



- 相关博文
- 最新资讯
-
但是可以看到,我们并不能访问,如果要使用 guest 访问,则需要本机访问,才可以,因为从 RabbitMQ 3.3.0 开始,禁止使用 guest 权限通过 除了 localhost 外的访问(当然解除的方法也是有的,这里就介绍啦)之前,我们需要先部署 Erlang 环境,再安装 RabbitMQ 环境(就像运行 Java 程序,需要先安装 JDK~)RabbitMQ 是一套开源的消息队列服务软件,基于 Erlang 语言编写的,因此,在。可以看到,这里的管理界面是十分友好的,易于操作~
-

- JAVA学习通
- 昨天
-
-
作为一名刚接触编程的小白,你是否曾被 "提交代码"" 拉取更新 ""解决冲突" 这些词汇搞得一头雾水?Git 作为目前最流行的版本控制工具,是每个开发者必备的技能。本文将以最通俗的语言,带你从零开始掌握 Git 的核心操作,全程文字引导 + 代码示例,保证零基础也能看懂!分类命令作用示例基础配置配置全局用户名(标识提交作者)git config --global user.name "张三"配置全局邮箱(建议与远程账号一致)本地操作git init初始化本地 Git 仓库git init。
-

- emojiwoo
- 昨天
-
-
RabbitMQ 作为消息中间件来说, 最重要的就是收发消息了, 但是我们在收发消息的时候, 可能会因为一系列特殊情况导致消息丢失 : RabbitMQ 对上面消息丢失的情况进行考虑, 做出了不同的应对措施 : RabbitMQ 向消费者发送消息后, 就会删除这条消息. 但是, 如果消费者处理消息异常, 就会造成消息丢失. 为了解决消息在 Broker 和 消费者之间问题 RabbitMQ 推出了消息确认.消费者在订阅队列时, 可以指定 autoAck 参数, 根据这个参数设置, 消息确认机制可以分为两种
-

- KIDAKN
- 昨天
-
-
特性对 RocketMQ 的适合度一致性模型CP(强一致性)AP(最终一致性)NS 胜出。MQ 路由信息不需要强一致。可用性选举期间不可写永远可写可读NS 胜出。高可用是 MQ 的生命线。架构复杂,有状态,需选举极简,无状态,对等NS 胜出。简单可靠,运维成本极低。性能写操作需同步,延迟较高纯内存操作,延迟极低NS 胜出。更轻量的心跳和注册机制。功能通用分布式协调为 MQ 元数据管理量身定制NS 胜出。没有多余功能,完美匹配。运维专业,复杂简单,轻量NS 胜出。开箱即用,无需额外维护。
-

- ^辞安
- 昨天
-
-
本文详细介绍了如何利用ZooKeeper实现高可用的主从协调系统。系统通过临时节点实现主节点选举和故障转移,利用持久节点管理从节点注册和任务分配。关键机制包括:主节点通过临时节点选举产生,备份节点监视主节点状态;从节点注册为临时节点并监控专属任务队列;客户端通过顺序节点提交任务。整个过程展示了ZooKeeper的原子操作和事件通知机制如何协同工作,为分布式系统提供可靠协调服务。通过命令行演示,清晰呈现了Znode和Watcher的实际应用场景。
-
- 程序消消乐
- 昨天
-
-
历史代码写法不规范,所有算子都没加 .uid。新增算子时,大部分算子的 OperatorID 与新增前的 OperatorID 存在明显差异。由于 savepoint 是基于历史代码执行的,这就导致从状态恢复时,算子状态分配异常(少分配或者当前算子被分配到了其他算子的状态)。比如 Kafka 算子被分配到了 RocketMQ 算子的状态,当启动任务解析状态时,Kafka默认的 KryoSerializer 无法匹配 RocketMQ 的 PojoSerializer,导致错误并提示。
-

