



- 相关博文
- 最新资讯
-
在现代GPU架构中,固件(Firmware)扮演着至关重要的角色。NVIDIA GPU从Turing架构开始引入了GSP(GPU System Processor)固件,负责管理GPU的初始化、电源管理、内存调度等核心功能。然而,固件加载过程中的性能瓶颈和可靠性问题一直是开发者面临的挑战。**痛点场景**:你是否遇到过GPU驱动加载缓慢、系统启动时间延长、或者固件加载失败导致的设备初始化问题?...
-

- 刘通双Elsie
- 前天
-
-
在现代Web应用开发中,UI组件库的性能直接影响用户体验与开发效率。你是否曾遭遇过数据表格加载延迟、滚动卡顿或交互响应迟缓的问题?本文将通过**实测数据**与**技术解析**,全面对比PrimeVue与主流UI框架的性能表现,帮助开发者在项目选型时做出科学决策。读完本文你将获得:- PrimeVue核心性能优化技术的深度解析- 6个关键指标的跨框架对比数据- 大型数据集下的组件性能调优指南...
-
随着物联网设备(传感器、智能终端)、业务系统(ERP、CRM)、用户行为(网页点击、APP操作)的数据量呈指数级增长(据IDC预测,2025年全球数据量将达175ZB),传统集中式数据采集系统(如单节点日志收集工具)已无法满足“高并发、低延迟、抗故障”的需求。本文聚焦分布式数据采集系统的架构设计,覆盖从数据源接入到数据落地存储的全流程,适用于物联网、日志分析、用户行为追踪等典型场景。本文从“为什么需要分布式”入手,用“快递分拨”的生活案例解释核心概念;接着拆解分层架构设计(采集层→传输层→存储层→处理层)
-

- AI应用开发实战派
- 昨天
-
-
大数据时代,大家都在说“数据是石油”——但未经处理的原始数据,更像“埋在地下的原油”:混着泥沙、杂质,直接烧会呛人,必须提炼才能用。帮你理解数据架构是如何搭建“数据提炼工厂”的;教你用数据质量管理把“脏数据”拦在工厂外;学会用数据处理把“原油”变成“汽油”(有用的信息)。范围覆盖:从数据采集到应用的全流程,重点讲“质量管控”和“处理逻辑”。故事引入:用超市老板的烦恼,类比大数据的“脏乱差”;核心概念:把“数据架构、质量管理、数据处理”翻译成超市术语;原理算法。
-
- AI应用开发实战派
- 昨天
-
-
在现代GPU计算中,高效的中断处理机制对于系统性能和稳定性至关重要。NVIDIA Linux Open GPU Kernel Modules项目提供了对NVIDIA GPU硬件中断的完整支持,包括传统PCIe虚拟线中断、MSI(Message Signaled Interrupts)和MSI-X(Extended Message Signaled Interrupts)等多种中断模式。本文将深入探...
-
- 管琴嘉Derek
- 前天
-
-
它不会将多行数据聚合成一行,而是为查询的每一行返回一个值。计算时,函数会基于一个与当前行相关的“窗口”(一组行)来进行。OVER()子句是窗口函数的标志,它定义了计算的数据集窗口。当使用了ORDER BY后,默认的窗口是(从分区第一行到当前行)。ROWS: 基于物理行(行的位置)。RANGE: 基于逻辑值(排序字段的值)。: 分区的第一行: 分区的最后一行: 当前行: 当前行之前的 N 行 (ROWS only): 当前行之后的 N 行 (ROWS only): 从当前行的前2行到后1行。
-

- 走过冬季
- 前天
-
-
特性ORDER BYSORT BYCLUSTERED BY (在SELECT中)排序范围全局排序Reducer内部排序Reducer内部排序输出文件数1个(或很少)与Reducer数相同与Reducer数相同性能差(单点瓶颈)好(并行执行)好(并行执行)数据分发无法控制,全部发往一个Reducer需配合控制自动按字段哈希分发排序字段可任意指定可任意指定分发和排序必须是同一字段主要用途小数据量全局排序大数据量分区内排序,需灵活控制分发和排序字段1.建表分桶2. 按同一字段分发并排序。
-
- 走过冬季
- 前天
-



-

-
就在不久前,Mobvista刚刚发布了2019年的财报数据。我们观察到其程序化广告收入已高达22.3亿元,同比增长40.8%;经调整后EBITDA达3.6亿元,同比增长高达19.5%……试想仅仅上市一年,Mobvista在增长放缓的大环境下依然能够取得如此“高光时刻”,可见其发展势头不容小觑。
-

