



- 相关博文
- 最新资讯
-
本文深入探讨了Hadoop分布式计算引擎的核心进程机制。文章首先介绍了HDFS、YARN和MapReduce三大组件的进程架构,包括NameNode、DataNode、ResourceManager、NodeManager等关键进程的功能与交互方式。随后分析了Hadoop进程的生命周期管理和通信机制,展示了从系统启动到集群就绪的完整流程。文章还重点阐述了进程监控与调优策略,提供了各核心进程的关键监控指标和资源占用分析。在故障排查部分,详细讨论了常见进程故障的分类与恢复机制。最后,文章介绍了Hadoop的进程
-

- 励志成为糕手
- 21小时前
-
-
本文结合某 GDP 万亿新一线城市智慧交通等 5 个实战项目,拆解智慧城市时空大数据 “规模大、多源异构、实时性高” 三大痛点,详解 Java 分布式存储技术栈(HDFS+HBase+Flink)的选型逻辑、架构设计、核心代码(HBase 表创建、Flink 实时写入、权限控制)及性能优化方案,提供从数据采集到安全合规的全流程落地指南,同步延伸智慧安防、智慧市政场景的泛化应用,解决查询延迟高、存储成本高、数据丢包等实际问题,代码可直接复用。
-

- 青云交
- 17小时前
-
-
可以把 MQ 消息队列想象成一个仓库,采购部门进货之后,把货物放在仓库里,生产部门从仓库中取出零件,并加工成产品,这样类比,可能更帮助我们理解,仓库放的是物品, MQ 放的是消息,仓库负责存储物品,并转发物品,同样的,,比如,在电子商务平台中,如果用户下单后一定时间内未支付,可以使用延迟队列在超时后自动取消订单(可以把 MQ 想象一个仓库,暂时存储了这些消息,到一定时候进行转发~),但这里的消息队列,只不过队列中存放的是消息,消息可以非常简单,也可以非常复杂。MQ 消息队列还可以用于日志处理,例如,
-

- JAVA学习通
- 昨天
-
-
RabbitMQ 作为消息中间件来说, 最重要的就是收发消息了, 但是我们在收发消息的时候, 可能会因为一系列特殊情况导致消息丢失 : RabbitMQ 对上面消息丢失的情况进行考虑, 做出了不同的应对措施 : RabbitMQ 向消费者发送消息后, 就会删除这条消息. 但是, 如果消费者处理消息异常, 就会造成消息丢失. 为了解决消息在 Broker 和 消费者之间问题 RabbitMQ 推出了消息确认.消费者在订阅队列时, 可以指定 autoAck 参数, 根据这个参数设置, 消息确认机制可以分为两种
-

- KIDAKN
- 昨天
-
-
本文介绍了Spark核心组件RDD(弹性分布式数据集)的五大特性及创建方式。RDD是不可变、可分区、并行计算的数据集合,具有五大特性:分区组成、分区计算函数、RDD间依赖关系、键值RDD分区器及最佳计算位置。RDD创建方式包括从集合创建(Java/Scala API)、从文件创建以及基于现有RDD转换。文章还强调RDD不存储数据,采用"计算移动,数据不移动"原则,并提供了具体代码示例说明如何创建RDD及设置分区数。
-

- Lansonli
- 15小时前
-
-
《大数据技术全景指南:2025学习路径与实战建议》摘要: 本文系统梳理了大数据技术体系与学习路径,涵盖六大核心模块:数据采集、存储、计算、建模、治理和应用。针对不同学习阶段(入门到专家)提供详细的学习计划,建议从Linux/SQL基础开始,逐步掌握Hadoop/Kafka生态,最终进阶Flink/Spark和数据湖技术。文章特别强调要避免常见误区:忽视基础SQL、工具原理不扎实、过度追逐新技术等。重点指出大数据技术在电商、金融、智慧城市等领域的核心价值,以及构建"数据采集→处理→可视化"
-