- 19H
- 前天
-
-
RabbitMQ是一款基于AMQP协议的开源消息队列中间件,核心价值在于解耦、异步处理和流量削峰。其架构采用生产者-交换机-队列-消费者模式,通过交换机类型(Direct/Fanout/Topic/Headers)实现灵活路由。Go语言可通过amqp091-go库操作RabbitMQ,支持连接复用、通道管理和消息发布/消费。死信队列(DLX)机制可收集处理失败的消息,通过配置死信交换机和绑定规则实现异常消息的兜底处理,确保消息可靠性。典型应用场景包括异步任务处理、系统解耦和流量控制等。
-
- Cxzzzzzzzzzz
- 前天
-
-
答案要点:Producer: acks=-1、retries;答案要点:Producer、Consumer、Broker、Topic、Partition、Consumer Group、Offset、Zookeeper/KRaft。答案要点:acks=0:只发不管;答案要点:0.9 前:Zookeeper;答案要点:Kafka:高吞吐、大数据流处理;答案要点:同组共享分区;答案要点:副本机制;答案要点:事务性 Producer;答案要点:分区和消费者重新分配;答案要点:分区内有序;答案要点:顺序写磁盘;
-
企业每天产生海量数据(比如电商的交易记录、物流的运输轨迹),但这些原始数据像“刚摘的蔬菜”——带着泥土、可能有烂叶,直接用会“闹肚子”(分析结果错误)。数据仓库的作用是把这些“蔬菜”清洗、加工成“美味菜肴”(高质量分析数据),而维度建模是最常用的“烹饪方法”。本文将聚焦“如何在这道‘烹饪’过程中控制数据质量”,覆盖维度建模的核心环节(维度表设计、事实表构建、缓慢变化维处理),以及数据质量的关键指标(准确性、完整性、一致性)。
-
在大数据数据服务领域,数据的分析和处理对于挖掘有价值的信息至关重要。然而,获取大量有标签的数据是一项耗时且昂贵的任务。半监督学习的目的在于利用少量有标签数据和大量无标签数据,提高学习模型的性能和泛化能力。本文的范围涵盖了半监督学习的基本概念、常见算法、数学模型、实际应用案例以及相关工具和资源的推荐。本文首先介绍半监督学习的核心概念和相关联系,包括其原理和架构的文本示意图与 Mermaid 流程图。接着详细阐述核心算法原理和具体操作步骤,并使用 Python 源代码进行说明。
-
本文介绍了Jupyter Notebook在Docker环境中的部署方法,重点分析了官方提供的不同层次镜像(如datascience-notebook、all-spark-notebook等)的特点及适用场景,其中datascience-notebook最受欢迎(1092星标)。文章详细说明了在群晖NAS的Container Manager中创建容器的步骤,包括端口映射(8881→8881)和存储位置设置(映射本地文件夹到容器内),适用于需要在多种环境中快速部署Jupyter Notebook服务的用户。
-

- Feibo2011
- 前天
-
-
当段的数量过多时,搜索性能会下降,因为每次搜索都必须查询每一个段。然而,合并过程本身是资源密集型的,会消耗大量的 CPU 和磁盘 I/O,这会与索引操作竞争资源,从而拖慢索引速度 2。对这一深度机制的理解,使架构师和开发者能够超越默认设置,通过对索引速度、数据持久性和搜索延迟之间的权衡做出有意识、明智的决策,从而在 Elasticsearch 上构建出复杂、高性能且可靠的系统。是一个将当前保留在内存索引缓冲区中的文档写入到一个新的、不可变的磁盘文件系统缓存中的 Lucene 段的过程 2。
-
- ponnylv
- 昨天
-









-

-

医疗保健、零售、金融、制造业……一文带你看懂大数据对工业领域的影响!...
随着大数据技术的兴起,工业领域在很大程度上发生了变化。智能手机和其他通讯方式的使用迅速增加,使得每天都能收集大量数据。以下是大数据对工业领域的影响。
-

2020年边缘计算最新前沿报告:如何与核心云、5G、AI协同?如何打造新业态和部署运营?...
在数字经济的时代浪潮中,作为关键生产要素的数字技术的快速变革已成为新常态。正当人工智能开始崭露头角时,云计算的边缘化延伸趋势又成为了另一个新焦点。
-

-

如今智能经济时代已开启,消费者服务面临升级,企业技术服务的黄金机遇也已到来,我们相信品牌升级之后的京东智联云,未来定将一如既往,利用自身沉淀的能力洞察以及各产业场景中的实战经验,铸造更多“硬核”技术力量服务民生、技术报国,在一线。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

随着云计算,大数据和人工智能技术应用,单靠CPU已经无法满足各行各业的算力需求。海量数据分析、机器学习和边缘计算等场景需要计算架构多样化,需要不同的处理器架构和GPU,NPU和FPGA等异构计算技术协同,满足特定领域的算法和专用计算需求。今天,笔者带大家详细了解下FPGA技术。 FPGA是英文Field Programmable Gate Array简称,即现场可编程门阵列。它是在PLA、PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
-

