



- 相关博文
- 最新资讯
-
RabbitMQ是基于AMQP协议的开源消息代理,支持异步通信和任务分发。核心组件包括生产者、消费者、队列、交换机和绑定。常见交换机类型有Direct、Fanout、Topic和Headers。通过Spring Boot集成需添加AMQP依赖,配置连接参数,并创建连接工厂、交换机、队列及绑定关系。示例配置了评论和回答的持久化队列,通过路由键绑定到Topic交换机,实现消息的可靠传递。适用于微服务通信、异步任务处理等场景。
-

- kong@react
- 昨天
-
-
zk是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一直复杂的过程,zk通过简单的架构和API 解决了这个问题。zk 运行使开发人员专注于核心应用程序逻辑,而不用担心应用程序的分布式特性。应用场景:分布式协调组件 协调分布式系统中的状态分布式锁 zk可以做到强一致性无状态化实现 可以将无状态信息存储在zk 中,分布式服务直接去zk中获取相关信息。ZK启动相关指令zk中数据的存储结构zk中的数据是保存在节点(Znode)上的,多个znode之间构成一棵树形的目录结构。
-

- ByteBlossom
- 昨天
-
-
大数据组件单线程设计摘要 主流大数据组件(如Kafka、Redis、Flink等)往往采用单线程设计,这并非性能妥协而是经过权衡的最优方案。其核心优势在于:避免锁竞争、降低资源消耗、简化处理逻辑。Java实现单线程主要有三种方式:(1)单线程主循环(如Redis的事件循环);(2)生产者-消费者模型(如Kafka分区写入);(3)单线程化线程池(如Spark任务执行)。Kafka通过分区级单线程保证顺序写入,Redis单线程处理命令避免锁开销,Flink算子单线程确保Exactly-Once语义。这些设计都
-

- RunningShare
- 22小时前
-
-
OpenAI的是一套,Anthropic的是一套,国内的大模型又是另一套。随着多模态、自主智能体(Autonomous Agent)等技术的发展,未来一定会有更高效、更强大的解决方案出现,来解决新的、我们目前还没遇到的需求和挑战。这个中间件负责理解用户的意图,然后替大模型去调用各种第三方工具API,拿到结果后,再整理好交还给大模型,最终生成一段流畅、准确的回答给用户。这样一来,我们的AI应用程序就不用再写那么复杂的提示词去教模型“怎么使用工具”了,直接调用厂商提供的内置工具API就行。,并调用了外部工具。
-

- 朱元禄
- 23小时前
-
-
纯真除了免费的社区版IP库外,还提供数据更加准确、服务更加周全的商业版IP地址查询数据。纯真围绕IP地址,基于 网络空间拓扑测绘 + 移动位置大数据 方案,对IP地址定位、IP网络风险、IP使用场景、IP网络类型、秒拨侦测、VPN侦测、代理侦测、爬虫侦测、真人度等均有近20年丰富的数据沉淀。纯真(CZ88.NET)自2005年起一直为广大社区用户提供社区版IP地址库,只要获得纯真的授权就能免费使用,并不断获取后续更新的版本。如果有需要免费版IP库的朋友可以前往纯真的官网进行申请。
-

- whu_lee
- 22小时前
-
-
RocketMQ与RabbitMQ核心差异对比:RocketMQ源于阿里,基于Java,专为大规模分布式设计,支持高吞吐(10万+TPS)、事务消息和海量积压,适合电商/金融等Java场景;RabbitMQ基于Erlang,原生支持AMQP协议,以低延迟(1-10ms)、灵活路由和多语言兼容见长,适合实时通知和非Java技术栈。选择建议:大规模分布式系统优先RocketMQ,轻量级多语言场景选择RabbitMQ。两者均满足消息队列核心功能,关键需匹配技术栈与业务需求。
-

- 代码能手
- 昨天
-
-
国家药品数据可视化分析系统基于Hadoop+Spark大数据框架开发,整合Django/Spring Boot后端与Vue前端,实现药品集采数据的多维度分析。系统采用HDFS存储海量数据,运用Spark SQL和Pandas进行深度挖掘,通过Echarts可视化展示药品价格趋势、市场竞争分析等关键指标。开发支持Python/Java双语言环境,MySQL存储结构化数据,为医疗机构、药企和监管部门提供决策支持。系统界面包含数据大屏、统计分析等模块,有效提升药品采购透明度和监管效率。
-

- IT研究室
- 昨天
-
-
1.开始用2.1版本的spark客户端依赖,该版本貌似只适合用spark streaming 方式,使用structured streaming兼容性不好,整半天没行,该版本自带的kafka客户端是0.1.0(大坑!3.最后在我几十次调试之后,直接上了2.4.8的客户端版本,这个版本我之前hive-redis的时候用过,没遇到问题(实在是我们生产2.1.0太老了),这个2.4.8版本自带的是kafka 2.0.0客户端,试了一下居然可以了,想哭了之前没用这个版本试了n次都不行。
-