- 大数据狂人
- 昨天
-
-
(共有三台虚拟机node1,node2,node3)其中node1为主节点即为运行namenode和resourcemanager。最后可以在浏览器输入node1:8088进入网页可以更直观的看到我们的yarn是怎么运行的。yarn --daemon start +各进程名称进行启动。至此完成mapreduce,yarn集群完成配置。将我们配置好的文件复制到node2,node3。大家可以自己操作一下,只要细心就没问题!2.配置yarn-site.xml文件。1.配置yarn-env.sh文件。
-

- 霑潇雨
- 昨天
-
-
但是可以看到,我们并不能访问,如果要使用 guest 访问,则需要本机访问,才可以,因为从 RabbitMQ 3.3.0 开始,禁止使用 guest 权限通过 除了 localhost 外的访问(当然解除的方法也是有的,这里就介绍啦)之前,我们需要先部署 Erlang 环境,再安装 RabbitMQ 环境(就像运行 Java 程序,需要先安装 JDK~)RabbitMQ 是一套开源的消息队列服务软件,基于 Erlang 语言编写的,因此,在。可以看到,这里的管理界面是十分友好的,易于操作~
-
- JAVA学习通
- 昨天
-
-
本文介绍了Git项目初始化和SSH连接GitHub的完整流程。首先说明了如何初始化本地Git仓库、配置用户信息、创建.gitignore文件排除编译生成文件,以及首次提交和推送代码到远程仓库的步骤。接着详细讲解了如何从Git中移除已错误提交的文件。文章后半部分重点介绍了SSH连接GitHub的配置方法,包括生成SSH密钥、添加密钥到ssh-agent、测试连接以及修改远程仓库地址为SSH协议的操作。最后还提供了解决网络连接超时问题的建议,即通过配置SSH端口为443来确保连接稳定性。
-

- lzmLi
- 16小时前
-
-
hadoop jar hadoop-mapreduce-examples-3.3.1.jar java类名 程序参数1 程序参数2。6.统计结果保存在输出路径中的part-r-00000文件。4.使用命令将mapreduce程序提交到yarn中执行。在单词计数中程序参数1为输入路径,程序参数2为输出路径。words.txt(由单词组成,用空格隔开)也可以在yarn的可视化网站上查看,更加清晰。3.在hdfs中创建输入路径,和输出路径。2.创建一个数据文件。
-
- 霑潇雨
- 22小时前
-








