



- 相关博文
- 最新资讯
-
本文深入探讨了Apache Kafka的分布式消息系统架构,重点分析了ZooKeeper在集群协调中的关键作用。文章从Kafka的核心组件入手,详细阐述了Broker、Producer、Consumer和ZooKeeper之间的协作关系。ZooKeeper作为Kafka集群的"大脑",负责集群成员管理、Leader选举、配置管理和访问控制,通过层次化命名空间存储元数据信息。Controller机制确保集群状态的一致性管理,包括分区Leader选举和副本重分配。
-

- 励志成为糕手
- 前天
-
-
2、su - Hadoop能成功切换用户,ssh Hadoop@localhost能成功登录,但是在图形化界面登录Hadoop账户,密码是正确的但提示:抱歉,密码不匹配——访问清华大学开源软件镜像站,版本自选,选择“hadoop-版本.tar.gz”的文件下载,最新版本3.4.2没有此文件,建议选择先前版本,否则还需编译。很可能是输入了特殊字符或用的纯数字,如@、12345678,使用sudo passwd Hadoop命令修改密码。3、Hadoop正常在官网下载要一天半,下载慢——
-

- 笨蛋少年派
- 19小时前
-
-
在微服务架构中,跨服务操作的数据一致性是核心难点。Spring Cloud 本身不直接提供分布式事务解决方案,但可通过多种模式结合组件实现事务管理,核心理念是最终一致性而非强一致性。
-

- 苏打 Cracker
- 昨天
-
-
Solon-Gitee插件开发摘要 为解决易支付用户邮箱验证码接收问题,开发者调研后选择使用Gitee的oAuth授权登录方案,并基于Solon框架开发了轻量级插件。该插件已实现Gitee用户授权、获取用户信息和邮箱三大核心功能,采用简洁的配置方式,只需在app.yml中设置clientId等参数即可快速集成。插件提供了完整的API调用示例,包括获取access_token、刷新token、用户信息查询等功能,并为授权回调处理提供了参考实现。项目采用开源方式发布在Gitee平台,未来将根据需求逐步扩展其他A
-

- 记忆旅途
- 昨天
-
-
在之前的学习中,我们往ES的文档库中插入的数据都是我们通过代码从MYSQL批量导入的。但是实际应用场景中这种操作是不合适的。我们的需求是要在商家增删改MYSQL的商品数据时同时更新ES的文档库数据。 首先在MYSQL集群中,主服务器负责接收用户的CUD操作,从服务器负责接收用户的R操作。当主服务器的数据发生改变时,会写入到binlog文件中,再被从服务器读取并同步数据,从而到达MYSQL集群环境下的数据同步。而Canal中间件则会伪装成MYSQL从服务器,接收主服务器的binlog并解析,将其转换
-

- 是小憨憨呀
- 20小时前
-
-
HashMap采用数组+链表+红黑树的形式,键值对存储时通过hash函数计算键的hash值,并定位到数组的位置。当发生键冲突时,会将冲突的键值对存储为链表,当链表长度超过阈值(默认为8)时会转换为红黑树,提升查询效率。:线程的状态包括:新建(NEW)、运行(RUNNABLE)、阻塞(BLOCKED)、等待(WAITING)、超时等待(TIMED_WAITING)和终止(TERMINATED)。:ArrayList基于动态数组实现,支持随机访问,访问速度快,但频繁插入和删除操作效率低;:好了,进入下一轮。
-

- 不会秃头程序员x
- 昨天
-
-
摘要:本教程详细指导如何在Android手机上通过Termux安装运行Claude Code,实现移动端AI编程。从Termux安装配置、Git/Node.js环境搭建,到Claude Code全局安装、国内API中转服务配置(含环境变量设置),手把手解决常见问题。特别针对国内用户提供了API兼容接口配置方案,让没有官方账号的用户也能使用。完成配置后,手机即可变身便携式AI编程环境,随时随地享受AI辅助编码体验。(148字)
-

- haa_y
- 昨天
-
-
随着政府数字化转型的深入推进,各级政府部门积累了海量的业务数据。如何从这些数据中提取有价值的信息,支持科学决策,成为当前政府信息化建设的重要课题。OLAP技术作为大数据分析领域的重要工具,能够帮助政府部门实现多维度、多角度的数据分析和可视化展示。本文旨在探讨OLAP技术在政府部门的应用场景、技术实现路径以及面临的挑战,为政府部门的数字化转型提供技术参考和实践指导。本文首先介绍OLAP的核心概念和技术原理,然后分析政府部门在数据分析方面的特殊需求。接着通过实际案例展示OLAP的应用价值,并提供技术实现方案。
-

- AI 项目管理
- 昨天
-
-
项目描述:基于Spring Cloud Alibaba微服务架构设计高并发点评服务平台,利用 Redis+ RabbitMQ构建高性能核心中间件,实现精准营销策略(如实时推荐)与高并发事务处理,打造端到端分布式解决方案。系统核心功能涵盖:在线订餐、秒杀抢购、社交互动及商户管理的全流程自动化;并支持多终端用户/商户服务、全链路日志追溯与实时业务监控。主要工作:高可用缓存方案: 针对商家信息、热门菜品等高频访问数据,为避免读写冲突导致缓存与数据库不一致,写操作先更新MySQL再删Redis缓存;
-