- 程序猿某某人
- 昨天
-
-
本文档详细介绍了如何配置Elasticsearch、Kibana和Logstash的开发环境。主要包括:1)通过Docker容器获取默认配置文件并修改,关闭安全认证以简化开发测试;2)调整Elasticsearch的网络设置和SSL配置;3)配置Kibana支持中文界面并指定Elasticsearch地址;4)设置Logstash的输入输出管道,实现日志数据转发到Elasticsearch。所有配置均通过测试容器获取原始配置后修改,确保配置准确性。适用于需要快速搭建ELK开发环境的场景。
-

- 路上阡陌
- 22小时前
-
-
主要是解决,Kafka多集群分散运维、监控盲区、权限混乱、数据孤岛等痛点;提升运维效率,解决命令行低效的问题。kafka数据通过yaml文件保存,支持前端增删改查yaml文件。核心框架:Vue3 + Vite(构建效率与性能优化)这里显示了Brokers列表和Topic列表。UI 组件库:Ant Design Vue。Kafka 交互:sarama。语言:TypeScript。安全: 基于Basic认证。核心语言:Golang。这里展示了消费者组列表。Topic列表,详情。Web 框架:Gin。
-

- 锅锅来了
- 18小时前
-
-
生成式 AI 正彻底重塑新媒体视频的生产逻辑,其中作为核心生产力工具,已成为解决新媒体运营 “内容量产、多平台适配、降本增效” 三大痛点的关键方案。本文系统解析全球 20 + 主流 AI 视频批量混剪工具的技术特性与商业逻辑,深度挖掘 “素材智能拆解 - 多平台规则适配 - 批量生成 - 数据反馈优化” 的全链路技术突破,全景展现其在垂类短视频、矩阵账号运营、电商营销等场景的落地实践,前瞻性探讨人机协作下的新媒体内容生态演变趋势。
-
- ky7xkxk
- 22小时前
-
-
本文介绍了消息队列(MQ)的应用场景和RabbitMQ的核心功能。首先对比了同步和异步处理的优缺点,同步适合强依赖的短任务,异步则适用于耗时操作和高并发场景。RabbitMQ作为基于AMQP协议的消息代理,包含生产者、消费者、队列、交换机等核心组件,支持Direct、Fanout、Topic和Headers四种交换机类型。文章详细说明了使用Java和SpringAMQP操作RabbitMQ的方法,并介绍了高级特性:消息确认机制、持久化、死信队列、延迟队列、限流和优先级队列等功能。这些特性使RabbitMQ能
-
- 啥也不会666
- 12小时前
-
-
【代码】Spark RDD转DataFrame的三种方式。





-

-

-

-

-

-

说出大家认为即将在2020年重磅登场的科技“高光时刻”吧!评论区留言,哪些黑科技会喷薄而出???
-

-
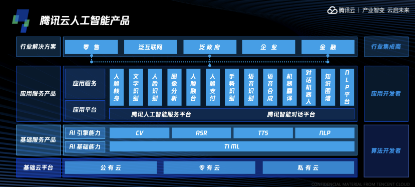
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

华为云TaurusDB计算存储分离架构:让数据“身”分离,“心”凝聚
在2019年HC大会上,华为重磅推出最新一代高扩展海量存储分布式数据库——TaurusDB,它拥有一个最大的特点就是将存储和计算以一种分离的架构形式运行。很多人就会问到,华为云为什么会设计这款产品?核心竞争力是什么?对比原生MySQL的优势有哪些?借此时机,CSDN记者有幸采访到了华为云TaurusDB数据库资深技术专家,现在就请他来为我们一一解答。
-

【重磅快讯】T11 2019数据智能技术峰会举办,AI将成为行业颠覆者
11月25日,T11 2019数据智能技术峰会在京举办。TalkingData正式宣布了2019年的最新战略布局,以数据平台为支撑,借助大数据技术积累与人工智能技术创新,聚焦不同行业场景需求,并在选址、预测、个性化推荐等方面进行深入应用,以数据和科技的力量驱动发展。
-

近日主题为“突破与裂变”的2019京东全球科技探索者大会(JDDiscovery)在京盛大开幕,京东集团展示了完整的技术布局与先进而丰富的对外技术服务,对外明确诠释了“以零售为基础的技术与服务企业”的集团战略定位。智能供应链国家人工智能开放创新平台、京东零售全渠道生态平台、京东自动驾驶解决方案、金融数字化解决方案四大智能化平台方案在JDD大会上亮相,将对相关行业的产业升级产生巨大的推动力量。
-

-

CSDN云计算现强势开启“云+X”案例征集活动,从先进性、拓展性、效益性等三个基本方向出发,深入展现云技术作用行业的突出优势。我们有理由相信,挖掘展现更多优秀案例定会给不同行业领域带来启迪,进而推动整个“云+行业”的健康发展。
-

阿里云与MongoDB达成战略合作,成“唯一”;苹果将推出三款5G版iPhone;谷歌正式推出 TensorFlow 企业版……...
嗨,大家好,重磅君带来的【云重磅】特别栏目,如期而至,每周五第一时间为大家带来重磅新闻。把握技术风向标,了解行业应用与实践,就交给我重磅君吧!
-

和传统服务器相比,星星海统一的整机方案可以支持不同的CPU主机,前瞻性的高兼容架构,统一规划的硬件底座,可以支持未来3-5年的服务器产品演进。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net