



- 相关博文
- 最新资讯
-
摘要 文本向量化是构建企业智能知识库系统的关键技术,它将文字信息转化为多维向量,实现语义理解而非简单关键词匹配。典型应用场景包括法律文档关联、电商智能搜索和代码语义检索。通过大模型API(如OpenAI的Embedding模型),可将自然语言文本映射为高维向量空间中的数值表示,如示例中Java代码将中文句子转化为1536维向量。这种技术突破传统搜索局限,使系统能理解用户意图并精准匹配相关内容,为构建智能客服、知识库等企业级AI应用奠定基础。
-

- 幼稚园的山代王
- 23小时前
-
-
Kafka核心原理与应用摘要 Kafka作为分布式消息系统,通过解耦生产者和消费者实现高吞吐量数据传输。其核心架构包括: 生产者/消费者模型:采用发布订阅模式,支持多订阅者同时消费主题数据,生产者通过序列化发送消息,消费者反序列化接收。 横向扩展机制:通过分区(Partition)将主题数据分散到不同Broker节点,并通过副本(Replica)机制保障高可用性,其中Leader副本处理读写,Follower副本同步数据。 集群管理:依赖Zookeeper实现Controller选举和状态监控,Contro
-

- 一入JAVA毁终身
- 16小时前
-
-
(1)将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;: 保存Zookeeper中的数据,注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。= 10: LF初始通信时限,Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)(3)在/opt/module/zookeeper-3.5.7/这个目录上创建 zkData 文件夹。(1)启动 Zookeeper。
-

- 走过冬季
- 昨天
-
-
服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。
-
- 走过冬季
- 昨天
数据错误 -
-
需要在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”,在文件中填入。前提:保证 hadoop102、hadoop103、hadoop104 服务器上 Zookeeper 集群服务端启动。(2)在 hadoop102 的客户端上创建再创建一个节点/atguigu1,观察 IDEA 控制台。(3)在 hadoop102 的客户端上删除节点/atguigu1,观察 IDEA 控制台。测试:在 hadoop102 的 zk 客户端上查看创建节点情况。
-
- 走过冬季
- 昨天
-
-
SQL Server 中 ExternalDataSource 和 LinkedServer 是实现跨数据源访问的两种机制,前者基于 PolyBase 引擎,适合大数据分析,支持 Hadoop、Azure Blob 等数据源,需定义外部表查询;后者基于 OLEDB/ODBC 驱动,适用于传统关系型数据库,支持分布式事务。外部数据源适合只读分析场景,链接服务器适合实时事务操作。配置步骤包括启用功能、创建凭据、定义数据源或链接服务器等,需注意连接权限和性能优化。根据数据规模、实时性需求选择合适的方案,两者可共存
-

- 杜哥无敌
- 昨天
-
- 数据错误
-
2024零售IT调查报告显示,82%零售高管对AI转型持乐观态度,但实际应用率仅39%,主要停留在文档处理等基础场景。
-

- R²AIN SUITE
- 21小时前
-
-
Elasticsearch作为现代搜索引擎的代表,凭借其分布式架构、近实时搜索能力和丰富的查询功能,已成为大数据领域的重要工具。其索引结构设计巧妙平衡了读写性能与可扩展性,而分片机制则实现了数据的分布式处理。尽管存在事务支持有限、资源消耗较高等局限性,但在搜索和分析类应用中,Elasticsearch仍然是许多企业的首选解决方案。随着数据量的持续增长和实时分析需求的增加,Elasticsearch及其生态系统仍在不断演进,未来有望在性能优化、资源效率和易用性方面带来更多创新。
-