- 小槑883
- 昨天
-
-
数字经济发展迅速,就业前景广阔。对于求职者而言,我们建议:根据个人兴趣和专长选择适合的岗位方向;系统学习相关技能,并通过实习或项目积累实践经验;理性看待行业认证,将其作为能力的补充而非唯一目标。在数字化转型不断深入的背景下,复合型数字人才将持续受到市场青睐。保持学习态度、紧跟技术趋势,将有助于在职业道路上取得长远发展。
-
- YangYang9YangYan
- 21小时前
-
-
本文介绍了使用PySpark实现单词计数的案例,重点讲解了map、flatMap和reduceByKey三个核心RDD转换算子。
-

- StarPrayers.
- 昨天
-
-
PySpark 是 Apache Spark 的 Python API,它允许开发者使用 Python 语言编写 Spark 应用程序,结合了 Python 的易用性和 Spark 的分布式计算能力,是处理大规模数据的强大工具。
-
- StarPrayers.
- 前天
-









-

-

医疗保健、零售、金融、制造业……一文带你看懂大数据对工业领域的影响!...
随着大数据技术的兴起,工业领域在很大程度上发生了变化。智能手机和其他通讯方式的使用迅速增加,使得每天都能收集大量数据。以下是大数据对工业领域的影响。
-

每当提到区块链一词时,许多人都会将其与比特币等加密货币联系起来。这项技术通过加快交易速度、提供隐私和透明以及其他更多功能,确实改变了虚拟货币的世界。
-

MySQL 狠甩 Oracle 稳居 Top1,私有云最受重用,大数据人才匮乏! | 中国大数据应用年度报告...
科技长河,顺之者昌,错失者亡。在这个技术百态之中,中国专业的 IT 社区CSDN 创始人&董事长蒋涛曾多次在公开活动中表示,开发者是对技术变革最敏感的人群。这不仅源于开发者、工程师创建了助力这个时代蜕变的工具,他们还极具前瞻性地缔造了真实世界之外的虚拟、数字化世界。
-

-

根据《哈佛商业评论》的说法,数据科学家是21世纪最性感的工作。在现在这个大数据的世界中,数据科学家们用AI 或深度学习方法来发掘宝贵的商业见解。
-

相信对于大部分的大数据初学者来说,一定遇见过Hadoop集群无法正常关闭的情况。有时候当我们更改了Hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
-

这篇分享主要总结了数据从业人员在实践中可能遇到的陷阱与缺陷。跟其他新起的行业一样,数据科学从业人员需要不停的去考虑现在,考虑未来;需要不断的斟酌工作方法的合理性,正确性。思索不断,才能前行。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

如今,Python真是无处不在。尽管许多看门人争辩说,如果他们不使用比Python更难的语言编写代码,那么一个人是否真是软件开发人员,但它仍然无处不在。
-

随着云计算,大数据和人工智能技术应用,单靠CPU已经无法满足各行各业的算力需求。海量数据分析、机器学习和边缘计算等场景需要计算架构多样化,需要不同的处理器架构和GPU,NPU和FPGA等异构计算技术协同,满足特定领域的算法和专用计算需求。今天,笔者带大家详细了解下FPGA技术。 FPGA是英文Field Programmable Gate Array简称,即现场可编程门阵列。它是在PLA、PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
-

随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
-

云+X案例展 | 电商零售类:WakeData助力叁拾加数字化变革
在新零售时代下,各行业都在寻求数字化转型、发展智慧零售模式。而作为新零售的主赛道生鲜行业来说,运营端需要从即时性消费需求出发,加强线下场景布局,提升用户全渠道消费体验。其中水果是生鲜里消费者喜爱程度及消费频次较高的品类,具有很强的互联网基因,但水果行业的数据构成极其复杂,要考虑很多变量,这就需要借助线下大数据构建数字化运营及经营系统。
-

云+X案例展 | 金融类:金山云为新网银行重塑金融服务提供云计算动力
作为国内第三家、中西部首家互联网银行,新网银行从创立起,就注定将走上一条与众不同之路。按照新网银行高层的话说,“与其说我们是一家银行,不如说我们是一家拿了银行牌照、专注于大数据驱动的金融科技公司”,这无疑是点出了新网银行的特别之处——依靠大数据风控和金融科技能力来驱动业务运营,实现金融和科技的融合。
-

云+X案例展 | 金融类:荣之联助力君康人寿构建新一代数据中心
近年来,互联网、大数据、云计算和物联网等行业的蓬勃发展,对数据的存储、交换、计算等的应用需求不断增加,使得大数据发展需求下对上游基础设施领域的需求持续旺盛,促进了数据中心(简称“IDC”)需求的不断增加。同时,各国5G技术的发展和商用化的推广又进一步促进了IDC行业爆发增长。未来,IDC行业必将成为物联网、云计算及5G技术的不断完善与发展下又一风口。
-
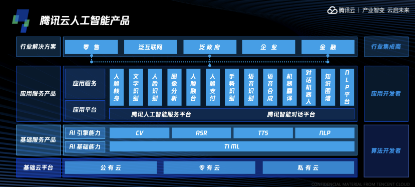
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
-

阿里云提出“云+Fintech”新金融战略 已助上万家金融机构上云
12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

2019年技术盘点云数据库篇(一):UCloud专家谈云数据库:千锤百炼 云之重器
公有云逐渐成为企业运行 IT 设施的新趋势,那么作为企业最核心的系统—数据库,数据上云也成为大数据时代的必然选择。对企业来说,数据可视为其命脉,因此数据迁移上云就意味着将企业“命脉”搬到云平台。事实上,数据上云有两种形式,数据库直接上云或者选择云数据库,而云数据库利用其云原生的优势具备了许多过去数据库产品不具备的优势,包括可靠性、弹性、存储容量以及成本等,正逐渐被更多的企业所接受。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net