



- 相关博文
- 最新资讯
-
《佳易王宠物医院电子处方软件试用指南》介绍了这款数字化管理工具的核心功能与获取方式。软件提供病历管理、药品检索、电子处方等一体化服务,其特色配方模板功能支持预设常用药品组合,实现一键导入处方,大幅提升工作效率。操作流程包括添加配方分类、预设药品组合和快速导入处方三个简单步骤。软件采用A5标准处方单打印格式,清晰展示诊疗信息。文章提供了免费试用版下载路径:通过文末链接或博客主页获取压缩包,使用常规解压工具即可安装体验。该解决方案特别适合寻求数字化转型的宠物医疗机构,能有效简化工作流程,提升服务质量。
-

- 编程与实例
- 前天
-
-
你是否曾在使用Great Expectations(GX)时遇到棘手问题?当数据验证逻辑失效、集成新数据源失败或性能优化陷入瓶颈时,高效获取技术支持能节省数小时调试时间。本文系统梳理GX官方推荐的3大支持渠道,通过场景化指南帮助你快速匹配问题类型与解决路径,附实战案例与互动模板,确保每个技术难题都能找到对应解决方案。读完本文你将掌握:- GitHub Issues的优先级支持策略与bug报告...
-

- 平荔允Imogene
- 前天
-
-
复制生成后的 ssh key ,通过仓库主页 [管理] -> [部署公钥管理] -> [添加部署公钥],将生成的公钥添加到仓库中。修改尚未加入提交(使用 “git add” 和/或 “git commit -a”)(使用 “git restore --staged <文件>…(使用 “git restore --staged <文件>…总共 3(差异 1),复用 0(差异 0),包复用 0(来自 0 个包)提交为空,但是存在尚未跟踪的文件(使用 “git add” 建立跟踪)” 以包含要提交的内容)
-

- Code Rhythm
- 昨天
-
-
在当今这个信息爆炸的时代,大数据就像一座巨大的宝藏,里面蕴含着无数有价值的信息。我们的目的就是带大家了解2024年大数据领域中最值得学习的5项技术,让大家掌握打开这座宝藏的钥匙。范围涵盖了这5项技术的核心概念、原理、应用场景等方面,帮助大家全面认识和学习这些技术。本文首先会介绍这5项技术的核心概念,用生活中的例子让大家轻松理解。接着讲解它们的核心算法原理,给出具体的代码示例。然后通过项目实战,详细说明这些技术在实际中的应用。还会介绍它们的实际应用场景、推荐相关的工具和资源。
-

- AI算力网络与通信
- 昨天
-
-
图片代码消费者拒绝TTL过期队列满监控DLQ深度分析死信原因检查消费者日志/错误调整TTL或处理逻辑扩容消费者或削峰C/F/G修复代码安全重试消息确认业务恢复。1.独立消费者组DLQ 消费者需与主业务隔离(避免占用正常资源)3.熔断机制若重试成功率 < 10%,暂停重试并发出告警。2.闭环处理:分析 → 修复 → 重试 → 验证。1.监控先行:DLQ 深度 >0 即告警。3.安全重试:渐进延时 + 重试次数控制。4.防止污染:隔离 DLQ 消费者资源。步骤 4:安全重试(3种方案)
-

- iiYcyk
- 昨天
-
-
在前面的一节课程中我们学习了时间语义,其中有一个关键问题:分布式的Flink如何保证时间的统一?系统时间肯定是无法保证的,一定会有偏差,此时Flink引入了水位线的概念,水位线类似于一个逻辑时间,它依赖流中数据的事件事件来推动,从而保证分布式中每个节点都可以保证事件的统一,本文对此进行学习。
-

