



- 相关博文
- 最新资讯
-
摘要:2026年6月,AI编程领域迎来范式革命——LoopEngineering(循环工程),由ClaudeCode之父Boris Cherny等人提出。该理念主张从"提示词编写"转向"循环设计",将AI编程分为六大组件:自动化触发、工作树隔离、技能沉淀、连接器集成、子Agent协作和外部记忆层。文章详细阐述了完整循环的工作流程、14步构建路线图,并警示三大陷阱:验证债务、理解债务和认知投降。LoopEngineering不是否定提示词,而是将人的角色升级为AI系统架
-

- 逆境不可逃
- 昨天
-
-
hadoop 集群,负责资源的管理和调度组件HDFS 操作:使用 hadoop fs 命令查看文件(查看文件名称、文件的大小等)Hive 中数据的存储格式,了解每一种存储格式的适合存储什么样的类型的数据Linux 中权限的设置,如:使用命令给目录或文件赋予可读可写的权限SSH 生成免密登录使用的密钥MapReduce 过程中,map 阶段、reducer 阶段,采用技术 shuffle 的作用是什么HDFS 包括 namenode、datanode 各自负责什么。
-

- 林间码客
- 昨天
-
-
从map输出开始,传送map输出到Reduce作为输入的过程,对同一个map中输出的键相同的数据先进行整合,减少传输的数据量,并将数据按键排序。NameNode层面:DataNode向NameNode上报块信息,NameNode更新元数据,返回成功响应给客户端。4)流水线写入完成后,如何知道写入成功(从namenode和datanode两种节点)NameNode:管理文件系统命名空间,存储元数据(文件目录树、文件块映射),记。3)将数据加载到对应分区(加载数据既可以从本地加载,也可以从HDFS上加载)
-
- 林间码客
- 21小时前
-
-
Hive 是建立在 Hadoop 之上的数据仓库工具,核心功能是把 SQL 语句翻译成 MapReduce 分布式计算任务。它解决了传统关系型数据库在海量数据场景下的瓶颈问题,适合日志分析、离线报表等批处理场景。Hive 的数据模型包括内部表、外部表、分区表和分桶表。分区按文件夹组织数据提升查询效率,分桶按哈希分散数据便于采样和优化。Hive 使用 MySQL 存储元数据,支持多用户并发访问。Hive 上手容易、可扩展性强,但不支持数据修改和实时查询。一句话:用 SQL 的姿势,玩转大数据。
-
本文探讨了企业微信会话存档在高并发场景下的性能优化策略。针对大规模企业(日活消息千万级)面临的RSA解密CPU瓶颈、I/O阻塞和数据库写入问题,提出了一套异步流式架构解决方案:1)通过拉解分离网关层实现数据拉取与解耦;2)采用分布式解密集群配合RSA密钥缓存优化(命中率提升95%+);3)基于Flink实现实时清洗和风控检测;4)利用ClickHouse+Elasticsearch构建高效存储检索系统。关键创新点包括RSA密钥的本地缓存机制和ClickHouse表结构设计,最终实现解密吞吐量从数百QPS到数
-

- haidy ahmed
- 昨天
-
-
文章摘要 本文对比了四个代码知识图谱项目(Understand-Anything、codegraph、GitNexus、codebase-memory-mcp),旨在解决AI编程代理在大型代码库中盲目搜索的问题。Understand-Anything适合人类开发者理解项目架构;codegraph是轻量级本地索引,优化AI代理效率;GitNexus是功能全面的平台,支持团队级工作流;codebase-memory-mcp则侧重高性能本地代码记忆。项目各有侧重,适用于不同场景,从个人开发到企业级应用。选择需权衡
-

- Toormi
- 昨天
-
-
"效率,不等于效能。这是小鹏汽车在AI转型过程中悟出的一句话,也是当前众多企业在部署AI Agent时面临的共同困境。2026年6月,在亚马逊云科技中国峰会上,小鹏集团AI/Data Platform负责人何瑞邦分享了一组令人震撼的数据:指标 数值AI代码覆盖率 超过70%内部Skills数量 700+连接API端点 400+每日AI协同PR 100+累计工作流执行 14万+核心阶段成功率 >99.7%P0/P1缺陷数 0。
-

