



- 相关博文
- 最新资讯
-
本文全面整理了Git常用操作指令,涵盖仓库创建与配置、文件跟踪与暂存、提交操作、分支管理、远程仓库操作、撤销回退、历史查看、标签管理和储藏操作等10大类场景。详细说明了每个指令的具体使用场景和功能,包括git init创建仓库、git add暂存文件、git commit提交变更、git branch分支管理、git push/pull远程操作等核心命令,以及git reset回退、git log查看历史、git stash临时保存等实用操作。是Git版本控制系统的完整参考指南,适合开发人员日常查阅使用。
-

- NiNi_suanfa
- 18小时前
-
-
【摘要】内网Kafka集群无法直接对外提供服务,通过Nginx反向代理实现间接访问时,发现Kafka元数据返回的内网地址导致连接失败。解决方案是:1)Nginx配置TCP代理,为每个broker设置独立端口;2)客户端修改hosts文件,将所有broker域名指向Nginx;3)增加IP白名单控制。该方案虽解决了测试环境问题,但存在维护性差(需手动维护hosts)、扩展困难等缺陷,仅适合临时测试使用。实践过程中深入理解了Kafka通信机制和Nginx流模块的应用。
-

- qq_28053337
- 昨天
-
-
IIKI 2025 聚焦物联网领域的核心技术与应用挑战,涵盖物体识别、大数据的组织与管理、知识驱动的智能决策系统等议题,同时延伸至数字经济与金融科技等前沿方向。第十三届物联网识别、信息与知识国际会议(IIKI 2025)由成都工业学院主办,电子科技大学、立命馆大学、约翰内斯堡大学、北京师范大学、南非大学等协办,将于 2025年10月30日至11月3日在中国成都隆重举行。包括软硬件协同设计、高效模型训练与推理、边缘计算、高性能AI架构等。涵盖知识图谱、语义网络、大数据分析、分布式系统与云平台架构等内容。
-
HBase数据库不同于一般的数据库,如MySQL数据库和Oracle数据库是基于行进行数据的存储,而HBase则是基于列进行数据的存储,这样的话,HBase就可以随着存储数据的不断增加而实时动态的增加列,从而满足Spark计算框架可以实时的将处理好的数据存储到HBase数据库中的需求。从上述返回结果可看到,Hive中包含hive_hbase_emp_table表,HBase中包含hbase_emp_table表,说明Hive与HBase整合成功后,可以在Hive中创建与HBase相关联的表。
-

- 想你依然心痛
- 2025-09-24
-
-
- Server2的高可用参数,开启参数可以提高hiveservers2的1启动速度-->-- Hive数据仓库的数据存储在HDFS上的目录-->-- Hive Server2 的连接host-->-- Hive Server2 的连接端口-->-- JDBC的连接username-->-- JDBC的连接的Driver-->--hive连接数据库URL-->--存储元数据要连接的地址-->-- 元数据储存版权的认证-->或者 quit;-- JDBC的连接密码-->-- 元数据存储授权-->
-

- 心止水j
- 昨天
-
-
本文档部署的是,核心功能是实时收集 Nginx 反向代理服务器的访问日志与错误日志,通过 Kafka 实现日志高可用传输存储,搭配 Flask 模拟业务场景,Celery+Redis 实现定时任务处理,适用于中小型企业日志监控分析需求。组件 版本 核心作用Kafka 3.6.1 分布式消息队列,接收 Filebeat 日志并存储传输。
-
- dalianwawatou
- 11小时前
-
-
本文分享了使用Elasticsearch实现RAG检索的实用经验。作者认为检索不应只依赖向量或关键词,提出了混合检索方案:先用KNN向量检索召回300倍候选,再用关键词匹配确保相关性,通过filter处理权限,最后用BM25精排top10结果。文章提供了详细的JSON查询模板和参数调优建议,包括召回窗口设置(k=300)、权重分配(0.2向量分+1.0文本分)和降级策略(纯文本+权限过滤)。作者强调要避免常见错误,如权限条件误放must、向量维度不匹配等,并建议从质量、性能、稳定性多维度监控检索效果。这套方
-
- YX-zzh
- 12小时前
-
-
当前核心问题是DataNode 进程不稳定(被 SIGTERM 终止)和注册通信失败。优先解决内存溢出或网络 / 配置错误,再通过实时日志定位剩余问题,即可让hadoop03的 DataNode 正常注册到 NameNode。其实多数问题不是内存不够,益处的问题,而是网络问题。当前问题的根源是网卡活跃状态与hosts配置不匹配,通过 “获取活跃网卡 IP → 修正hosts解析 → 验证连通性 → 重启 DataNode” 的步骤,可彻底解决hadoop03。
-

- 翻斗花园龙爷爷
- 16小时前
-
-
基于 DataStream API 快速实现一个“可上线的”流式 ETL,理解 map/flatMap、keyBy/聚合、有状态处理(ValueState)、连接流(Connected Streams),并给出性能与生产化注意事项。
-

- Hello.Reader
- 昨天
-













-

-

医疗保健、零售、金融、制造业……一文带你看懂大数据对工业领域的影响!...
随着大数据技术的兴起,工业领域在很大程度上发生了变化。智能手机和其他通讯方式的使用迅速增加,使得每天都能收集大量数据。以下是大数据对工业领域的影响。
-