- 每天五分钟玩转人工智能
- 昨天
-
-
摘要:本文深入探讨了海量数据同步在现代系统中的关键作用,揭示了数据不一致可能导致企业年均1500万美元损失的现实问题。文章对比分析了定时任务、CDC、消息队列等主流同步技术,重点介绍了基于CDC(变更数据捕获)的高效同步方案,该方案相比传统方法吞吐量提升10-100倍且保持毫秒级延迟。通过电商平台案例,详细展示了从MySQL到Elasticsearch和Redis的全量+增量同步实现,包括Debezium配置、Flink流处理、数据一致性校验等核心环节。
-

- 一叶飘零_sweeeet
- 昨天
-
-
你是否遇到过这样的场景?电商日销统计任务:用Spark计算完订单数据后,需要同步更新Hive汇总表、MySQL推荐表和HBase实时查询表;物流轨迹整合任务:从 Kafka 消费轨迹数据,清洗后写入 HDFS 归档、Elasticsearch 检索和 Redis 缓存;金融报表生成任务:从多个数据库抽取数据,计算后同步到数据仓库、BI系统和监管报送系统。这些跨多个异构系统的大数据批处理任务,最头疼的问题是数据一致性。
-
在Elasticsearch中,搜索建议(Search Suggestion)是指根据用户输入的部分文本,返回可能的完整查询词或短语,用于纠正拼写错误或提供联想词。而自动补全(Autocomplete)则是更聚焦于“前缀匹配”的实时提示功能,常用于输入框中动态展示匹配结果。Elasticsearch提供了三种核心的建议器(Suggesters),分别适用于不同场景:| 建议器类型 | 用途 | 数据结构 | 延迟 |termsuggester | 拼写纠错,基于编辑距离 | 倒排索引 | 中等 |
-

- 在未来等你
- 昨天
-









-

相信对于大部分的大数据初学者来说,一定遇见过Hadoop集群无法正常关闭的情况。有时候当我们更改了Hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
-

这篇分享主要总结了数据从业人员在实践中可能遇到的陷阱与缺陷。跟其他新起的行业一样,数据科学从业人员需要不停的去考虑现在,考虑未来;需要不断的斟酌工作方法的合理性,正确性。思索不断,才能前行。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

如今,Python真是无处不在。尽管许多看门人争辩说,如果他们不使用比Python更难的语言编写代码,那么一个人是否真是软件开发人员,但它仍然无处不在。
-

近日,谷歌母公司Alphabet首次公布了谷歌云计算业务的数据,这一举动将云计算行业重新推到了聚光灯下。众所周知,全球云市场竞争激烈,在这场角逐战中,技术与市场能力就是战场上的武器。
-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
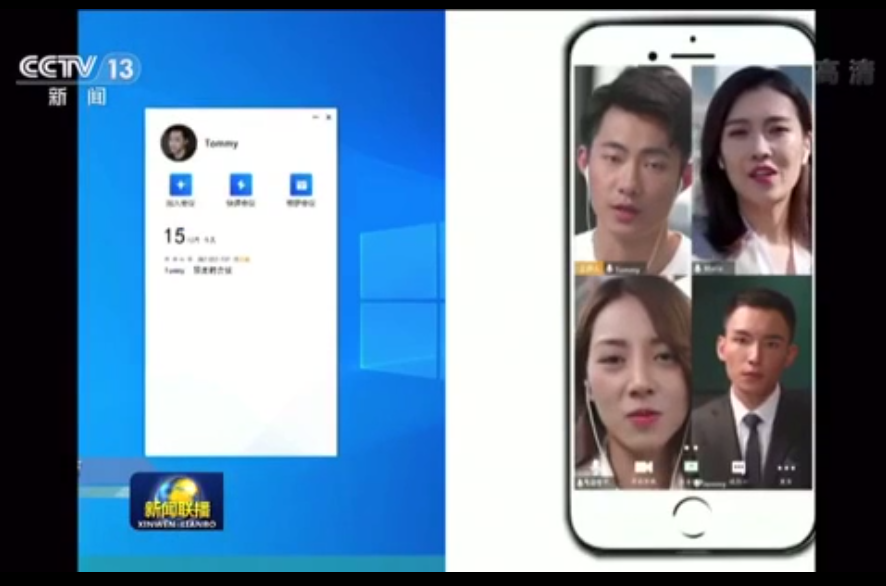
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