- Leaton Lee
- 21小时前
-
-
本文详细介绍了高可用Flink集群的部署方案。架构采用3节点ZooKeeper集群实现JobManager高可用,搭配3个TaskManager节点。环境准备包括主机配置、SSH免密登录和Java安装。部署过程涵盖ZooKeeper集群安装、Flink配置(包括HA设置、状态后端和资源分配)以及集群启动。文档还提供了高可用验证方法、运维管理脚本和常见问题解决方案,并给出安全增强建议。该方案确保集群具备故障恢复能力,支持检查点/保存点机制,保证作业持续运行。建议部署完成后进行完整故障转移测试。
-

- 问道飞鱼
- 昨天
-







-

高速的中子撞击U235原子核,使其分裂成两个原子核,释放出巨大能量,同时产生的几个中子再去撞击其它原子核,形成链式反应,使得核裂变会无限的产生巨大的能量。“将高速的中子比喻成人类的创新思想,原子核就是我们目前的业务,当创新思想碰撞当前业务,就会衍生出新的业务,又激发出更多的创新思路,形成业务的链式创新。”华为云应用平台领域副总裁汪维敏一语道破, 云+AI+5G时代,新技术不断深度融合所产生巨大能量背后的力量。如今,欲快速迈进万物互联世界,数字化转型成为企业发展的必由之路,这亦是我们应对技术需求与商业环境变化的有效措施。
-

2019年7月,城建与云途腾签署了“昆明市轨道交通4号线弱电系统集成项目-车站云软件开发项目采购”合作协议。预计项目建设完成后,“昆明市轨道交通云平台”将被构建成业务可靠、资源融合、兼容开放、数据整合的信息系统平台,提高城轨运营效率、创新乘客服务模式 、优化乘客出行体验,落实中央要求的“高质量转变、实现轨道交通强国”的战略目标。
-

-

近日腾讯在京举办腾讯云媒体开放日,其中在云游戏专场,腾讯研究院研究员俞点和腾讯视频云业务总经理李郁韬分别进行了分享。俞点指出,腾讯从2016年开始便针对云游戏进行技术开发和积累,进入2019年后云游戏迎来爆发,谷歌Stadia、微软也出了Project xCloud等对应布局的产品走上台前,腾讯也拿出了腾讯云云游戏解决方案。
-

异曲同工,“像阿甘一样为了目标拼命追求”也是这家企业的持续坚持的信条。14.9%、10000、1050,作为近日在2019帆软媒体见面会上,CMO袁华杰着重强调的几个彰显里程碑意义的数字熠熠闪光。
-

“仙凡共界武陵门,峡刲翠叠溪连瀑”,李白的这首七律将张家界的美景描绘成人间仙境令人无限向往。张家界头顶“世界自然遗产”“国家森林城市”光环,拥有绿水青山的自然资源,具有得天独厚的发展优势。但当地并不满足于此,抢抓新一轮城市发展机遇,着力引领张家界市实现“建设全域覆盖、智能高效的智慧城市”总体目标,加速建成基础设施共建共用,政务数据共享协同,智慧应用国内领先、智慧产业特别是智慧旅游产业重点突破,营商环境优良,极具张家界旅游城市特色和示范引领作用的智慧城市,形成可推广的“智慧张家界新模式”。
-

分治算法,即分而治之:把一个复杂问题分成两个或更多的相同或相似子问题,直到最后子问题可以简单地直接求解,最后将子问题的解合并为原问题的解。归并排序就是一个典型的分治算法。 在这篇文章中我们将先介绍分治算法的「三步走套路」,然后通过经典的归并排序算法体验一番分治算法的核心,最后再通过真题演练一试身手!
-

“起初阿帕创造阿帕网络。 阿帕网络是空虚混沌。渊面黑暗。 阿帕的灵运行在网络里面。阿帕说:‘要有一个协议。’就有了一个协议。阿帕看它是好的。 阿帕说:‘要有更多的协议。’事就这样成了。阿帕看这是好的。 阿帕说:‘要有更多的网络。’事就这样成了。”
-

