



- 相关博文
- 最新资讯
-
本文介绍了一位拥有14年经验的计算机专业毕设指导专家,擅长Java、Python等多种开发语言,覆盖大数据、深度学习、网站开发等领域。文中以《基于Hadoop的电商数据可视化分析系统》为例,展示了完整的毕业设计答辩流程,包括技术选型理由(Hadoop处理40万+数据)、系统架构(前后端分离)、数据采集规范(京东公开数据爬取策略)以及扩展方案。评委对选题实用性和技术可行性给予肯定,建议补充定时脚本和演示视频。
-

- 毕设源码-赖学姐
- 昨天
-
-
Elasticsearch性能优化指南 本文系统介绍了Elasticsearch从基础到高级的优化技术。首先回顾了核心概念如节点、集群、索引和分片。硬件层面建议合理配置JVM内存(不超过32GB)、使用SSD磁盘并优化CPU和网络设置。索引设计方面重点讲解了分片策略、映射优化和生命周期管理。写入性能优化包括批量操作、客户端配置和服务器参数调整。查询优化涉及DSL技巧、索引设计和聚合查询优化。集群层面建议采用专用节点架构,并介绍了分片分配与监控策略。最后还介绍了热温架构等高级优化技巧。通过综合应用这些方法,可
-

- 哥哥还在IT中
- 昨天
-
-
摘要:本文深入探讨了海量数据同步在现代系统中的关键作用,揭示了数据不一致可能导致企业年均1500万美元损失的现实问题。文章对比分析了定时任务、CDC、消息队列等主流同步技术,重点介绍了基于CDC(变更数据捕获)的高效同步方案,该方案相比传统方法吞吐量提升10-100倍且保持毫秒级延迟。通过电商平台案例,详细展示了从MySQL到Elasticsearch和Redis的全量+增量同步实现,包括Debezium配置、Flink流处理、数据一致性校验等核心环节。
-

- 一叶飘零_sweeeet
- 昨天
-
-
本文介绍了在Vue3项目中集成ECharts图表库的完整方案。首先通过安装echarts和vue-echarts依赖,创建基础封装组件ECharts.vue,实现图表初始化、响应式更新和窗口大小自适应功能。随后分别开发了柱状图、折线图和饼图三种具体图表组件,展示了如何使用基础封装组件快速构建不同类型的可视化图表。文章还提供了高级功能扩展建议,如主题切换和加载状态处理,并给出了使用示例和注意事项,包括响应式容器要求、大数据量优化等。该方案为Vue3项目提供了一套完整的ECharts集成路径,可满足常见的数据可
-
- 小菜全
- 昨天
-
-
本手册旨在指导在自建Kubernetes环境中部署一个规模为6分片、数据量约20TB的ClickHouse集群。该部署方案基于2025年最新的ClickHouse和Kubernetes技术栈,充分考虑了大规模数据存储与高效查询的需求。适当的资源配置每个节点至少8核CPU和32GB内存每个节点至少10TB的存储足够的网络带宽可靠的存储基础架构使用SSD存储热数据实施存储分层策略定期验证备份和恢复流程有效的监控和报警监控系统资源和ClickHouse特定指标设置合理的报警阈值。
-

- 喝醉酒的小白
- 昨天
-
-
本文旨在帮助读者理解Hadoop的核心原理、技术架构及在大数据分析中的实际价值。我们将覆盖Hadoop的三大核心组件(HDFS、MapReduce、YARN),通过生活案例、代码示例和项目实战,解释其如何解决传统数据处理的瓶颈,并探讨其在电商、金融、日志分析等领域的应用。用“图书馆管理”故事引出Hadoop核心概念;解释HDFS(存储)、MapReduce(计算)、YARN(资源管理)的原理及关系;通过词频统计代码示例演示MapReduce工作流程;实战搭建Hadoop环境并运行分析任务;
-

- Golang编程笔记
- 昨天
-
-
将Hive与Hudi集成,能够结合两者优势:利用Hudi的实时数据处理能力增强Hive的数据湖功能,同时借助Hive的SQL查询能力和元数据管理简化Hudi的使用复杂度。Apache Hive是建立在Hadoop之上的数据仓库工具,它提供了类似SQL的查询语言(HQL),允许用户查询和分析存储在Hadoop分布式文件系统(HDFS)中的大规模数据集。这种集成架构既保留了Hive强大的SQL查询能力和元数据管理功能,又增加了Hudi提供的实时数据处理能力,为构建企业级实时数据湖奠定了基础。
-

- AI算力网络与通信
- 前天
-
-
在一个阳光明媚的下午,谢飞机走进了一家知名互联网大厂的面试间,面试官看起来很严肃,而谢飞机满脸自信,准备迎接挑战。:Kafka我知道是个消息队列,可以用来做异步消息处理,但具体怎么和Spring Cloud结合,我还需要研究下。:呃,这个嘛,Spring Boot好像有自动配置功能,可以根据类路径中的jar包和定义的bean来自动配置吧。:哦,这个我知道,有Lambda表达式,还有Stream API,不过我平时用的不多,哈哈。:嗯,这样的设计思路是对的,那在大数据处理方面,你用过哪些工具?
-
- Loyal220
- 前天
-
-
还有很多指令没有写出来的,有的是延伸的用法但用的场景不多,有的是和本文提到的指令相似的,只是有细节的差异,所以不展开说明,防止大家混乱,本文提到的指令也足够(如有魔法就github,没有选择国内的gitee,他们都是远端仓库管理平台,这里我们以github为例:进入github官网GitHub Dashboard,假设你已经注册完毕,点击右上角头像,选择Repositories(仓库)# 将远端仓库指定分支名的内容拉回到本地,类似分支合并,适合需要一次将远程仓库最新代码合并到本地分支的场景。
-