-

-
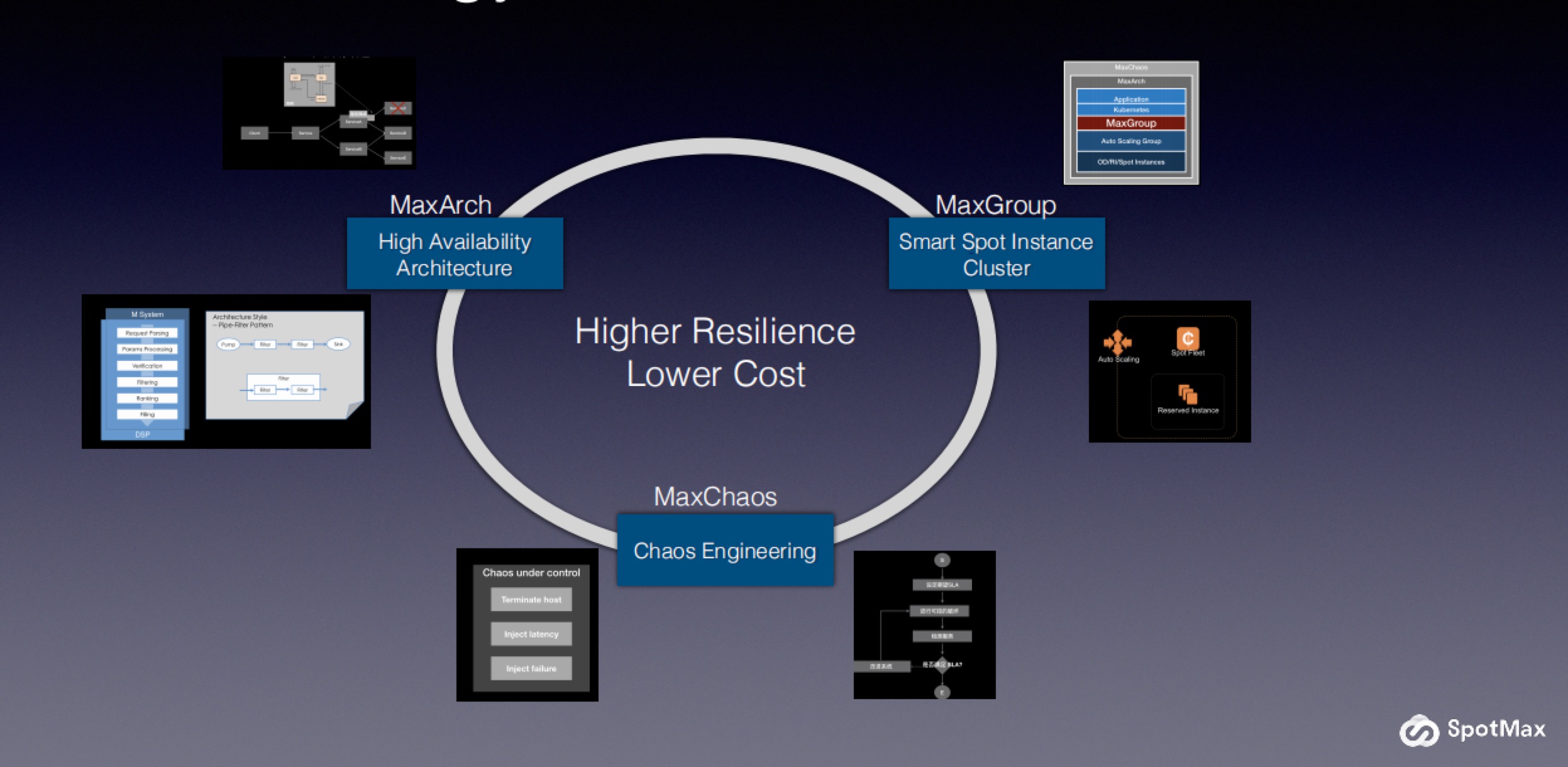
就在不久前,Mobvista刚刚发布了2019年的财报数据。我们观察到其程序化广告收入已高达22.3亿元,同比增长40.8%;经调整后EBITDA达3.6亿元,同比增长高达19.5%……试想仅仅上市一年,Mobvista在增长放缓的大环境下依然能够取得如此“高光时刻”,可见其发展势头不容小觑。
-

数据库是应用及计算机的核心元素,负责存储运行软件应用所需的一切重要数据。为了保障应用正常运行,总有一个甚至多个数据库在默默运作。我们可以把数据库视为信息仓库,以结构化的方式存储了大量的相关信息,并合理分类,方便搜索及使用。
-

其实“数据湖”的概念由来已久,如果追溯时间大概可以到2011年。如今我们经常提及的数据湖其实可以被认为是一个集中式的安全存储库,用户可以任何规模存储、管理、发现并共享所有结构化和非结构化数据,过程中无需预定义架构。
-

医疗保健、零售、金融、制造业……一文带你看懂大数据对工业领域的影响!...
随着大数据技术的兴起,工业领域在很大程度上发生了变化。智能手机和其他通讯方式的使用迅速增加,使得每天都能收集大量数据。以下是大数据对工业领域的影响。
-