每当提到区块链一词时,许多人都会将其与比特币等加密货币联系起来。这项技术通过加快交易速度、提供隐私和透明以及其他更多功能,确实改变了虚拟货币的世界。
-

MySQL 狠甩 Oracle 稳居 Top1,私有云最受重用,大数据人才匮乏! | 中国大数据应用年度报告...
科技长河,顺之者昌,错失者亡。在这个技术百态之中,中国专业的 IT 社区CSDN 创始人&董事长蒋涛曾多次在公开活动中表示,开发者是对技术变革最敏感的人群。这不仅源于开发者、工程师创建了助力这个时代蜕变的工具,他们还极具前瞻性地缔造了真实世界之外的虚拟、数字化世界。
-

-

根据《哈佛商业评论》的说法,数据科学家是21世纪最性感的工作。在现在这个大数据的世界中,数据科学家们用AI 或深度学习方法来发掘宝贵的商业见解。
-

相信对于大部分的大数据初学者来说,一定遇见过Hadoop集群无法正常关闭的情况。有时候当我们更改了Hadoop内组件的配置文件后,必须要通过重启集群来使配置文件生效。
-

这篇分享主要总结了数据从业人员在实践中可能遇到的陷阱与缺陷。跟其他新起的行业一样,数据科学从业人员需要不停的去考虑现在,考虑未来;需要不断的斟酌工作方法的合理性,正确性。思索不断,才能前行。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

如今,Python真是无处不在。尽管许多看门人争辩说,如果他们不使用比Python更难的语言编写代码,那么一个人是否真是软件开发人员,但它仍然无处不在。
-

随着云计算,大数据和人工智能技术应用,单靠CPU已经无法满足各行各业的算力需求。海量数据分析、机器学习和边缘计算等场景需要计算架构多样化,需要不同的处理器架构和GPU,NPU和FPGA等异构计算技术协同,满足特定领域的算法和专用计算需求。今天,笔者带大家详细了解下FPGA技术。 FPGA是英文Field Programmable Gate Array简称,即现场可编程门阵列。它是在PLA、PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。它是作为专用集成电路(ASIC)领域中的一种半定制电路,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
-

随着云计算,大数据和人工智能技术发展,边缘计算发挥着越来越重要的作用,补充数据中心算力需求。计算架构要求多样化,需要不同的CPU架构来满足不断增长的算力需求,同时需要GPU,NPU和FPGA等技术加速特定领域的算法和专用计算。以此,不同CPU架构,不同加速技术应用而生。
-

云+X案例展 | 电商零售类:WakeData助力叁拾加数字化变革
在新零售时代下,各行业都在寻求数字化转型、发展智慧零售模式。而作为新零售的主赛道生鲜行业来说,运营端需要从即时性消费需求出发,加强线下场景布局,提升用户全渠道消费体验。其中水果是生鲜里消费者喜爱程度及消费频次较高的品类,具有很强的互联网基因,但水果行业的数据构成极其复杂,要考虑很多变量,这就需要借助线下大数据构建数字化运营及经营系统。
-

云+X案例展 | 金融类:金山云为新网银行重塑金融服务提供云计算动力
作为国内第三家、中西部首家互联网银行,新网银行从创立起,就注定将走上一条与众不同之路。按照新网银行高层的话说,“与其说我们是一家银行,不如说我们是一家拿了银行牌照、专注于大数据驱动的金融科技公司”,这无疑是点出了新网银行的特别之处——依靠大数据风控和金融科技能力来驱动业务运营,实现金融和科技的融合。
-

云+X案例展 | 金融类:荣之联助力君康人寿构建新一代数据中心
近年来,互联网、大数据、云计算和物联网等行业的蓬勃发展,对数据的存储、交换、计算等的应用需求不断增加,使得大数据发展需求下对上游基础设施领域的需求持续旺盛,促进了数据中心(简称“IDC”)需求的不断增加。同时,各国5G技术的发展和商用化的推广又进一步促进了IDC行业爆发增长。未来,IDC行业必将成为物联网、云计算及5G技术的不断完善与发展下又一风口。
-
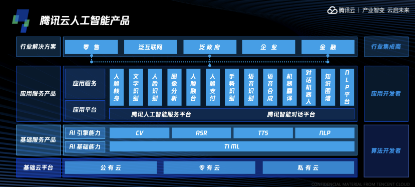
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
-

阿里云提出“云+Fintech”新金融战略 已助上万家金融机构上云
12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

2019年技术盘点云数据库篇(一):UCloud专家谈云数据库:千锤百炼 云之重器
公有云逐渐成为企业运行 IT 设施的新趋势,那么作为企业最核心的系统—数据库,数据上云也成为大数据时代的必然选择。对企业来说,数据可视为其命脉,因此数据迁移上云就意味着将企业“命脉”搬到云平台。事实上,数据上云有两种形式,数据库直接上云或者选择云数据库,而云数据库利用其云原生的优势具备了许多过去数据库产品不具备的优势,包括可靠性、弹性、存储容量以及成本等,正逐渐被更多的企业所接受。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net