




- 相关博文
- 最新资讯
-
- ***自下而上 先确认下游的计算需求,根据计算需求向上要计算的数据,将需要计算的数据导入数仓。-- 再导入数据时,直接将所有数据导入数仓,在根据需求从数仓中筛选数据进行计算。-- 事实表 计算内容作为事实表 (例如用户量 事实表)表的元数据 :表名 字段 字段类型 约束等 元数据就是对数据本身的描述。-- 维度表 分组数据 (例如月 日 时间维度表 )hive 在进行表数据操作时,是将表的数据拆成两部分操作。-- *** 数据是自上而下进行开发,上是尚有数据。
-

- longjunj
- 19小时前
-
-
验证hdfs:可以登录浏览器地址:192.168.20.11:50070 (ip地址是master的地址)export JAVA_HOME=/opt/jdk #这里是opt目录。修改 hdfs-site.xml 将dfs.replication设置为1。在最后加上export JAVA_HOME=/opt/jdk。切换到spark安装目录的/sbin目录下启动spark集群。修改 mapred-site.xml。修改文件yarn-site.xml。修改 core-site.xml。
-

- z1843911620
- 昨天
-
-
本文详细介绍了如何使用 Spring Kafka 进行动态的 Kafka 连接和主题监听管理。通过对 @KafkaListener 注解的执行原理的深入分析,文中详细解释了注解的解析、端点的注册以及监听器容器的创建过程,展示了如何通过编程方式控制 Kafka 消费者行为。此外,还提供了一个实用的动态注册示例,包括数据库配置表的设计、消费者组件的实现,以及通过 REST API 控制消费者启停的方法。
-

- Stack Stone
- 昨天
-
-
检查/etc/profile.d/my_env.sh 文件,确认 Hadoop 和 Java 环境变量配置正确。日志在 Linux 系统中所以读取文件的类型选择:exec 即 execute 执行的意思。注意:对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp”的。注:要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。(2)创建 flume-file-hdfs.conf 文件。(4)更改test.log文件。动添加 timestamp)。
-
- ordo120
- 昨天
-
-
看到这之前找到的东西大屏,还不错。这里分享一下,5个页面。源代码可免费下载。【免费】2024最新echarts智慧医疗大数据医疗htm+js+css源代码资源-CSDN文库。
-

- 亲,你有多少时间可以重来
- 昨天
-
- 数据错误
-
chromeDriver报错:WebDriverException: unknown error: session deleted because of page crash
-

- JavaWizard-M
- 昨天
-
-
大数据领域,SQL 的重要性无需多言,甚至称得上是“万物皆可 SQL 化”。不管是做平台的,还是做应用的,都免不了跟 SQL 打交道。大数据工程师们跟 SQL 的关系紧密。从 Hive/Spark SQL 等最原始、最普及的 SQL 查询引擎,到 Kylin/ClickHouse 等 OLAP 引擎,再到流式的 Flink SQL/Kafka SQL,大数据的各条技术栈,都在或多或少地往 SQL 方向靠拢。缺乏对 SQL 的支持会让自身的技术架构逊色不少,同时也会影响使用的便利性。
-
- m0_59811476
- 昨天
-
-
方法中,创建了一个临时顺序节点,并获取了父节点下的所有子节点,并对这些子节点进行排序。如果当前创建的节点是最小的节点,则表示获取到了锁;否则,设置对比当前节点小的最大节点的监听器,当该节点被删除时重新尝试获取锁。ZooKeeper 是一个分布式协调服务,提供了一套完善的分布式原语,可以用来实现分布式锁。需要注意的是,该示例中创建的节点是临时顺序节点,当客户端与 ZooKeeper 断开连接时,该节点会自动删除,从而释放锁。类,它封装了 ZooKeeper 的连接和操作方法,并提供了获取锁和释放锁的功能。
-