- EricZheng95
- 昨天
-
-
回头看这个排查过程,从 Flink 指标面板一路追到 CPU 频率。堆内存和 GC 次数的差异是「高频低利用率」和「低频高利用率」的副产品,不是原因。很多人走到这里就会开始调 GC 参数,试图让两边的内存曲线对齐。但方向已经错了。火焰图差分显示热点代码等比率增长,说明不是某条分支路径在拖后腿。JIT 编译等级一样,JDK 版本一样,应用层和 JVM 层已经排除。最后两行perf stat的输出摆在面前——2.545 GHz vs 3.055 GHz,差距接近 20%。
-

- xpbobcsdn
- 18小时前
-
-
Hive作为大数据领域的经典工具,以“用SQL处理大数据”的核心理念,极大地降低了大数据分析的门槛。它让熟悉SQL的数据分析师、数据库管理员能够直接参与大数据处理,而不必深入学习复杂的分布式编程。当然,Hive并非万能——它不适合实时查询,不适合OLTP场景,表达能力也有其局限。但在海量数据的离线分析、数据仓库建设、日志分析等领域,Hive依然是最成熟、最可靠的选择之一。理解Hive的架构原理、数据模型和适用场景,是每一位大数据从业者的必修课。
-
本文围绕2027年计算机毕业设计选题展开,结合人工智能、大数据、Spring Boot、微信小程序、网络安全、物联网等热门方向,系统梳理适合计算机、软件工程、大数据、人工智能、网络工程等专业学生参考的毕业设计题目。文章从选题趋势、技术难度、项目落地性、论文可写性等角度进行分析,并提供多类规范选题示例,帮助学生避开题目过大、过旧、难实现等常见问题。适合正在准备开题、寻找毕业设计方向、需要源码论文和答辩材料参考的同学阅读。
-

- 柳落青
- 前天
-
-
摘要: 2026年海外社媒营销工具已成为出海企业的核心基础设施,AI自动化、多账号矩阵运营及数据驱动增长成为关键趋势。本文系统梳理了当前主流工具,包括AI内容创作(如ChatGPT、Midjourney)、多平台管理(如Buffer、Hootsuite)、数据分析(如Google Trends、SimilarWeb)及自动化工具(如Zapier),并针对不同团队规模(个人创作者、独立站、矩阵团队等)提供工具组合建议。重点强调多账号运营需配置代理IP(如IPFoxy)防关联,AI内容需人工优化以避免限流。最终
-
- 跨境牛马哥
- 前天
-









-

-

-

2020年边缘计算最新前沿报告:如何与核心云、5G、AI协同?如何打造新业态和部署运营?...
在数字经济的时代浪潮中,作为关键生产要素的数字技术的快速变革已成为新常态。正当人工智能开始崭露头角时,云计算的边缘化延伸趋势又成为了另一个新焦点。
-

-

根据《哈佛商业评论》的说法,数据科学家是21世纪最性感的工作。在现在这个大数据的世界中,数据科学家们用AI 或深度学习方法来发掘宝贵的商业见解。
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

2020年第一个工作日,“达摩院2020十大科技趋势”发布。这是继2019年之后,阿里巴巴达摩院第二次预测年度科技趋势。 回望2019年的科技领域,静水流深之下仍有暗潮涌动。AI芯片崛起、智能城市诞生、5G催生全新应用场景……达摩院去年预测的科技趋势一一变为现实。科技浪潮新十年开启,围绕AI、芯片、云计算、区块链、工业互联网、量子计算等领域,达摩院继续提出最新趋势,并断言多个领域将出现颠覆性技术突破。
-