- YAO_1212
- 昨天
-
-
本文介绍了一个基于大数据技术的分化型甲状腺癌复发数据可视化分析系统。该系统采用Hadoop+Spark架构,结合Django和Vue框架,对383例患者15年随访数据进行多维分析。系统实现了热力图关联分析、风险分层可视化等功能,可识别影响复发的13个关键临床病理特征。开发环境包括Python/Java、MySQL数据库及Spark SQL等技术。系统界面展示了丰富的交互式可视化图表,为临床决策提供数据支持。
-

- IT研究室
- 前天
-
-
本文提出了一种基于Apache Spark的中文文本情感分析系统,通过分布式计算框架有效处理大规模文本数据。系统采用分层架构设计,包含数据预处理、特征提取、模型训练和结果输出四个核心模块。实验使用ChnSentiCorp中文数据集,对比了逻辑回归、支持向量机和随机森林三种机器学习算法,其中随机森林表现最佳,准确率达83.7%。研究验证了Spark平台在中文情感分析任务中的可行性,并探讨了未来优化方向,包括引入深度学习方法、扩展多语言支持、实现实时分析等。该系统为中文情感分析提供了高效可扩展的解决方案,在舆情
-

- DreamNotOver
- 昨天
-
-
ELFK(Elasticsearch+Logstash+Filebeat+Kibana)是一套开源的企业级日志管理解决方案。文章详细介绍了ELFK的四大核心组件功能:Elasticsearch负责存储和分析日志数据,Logstash处理数据管道,Filebeat收集日志,Kibana提供可视化展示。同时提供了完整的单机部署流程,包括环境准备、各组件安装配置及验证方法,并给出性能优化建议。ELFK适用于日志集中管理、安全监控、性能分析等场景,具有开源免费、扩展灵活等优势。随着技术发展,ELFK正朝着云原生、A
-

- 今生相伴991
- 昨天
-
-
本文介绍了使用Spack包管理器自动化构建GEOS-Chem、GCHP和HEMCO所需软件环境的方法。主要内容包括:1)安装Spack并进行初始化配置;2)克隆对应模型源码;3)安装并注册GCC编译器;4)构建核心依赖包如ESMF、netCDF等;5)配置环境变量文件。使用Spack能自动解决依赖关系,简化安装流程,避免手动安装错误。文中提供了详细的命令示例和终端输出说明,适用于Linux系统下的环境配置。该方法特别适合需要频繁配置新环境的科研人员使用。
-

- WW、forever
- 前天
-





-

2020年边缘计算最新前沿报告:如何与核心云、5G、AI协同?如何打造新业态和部署运营?...
在数字经济的时代浪潮中,作为关键生产要素的数字技术的快速变革已成为新常态。正当人工智能开始崭露头角时,云计算的边缘化延伸趋势又成为了另一个新焦点。
-

-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

随着云计算,大数据和人工智能技术应用,单靠CPU已经无法满足各行各业的算力需求。海量数据分析、机器学习和边缘计算等场景需要计算架构多样化,需要不同的处理器架构和GPU,NPU和FPGA等异构计算技术协同,满足特定领域的算法和专用计算需求。今天,笔者带大家详细了解下FPGA技术。 FPGA是英文Field Programmable Gate Array简称,即现场可编程门阵列。它是在PLA、PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
-

随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
-

-

云+X案例展 | 民生类:智领云数据中台为“健康武汉”增砖添瓦
与前一个十年相比,如今企业对大规模应用的需求产生了巨大变化,例如: 在互联网领域内,高度连接的应用在海量数据的情况下对于可靠性、性能以及连接性的要求有了数个数量级的提高; 快速响应商业洞见; 快速响应市场/客户需求; 对于企业来说数据的存储、收集和分析变得至关重要,对前沿科技的技术(机器学习,人工智能)支持变得至关重要。
-
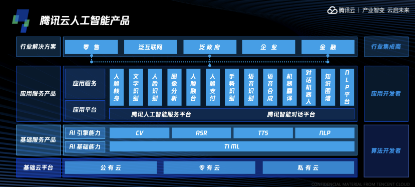
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

京东任命周伯文担任京东云与AI事业部负责人 全面负责AI、云计算、IoT三大技术领域
2019年12月6日,京东集团宣布设立京东云与AI事业部,整合原京东云、人工智能、IoT三大事业部的架构与职责,由京东集团副总裁周伯文博士担任负责人,向京东集团董事局主席兼CEO刘强东先生汇报。周伯文博士将带领京东云、人工智能、IoT团队聚焦战略、技术、产品、创新、场景化顶层设计和商业落地,将京东“干锤百炼”的前沿技术与实体经济相融合,致力于实现学术前沿化、技术商业化的目标。
-

【重磅快讯】T11 2019数据智能技术峰会举办,AI将成为行业颠覆者
11月25日,T11 2019数据智能技术峰会在京举办。TalkingData正式宣布了2019年的最新战略布局,以数据平台为支撑,借助大数据技术积累与人工智能技术创新,聚焦不同行业场景需求,并在选址、预测、个性化推荐等方面进行深入应用,以数据和科技的力量驱动发展。
-

近日主题为“突破与裂变”的2019京东全球科技探索者大会(JDDiscovery)在京盛大开幕,京东集团展示了完整的技术布局与先进而丰富的对外技术服务,对外明确诠释了“以零售为基础的技术与服务企业”的集团战略定位。智能供应链国家人工智能开放创新平台、京东零售全渠道生态平台、京东自动驾驶解决方案、金融数字化解决方案四大智能化平台方案在JDD大会上亮相,将对相关行业的产业升级产生巨大的推动力量。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net