数据库是应用及计算机的核心元素,负责存储运行软件应用所需的一切重要数据。为了保障应用正常运行,总有一个甚至多个数据库在默默运作。我们可以把数据库视为信息仓库,以结构化的方式存储了大量的相关信息,并合理分类,方便搜索及使用。
-

其实“数据湖”的概念由来已久,如果追溯时间大概可以到2011年。如今我们经常提及的数据湖其实可以被认为是一个集中式的安全存储库,用户可以任何规模存储、管理、发现并共享所有结构化和非结构化数据,过程中无需预定义架构。
-

医疗保健、零售、金融、制造业……一文带你看懂大数据对工业领域的影响!...
随着大数据技术的兴起,工业领域在很大程度上发生了变化。智能手机和其他通讯方式的使用迅速增加,使得每天都能收集大量数据。以下是大数据对工业领域的影响。
-

SQL是用于数据分析和数据处理的最重要的编程语言之一,因此SQL问题始终是与数据科学相关工作(例如数据分析师、数据科学家和数据工程师)面试过程中的一部分。 SQL面试旨在评估应聘者的技术和解决问题的能力。因此,至关重要的是,不仅要根据样本数据编写正确的查询语句,而且还要像对待现实数据集一样考虑各种情况和极端情况。
-

数据库连接池和线程池等池技术存在的意义都是为了解决资源的重复利用问题。在计算机里,创建一个新的资源往往开销是非常大的。而池技术可以统一分配,管理某一类资源,它允许我们的程序可以重复的使用这个资源,只有在极端情况下(比如连接池满)才会创建新的资源。
-

随着业务的发展,MySQL数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
-

SQL中有一类函数叫聚合函数,比如count、sum、avg、min、max等,这些函数的可以将多行数据按照规整聚集为一行,一般聚集前的数据行要大于聚集后的数据行。而有时候我们不仅想要聚集前的数据,又想要聚集后的数据,这时候便引入了窗口函数。
-

每当提到区块链一词时,许多人都会将其与比特币等加密货币联系起来。这项技术通过加快交易速度、提供隐私和透明以及其他更多功能,确实改变了虚拟货币的世界。
-

MySQL 狠甩 Oracle 稳居 Top1,私有云最受重用,大数据人才匮乏! | 中国大数据应用年度报告...
科技长河,顺之者昌,错失者亡。在这个技术百态之中,中国专业的 IT 社区CSDN 创始人&董事长蒋涛曾多次在公开活动中表示,开发者是对技术变革最敏感的人群。这不仅源于开发者、工程师创建了助力这个时代蜕变的工具,他们还极具前瞻性地缔造了真实世界之外的虚拟、数字化世界。
-

-

“删库跑路”这个词儿,经常被挂在嘴边当玩笑,是因为大家都知道,一旦真的发生这样的事情,企业损失是无比惨重的。
-

根据《哈佛商业评论》的说法,数据科学家是21世纪最性感的工作。在现在这个大数据的世界中,数据科学家们用AI 或深度学习方法来发掘宝贵的商业见解。
-

不看就亏系列!这里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!| 附代码...
Hadoop 是 Lucene 创始人 Doug Cutting,根据 Google 的相关内容山寨出来的分布式文件系统和对海量数据进行分析计算的基础框架系统,其中包含 MapReduce 程序,hdfs 系统等![它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。]
-

近日,某SaaS服务商/微盟遭遇员工删库跑路,服务器出现大面积故障,一时间让平台上的几百万家商户生意基本停摆。这一事件发生后,不管是厂商还是平台上的用户,都在经历着非常不容易的时刻。
-
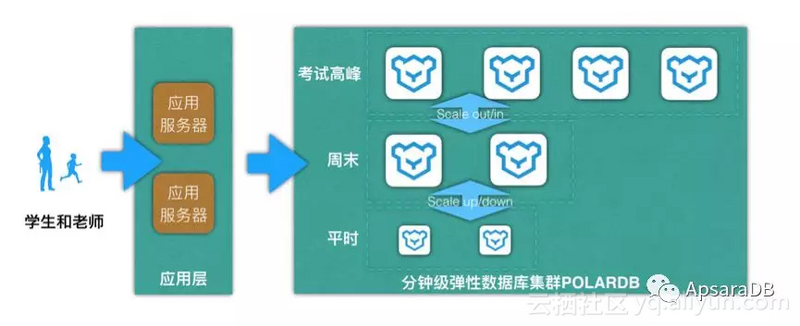
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

在任何以数据为中心的工作中,对SQL有深刻的理解都是成功的关键,尽管这不是工作中最有趣的部分。事实上,除了SELECT FROM WHERE GROUP BY ORDER BY之外,还有更多的SQL方法。你知道的功能越多,操作和查询所需的内容就越容易。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net