12月23日下午,“AI你—2019亚信科技媒体沟通会”在北京举办,亚信科技(股票代码:01675.HK)执行董事兼CEO高念书,高级副总裁兼公共与政府事务中心总经理陈武,副总裁兼CTO欧阳晔博士,副总裁兼战略与市场中心总经理王力平,与数十位来自党政、财经、IT行业和大众等主流媒体的记者编辑共聚一堂,就亚信科技近年来转型创新成果及未来五年的战略规划等展开深度沟通交流。大家踊跃发言,深度互动,共商发展,共期未来。
-

今日,华为在北京发布更懂企业的智能工作平台华为云WeLink,并携手合作伙伴成立华为云WeLink生态联盟。 首批加入华为云WeLink生态联盟的伙伴包括(排名不分先后):金山办公、中软国际、致远互联、罗技、华为商旅、红圈营销、合思费控、Coremail论客、芯盾集团、目睹直播、视源股份、喜马拉雅、为知笔记等。
-

-

机器人技术大提升:NVIDIA为构建自主机器统一平台树立里程碑
近日,NVIDIA发布了全新版本Isaac软件开发套件(SDK),为机器人提供更新的AI感知和仿真功能。
-

GTC CHINA 2019 | 黄仁勋发表主题演讲,多项创新技术与合作全面助力 AI 加速落地
近日,NVIDIA 创始人兼首席执行官黄仁勋在中国苏州举办的 GTC China 大会上发表主题演讲,宣布多项创新技术与合作,并阐述了 NVIDIA 如何助力 AI 加速进入大规模应用。
-

近日, NVIDIA发布了一款突破性的推理软件。借助于该软件,全球各地的开发者都可以实现会话式AI应用,大幅减少推理延迟。而此前,巨大的推理延迟一直都是实现真正交互式互动的一大阻碍。
-

-

高速的中子撞击U235原子核,使其分裂成两个原子核,释放出巨大能量,同时产生的几个中子再去撞击其它原子核,形成链式反应,使得核裂变会无限的产生巨大的能量。“将高速的中子比喻成人类的创新思想,原子核就是我们目前的业务,当创新思想碰撞当前业务,就会衍生出新的业务,又激发出更多的创新思路,形成业务的链式创新。”华为云应用平台领域副总裁汪维敏一语道破, 云+AI+5G时代,新技术不断深度融合所产生巨大能量背后的力量。如今,欲快速迈进万物互联世界,数字化转型成为企业发展的必由之路,这亦是我们应对技术需求与商业环境变化的有效措施。
-
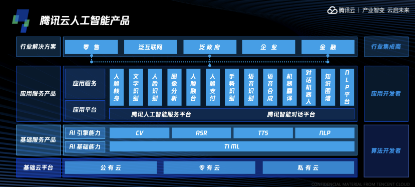
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
-

京东任命周伯文担任京东云与AI事业部负责人 全面负责AI、云计算、IoT三大技术领域
2019年12月6日,京东集团宣布设立京东云与AI事业部,整合原京东云、人工智能、IoT三大事业部的架构与职责,由京东集团副总裁周伯文博士担任负责人,向京东集团董事局主席兼CEO刘强东先生汇报。周伯文博士将带领京东云、人工智能、IoT团队聚焦战略、技术、产品、创新、场景化顶层设计和商业落地,将京东“干锤百炼”的前沿技术与实体经济相融合,致力于实现学术前沿化、技术商业化的目标。
-

12月3日,广州云峰会上,阿里云宣布推出面向混合云场景的CPFS一体机和视觉AI一体机,两款新品具备超高性能、开箱即用等特性,极大降低企业上云的周期和门槛。加上此前推出的POLARDB数据库一体机和蚂蚁mPaaS一体机,阿里云已为客户提供了四款一体机家族产品,集结了云、网、边、端一体化的能力,打破云的边界,让企业能够随时随地全栈、全态、甚至全域上云。
-

12月3日,在阿里云广东峰会上,阿里云联合超图软件、长光卫星、Maxar技术、四维测绘等顶级卫星影像产业链公司发布数字地球引擎,提供开放式的影像数据集、遥感AI能力、丰富的API接口等,在国土资源监管、水利河道治理、自然环境保护和农业估产等领域帮助政府和企业提升效率。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐
关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net