SQL是用于数据分析和数据处理的最重要的编程语言之一,因此SQL问题始终是与数据科学相关工作(例如数据分析师、数据科学家和数据工程师)面试过程中的一部分。 SQL面试旨在评估应聘者的技术和解决问题的能力。因此,至关重要的是,不仅要根据样本数据编写正确的查询语句,而且还要像对待现实数据集一样考虑各种情况和极端情况。
-

数据库连接池和线程池等池技术存在的意义都是为了解决资源的重复利用问题。在计算机里,创建一个新的资源往往开销是非常大的。而池技术可以统一分配,管理某一类资源,它允许我们的程序可以重复的使用这个资源,只有在极端情况下(比如连接池满)才会创建新的资源。
-

随着业务的发展,MySQL数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
-

SQL中有一类函数叫聚合函数,比如count、sum、avg、min、max等,这些函数的可以将多行数据按照规整聚集为一行,一般聚集前的数据行要大于聚集后的数据行。而有时候我们不仅想要聚集前的数据,又想要聚集后的数据,这时候便引入了窗口函数。
-

每当提到区块链一词时,许多人都会将其与比特币等加密货币联系起来。这项技术通过加快交易速度、提供隐私和透明以及其他更多功能,确实改变了虚拟货币的世界。
-

MySQL 狠甩 Oracle 稳居 Top1,私有云最受重用,大数据人才匮乏! | 中国大数据应用年度报告...
科技长河,顺之者昌,错失者亡。在这个技术百态之中,中国专业的 IT 社区CSDN 创始人&董事长蒋涛曾多次在公开活动中表示,开发者是对技术变革最敏感的人群。这不仅源于开发者、工程师创建了助力这个时代蜕变的工具,他们还极具前瞻性地缔造了真实世界之外的虚拟、数字化世界。
-

-

“删库跑路”这个词儿,经常被挂在嘴边当玩笑,是因为大家都知道,一旦真的发生这样的事情,企业损失是无比惨重的。
-

根据《哈佛商业评论》的说法,数据科学家是21世纪最性感的工作。在现在这个大数据的世界中,数据科学家们用AI 或深度学习方法来发掘宝贵的商业见解。
-

不看就亏系列!这里有完整的 Hadoop 集群搭建教程,和最易懂的 Hadoop 概念!| 附代码...
Hadoop 是 Lucene 创始人 Doug Cutting,根据 Google 的相关内容山寨出来的分布式文件系统和对海量数据进行分析计算的基础框架系统,其中包含 MapReduce 程序,hdfs 系统等![它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。]
-

近日,某SaaS服务商/微盟遭遇员工删库跑路,服务器出现大面积故障,一时间让平台上的几百万家商户生意基本停摆。这一事件发生后,不管是厂商还是平台上的用户,都在经历着非常不容易的时刻。
-
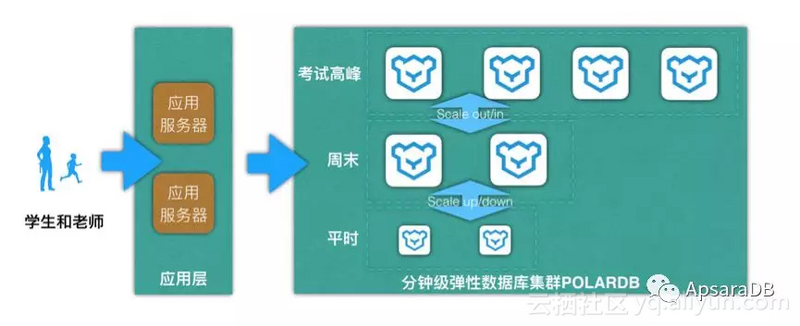
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

在任何以数据为中心的工作中,对SQL有深刻的理解都是成功的关键,尽管这不是工作中最有趣的部分。事实上,除了SELECT FROM WHERE GROUP BY ORDER BY之外,还有更多的SQL方法。你知道的功能越多,操作和查询所需的内容就越容易。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net