,实际应用中需根据业务需求选择合适的数据库组合(Not Only SQL),构建高
-

- 佩奇的技术笔记
- 前天
-
-
本文介绍了Elasticsearch中的聚合查询功能,主要包括指标聚合和桶聚合两种类型。指标聚合用于计算数据的最大值、最小值、平均值等统计指标,而桶聚合则用于对数据进行分组统计。文章通过实际案例演示了terms聚合和sum聚合的组合使用,展示了如何对商品销售数据进行分组并计算每组的销售总量。此外还介绍了max和min聚合的基本用法。作者在学习过程中结合了个人经历,将聚合查询与SQL中的group by和聚合函数进行类比,并表达了将其应用于SpringBoot项目的期待。文末提供了详细的DSL查询示例和结果截
-
- 关沐吖
- 昨天
数据错误 -
-
配置jdk,暂时只在master上边操作,后续直接复制过去就行。
-
基于上述的两点,从 Spark 1.6 开始出现 DataSet,作为 DataFrame API 的一个扩展,是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换,结合了 RDD 和 DataFrame 的优点,至 Spark 2.0 中将 DataFrame 与 DataSet 合并。Spark SQL 的核心是一个叫做 Catalyst 的查询编译器,它将用户程序中的 SQL/DataFrame/Dataset 经过一系列的操作,最终转化为 Spark 系统中执行的 RDD。
-

- zh_19995
- 昨天
-
-
摘要 该项目为社区老年人开发了一个在线学习平台,采用Spring Boot、MySQL、Redis等技术栈实现课程管理、直播教学等功能。开发者详细解答了面试中涉及的技术问题:Spring Boot简化配置,MyBatis Plus提升开发效率,Redis缓存热门数据,Kafka处理异步审核任务,RTMP优化直播体验。重点阐述了各技术组件的应用场景、解决方案和性能优化策略,如自定义Redis配置、复杂SQL处理、缓存一致性保障等,展现了扎实的技术实践能力。
-

- 程序员岳彬
- 昨天
-








-
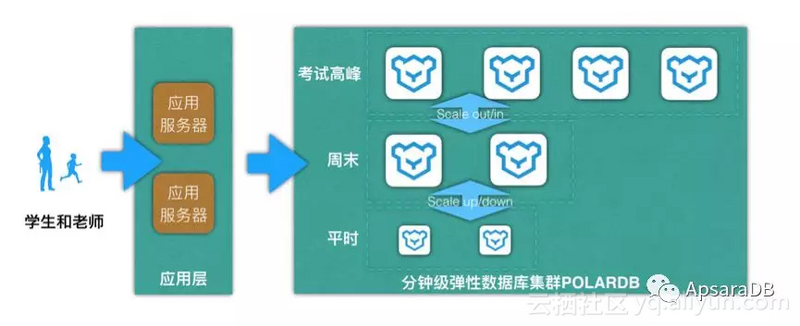
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

在任何以数据为中心的工作中,对SQL有深刻的理解都是成功的关键,尽管这不是工作中最有趣的部分。事实上,除了SELECT FROM WHERE GROUP BY ORDER BY之外,还有更多的SQL方法。你知道的功能越多,操作和查询所需的内容就越容易。
-

你的企业混合云了吗?来看看评估混合云解决方案时要注意的6个原则!
混合云如今很流行。几乎每个IT公司都声称已部署了解决方案,但实际上实现的却很少。相反,它们拥有与多个云实例进行某种程度集成的私有云。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
-

在我们开始之前,作者想先声明一下,本文并非要从两者中分出一个胜负,所以无论你是哪一方的忠实支持者,都建议你仅客观看待本篇文章。
-

-

-

云应用程序是热门话题。很多时候,我们会遇到像云原生应用程序和云计算应用程序这样的术语。首先,很少有人同时使用这两个术语。但两者之间存在着模糊的界线。云原生和云计算的区别到底是什么呢?为什么它如此重要?让我们来看看!
-

-

最近,Jrebel公布了一份2020 Java生态系统报告,这份报告主要关注开发人员在开发过程中使用的技术。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

超级干货!31 条2020 年最新版 ZooKeeper面试题,先收藏再看
金三银四,虽然受疫情影响,大多数企业还未正式复工,但没有条件,创造条件也要上,许多企业已经开始物色合适的人才了,我们怎么能掉队?趁着在家里,赶紧预习一下面试题,只要一复工,马上就开始“打仗”了!
-

相信对于大部分的大数据初学者来说,一定遇见过Hadoop集群无法正常关闭的情况。有时候当我们更改了Hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
-

这篇分享主要总结了数据从业人员在实践中可能遇到的陷阱与缺陷。跟其他新起的行业一样,数据科学从业人员需要不停的去考虑现在,考虑未来;需要不断的斟酌工作方法的合理性,正确性。思索不断,才能前行。
-

-

别再用那些已经淘汰的技术了!2020 年 9 大顶级 Java 框架出炉!!
诞生于1995年的Java,目前已在134,861个网站上广泛使用,包括ESPN、SnapDeal等。在其24年的成长史中,Java已经证明了自己是用于自定义软件开发的顶级通用编程语言。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

如今,Python真是无处不在。尽管许多看门人争辩说,如果他们不使用比Python更难的语言编写代码,那么一个人是否真是软件开发人员,但它仍然无处不在。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net