作为云时代的整合服务商,联想为了加快转型,更是推出了“三级火箭”战略:一级火箭,与专业垂直领域合作伙伴合作,建立智慧数据中心;二级火箭,与微软Azure、VMware、红帽等合作,以及自身在OpenStack方面的自研能力,建立智慧的云世界;三级火箭,建立智慧的行业应用。
-

2020年第一个工作日,“达摩院2020十大科技趋势”发布。这是继2019年之后,阿里巴巴达摩院第二次预测年度科技趋势。 回望2019年的科技领域,静水流深之下仍有暗潮涌动。AI芯片崛起、智能城市诞生、5G催生全新应用场景……达摩院去年预测的科技趋势一一变为现实。科技浪潮新十年开启,围绕AI、芯片、云计算、区块链、工业互联网、量子计算等领域,达摩院继续提出最新趋势,并断言多个领域将出现颠覆性技术突破。
-

随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
-

作为一家年营收超1000亿美元全球化企业,华为有19万员工且多达1023个办公地点,遍布世界范围内170多个国家并横跨运营商、政企和消费者三大领域的业务规模……如此雄厚财力、庞大架构、繁杂业务,有何可愁?自然是对寻找一款能够支撑企业有效增长以及全球化运作的智能工作平台有高度迫切的需求,这就是华为云WeLink的缘起之因。“确实,WeLink在华为云产品序列中绝对算得上是战略级,我们对此投入了很多。”华为云副总裁、联接与协同业务总裁薛浩说。
-

-

今日,华为在北京发布更懂企业的智能工作平台华为云WeLink,并携手合作伙伴成立华为云WeLink生态联盟。 首批加入华为云WeLink生态联盟的伙伴包括(排名不分先后):金山办公、中软国际、致远互联、罗技、华为商旅、红圈营销、合思费控、Coremail论客、芯盾集团、目睹直播、视源股份、喜马拉雅、为知笔记等。
-

今日,华为云在北京发布智能工作平台WeLink。华为云副总裁、联接与协同业务总裁薛浩表示:“华为云WeLink源自华为数字化转型实践,是更懂企业的智能工作平台,具备智能高效、安全可靠、开放共赢三大核心优势,为政企开启数字化办公智能新体验,助力实现数字化转型。”
-

云+X案例展 | 民生类:智领云数据中台为“健康武汉”增砖添瓦
与前一个十年相比,如今企业对大规模应用的需求产生了巨大变化,例如: 在互联网领域内,高度连接的应用在海量数据的情况下对于可靠性、性能以及连接性的要求有了数个数量级的提高; 快速响应商业洞见; 快速响应市场/客户需求; 对于企业来说数据的存储、收集和分析变得至关重要,对前沿科技的技术(机器学习,人工智能)支持变得至关重要。
-

“仙凡共界武陵门,峡刲翠叠溪连瀑”,李白的这首七律将张家界的美景描绘成人间仙境令人无限向往。张家界头顶“世界自然遗产”“国家森林城市”光环,拥有绿水青山的自然资源,具有得天独厚的发展优势。但当地并不满足于此,抢抓新一轮城市发展机遇,着力引领张家界市实现“建设全域覆盖、智能高效的智慧城市”总体目标,加速建成基础设施共建共用,政务数据共享协同,智慧应用国内领先、智慧产业特别是智慧旅游产业重点突破,营商环境优良,极具张家界旅游城市特色和示范引领作用的智慧城市,形成可推广的“智慧张家界新模式”。
-

云+X案例展 | 民生类:纷享销客助力沃得农机构筑智能化、信息化之路
“2004年到2015年,是中国农机行业的黄金十年。”江苏沃得农业机械有限公司(以下简称沃得农机或沃得) 营销副总李文亮对我们说。近年来,随着中国土地流转进程的加快,中国农机的用户群体结构正在发生悄然的改变,从过去的个体用户向专业化合作社转变。而对于整个农机行业来讲,近年来正在向着智能化、信息化发展,这也是沃得未来发展的整体战略性走向。
-
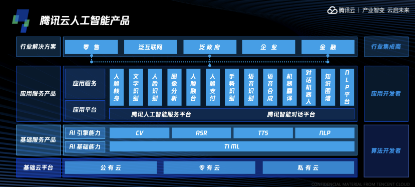
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net