云+X案例展 | 民生类:纷享销客助力沃得农机构筑智能化、信息化之路
“2004年到2015年,是中国农机行业的黄金十年。”江苏沃得农业机械有限公司(以下简称沃得农机或沃得) 营销副总李文亮对我们说。近年来,随着中国土地流转进程的加快,中国农机的用户群体结构正在发生悄然的改变,从过去的个体用户向专业化合作社转变。而对于整个农机行业来讲,近年来正在向着智能化、信息化发展,这也是沃得未来发展的整体战略性走向。
-
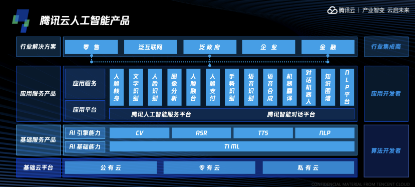
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
-

-

在人类的历史长河中,我们这一代人是最幸运的一代,因为我们生活在一个智慧飞扬的时代。 这个时代最伟大的发明是什么?或许每个人心中都有不同的答案。在小灰看来,这个最伟大的发明有两个,一个是计算机,一个是互联网。 今天,小灰想和大家谈一个比较大的话题:中国的互联网。
-

-
-

互联网公司,可能是存在刻板印象最多的地方; 不管是来自外部的,还是内部的。 人们对互联网公司里的每个工种都有自己“心里的那个模样”; 而实际上,很多时候却不是想的那样...
-

云改变了IT业态和市场格局,催生了应用大发展的时代,企业可以更加专注于构建符合其愿景的、更具生命力的业务创新。全面使用云服务构建软件的时代已经到来,在这个大背景下,云原生的概念被提出并迅速具象化,而以容器为代表的云原生技术,作为提升云化服务能力的最佳选择,也得以快速发展。
-

京东任命周伯文担任京东云与AI事业部负责人 全面负责AI、云计算、IoT三大技术领域
2019年12月6日,京东集团宣布设立京东云与AI事业部,整合原京东云、人工智能、IoT三大事业部的架构与职责,由京东集团副总裁周伯文博士担任负责人,向京东集团董事局主席兼CEO刘强东先生汇报。周伯文博士将带领京东云、人工智能、IoT团队聚焦战略、技术、产品、创新、场景化顶层设计和商业落地,将京东“干锤百炼”的前沿技术与实体经济相融合,致力于实现学术前沿化、技术商业化的目标。
-

正如紫光集团副总裁、紫光云总裁兼CEO吴健所言:“一直以来,紫光云决心打造产业数字引擎,达成为产业赋能的最终目标。在这个过程中就需要打造一个足够强大的‘内核’,紫光云正是以全域、全栈、多场景的云基础平台为产业数字引擎铸‘核’加码。”
-
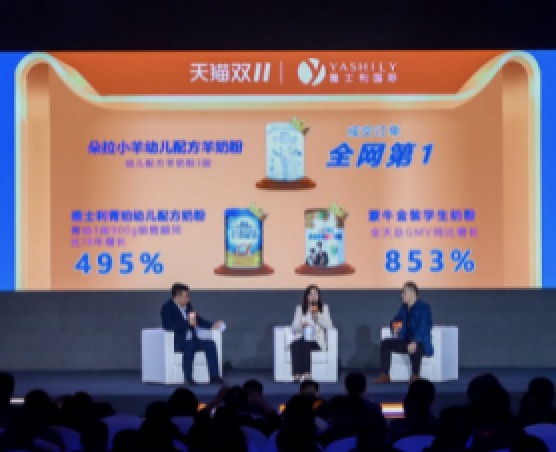
雅士利牵手阿里云实现新零售改造,双11全渠道成交金额同比增长超过200%
12月3日在阿里云峰会·广州站上,雅士利分享了与阿里云的合作,借助数据中台实现新零售改造。在刚刚结束的天猫双11中,雅士利旗舰店整体线上交易同比增长超3倍,旗下羊奶粉品牌“朵拉小羊”50秒成交额超越618全天成交总额,朵拉小羊3段成交订单全网第一,消费者资产实现10倍增长。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net