伴随5G技术加速落地,云游戏作为5G应用落地的最佳场景,已经成为全球游戏厂商和云服务厂商布局的重要战场。根据艾媒咨询数据显示,2018年中国云游戏市场规模为6.3亿元,而到2023年,市场规模将飙至千亿元。
-

疫情面前,武汉火神山医院快速建立,河南也在建立自己的小汤山医院。与此同时,运营商也在行动,中国移动预计3天就能实现武汉火神山医院5G部署。建好后的医院,必然需要处理大量数据。那么医院是否也需要数据中台?答案就在如下文章中。
-

近年来超融合在国内迎来快速增长,根据IDC最新发布的报告,2019上半年中国超融合市场增长率达56.7%,大幅超越去年同期。Gartner发布的最新报告,到2023年我国超融合市场依旧保持23%的快速增长。超融合覆盖范围正在进一步扩大,不仅服务的客户在向大规模企业扩张,应用场景也从服务器虚拟化、VDI扩展到数据库、私有云等关键业务。
-

企业云计算领导者Nutanix(纳斯达克代码:NTNX)近日宣布,物流行业领导企业嘉里大通 (Kerry EAS) 已采用Nutanix超融合基础架构(HCI)和企业云解决方案,进行企业数据中心的现代化改造。
-

随着云计算,大数据和人工智能技术应用,单靠CPU已经无法满足各行各业的算力需求。海量数据分析、机器学习和边缘计算等场景需要计算架构多样化,需要不同的处理器架构和GPU,NPU和FPGA等异构计算技术协同,满足特定领域的算法和专用计算需求。今天,笔者带大家详细了解下FPGA技术。 FPGA是英文Field Programmable Gate Array简称,即现场可编程门阵列。它是在PLA、PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
-

作为云时代的整合服务商,联想为了加快转型,更是推出了“三级火箭”战略:一级火箭,与专业垂直领域合作伙伴合作,建立智慧数据中心;二级火箭,与微软Azure、VMware、红帽等合作,以及自身在OpenStack方面的自研能力,建立智慧的云世界;三级火箭,建立智慧的行业应用。
-

随着数字化的进程,数据的处理、存储和传输得到了飞速的发展。高带宽的需求使得短距互联成了系统发展的瓶颈。受损耗和串扰等因素的影响,基于铜线的电互联的高带宽情况下的传输距离受到了限制,成本也随之上升。而且过多的电缆也会增加系统的重量和布线的复杂度。与电互连相比,基于多模光纤的光互连具有高带宽、低损耗、无串扰和匹配及电磁兼容等问题,而开始广泛地应用于机柜间、框架间和板间的高速互连。
-

随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
-

刚刚获悉,腾讯在光网络设备和数据中心领域的两大硬件自研设计“OPC-4”和“TMDC”顺利通过OCP(Open Compute Project)审核并正式接受为官方开源贡献。这是腾讯在硬件领域的开源设计首次被OCP官方正式认可,同时,腾讯也成为中国首家对OCP有开源贡献的互联网公司。
-

云+X案例展 | 电商零售类:WakeData助力叁拾加数字化变革
在新零售时代下,各行业都在寻求数字化转型、发展智慧零售模式。而作为新零售的主赛道生鲜行业来说,运营端需要从即时性消费需求出发,加强线下场景布局,提升用户全渠道消费体验。其中水果是生鲜里消费者喜爱程度及消费频次较高的品类,具有很强的互联网基因,但水果行业的数据构成极其复杂,要考虑很多变量,这就需要借助线下大数据构建数字化运营及经营系统。
-

-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net