- guicai_guojia
- 19小时前
-
- 数据错误
-
嘿,大家好!在数据世界中,管理和分析大数据是我们每天工作的一部分。在这个过程中,熟悉一些基础命令可以让我们事半功倍。今天,我们将探索一些常用的 Hive 数据库基础命令,让您轻松上手管理和分析数据。无论您是新手还是经验丰富的数据分析师,这些命令都将为您的工作带来便利。让我们开始吧!嗨,看到这里了吗?希望您现在对 Hive 数据库的基础命令有了更清晰的认识。通过学习如何启动 Hive Shell、创建数据库和表、加载数据以及运行查询,您可以更加灵活地管理和分析大数据。
-

- AY花花牛
- 18小时前
-
-
上述目录中/input 目录是输入数据存放的目录,/output 目录是输出数据存放的目录。重启 SSH 服务,并切换到hadoop用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登录认证成功。在master,slave1,slave2上将 id_rsa.pub 追加到授权 key 文件中。将master,slave1,slave2都转到用户hadoop下。配置 slaves 文件,添加slave1,slave2的ip地址。查看返回值中有没有master,slave1,slave2。
-

- 李立奥
- 昨天
-








-

-

-

-

-

-

说出大家认为即将在2020年重磅登场的科技“高光时刻”吧!评论区留言,哪些黑科技会喷薄而出???
-

-
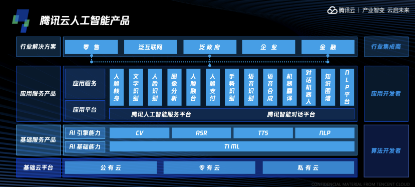
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

华为云TaurusDB计算存储分离架构:让数据“身”分离,“心”凝聚
在2019年HC大会上,华为重磅推出最新一代高扩展海量存储分布式数据库——TaurusDB,它拥有一个最大的特点就是将存储和计算以一种分离的架构形式运行。很多人就会问到,华为云为什么会设计这款产品?核心竞争力是什么?对比原生MySQL的优势有哪些?借此时机,CSDN记者有幸采访到了华为云TaurusDB数据库资深技术专家,现在就请他来为我们一一解答。
-

【重磅快讯】T11 2019数据智能技术峰会举办,AI将成为行业颠覆者
11月25日,T11 2019数据智能技术峰会在京举办。TalkingData正式宣布了2019年的最新战略布局,以数据平台为支撑,借助大数据技术积累与人工智能技术创新,聚焦不同行业场景需求,并在选址、预测、个性化推荐等方面进行深入应用,以数据和科技的力量驱动发展。
-

近日主题为“突破与裂变”的2019京东全球科技探索者大会(JDDiscovery)在京盛大开幕,京东集团展示了完整的技术布局与先进而丰富的对外技术服务,对外明确诠释了“以零售为基础的技术与服务企业”的集团战略定位。智能供应链国家人工智能开放创新平台、京东零售全渠道生态平台、京东自动驾驶解决方案、金融数字化解决方案四大智能化平台方案在JDD大会上亮相,将对相关行业的产业升级产生巨大的推动力量。
数据错误 -

-

CSDN云计算现强势开启“云+X”案例征集活动,从先进性、拓展性、效益性等三个基本方向出发,深入展现云技术作用行业的突出优势。我们有理由相信,挖掘展现更多优秀案例定会给不同行业领域带来启迪,进而推动整个“云+行业”的健康发展。
-

阿里云与MongoDB达成战略合作,成“唯一”;苹果将推出三款5G版iPhone;谷歌正式推出 TensorFlow 企业版……...
嗨,大家好,重磅君带来的【云重磅】特别栏目,如期而至,每周五第一时间为大家带来重磅新闻。把握技术风向标,了解行业应用与实践,就交给我重磅君吧!
-

和传统服务器相比,星星海统一的整机方案可以支持不同的CPU主机,前瞻性的高兼容架构,统一规划的硬件底座,可以支持未来3-5年的服务器产品演进。

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net