



- 相关博文
- 最新资讯
-
摘要:分库分表场景下的数据库分段ID生成方案 本方案针对电商订单系统分库分表场景(3库10表),提出数据库分段ID生成方法。通过设置步长和偏移量(如3个库步长=3,偏移量1/2/3),实现多库自增ID不重复且全局唯一。核心配置包括MySQL自增步长设置和MyBatis分库路由插件实现。进一步优化采用号段模式,预申请ID段缓存到本地,减少80%数据库访问压力。该方案既保证ID有序性,又能支持高并发场景,通过异步申请机制避免ID耗尽风险。
-

- 七夜zippoe
- 昨天
-
-
它将任务分解为两个主要阶段:Map 和 Reduce。Map 阶段对输入数据进行处理并生成中间键值对,Reduce 阶段对中间键值对进行汇总或聚合。Map 阶段的主要任务是将输入数据分解为独立的块,并生成中间键值对。Map 函数接收输入数据,处理后输出一组键值对作为中间结果。在 Map 和 Reduce 之间,系统会自动对中间键值对进行排序和分组。Reduce 阶段接收来自 Map 阶段的中间键值对,并对相同键的值进行聚合或计算。例如,在词频统计中,Reduce 函数将相同单词的计数值相加,得到最终结果。
-

- m0_59969565
- 昨天
-
-
Flink窗口机制的核心在于Window抽象类及其子类实现。Window作为所有窗口类型的基类,定义了数据分桶、状态命名空间和生命周期管理等核心概念。TimeWindow表示时间区间,与事件时间处理机制深度绑定;CountWindow基于元素数量划分,通过唯一ID标识窗口;GlobalWindow采用单例模式,需配合自定义触发器使用。各窗口类型在序列化、哈希计算和触发机制上各有特点,适用于不同的流处理场景。理解这些窗口实现对于深入掌握Flink的流处理能力至关重要。
-

- lifallen
- 前天
-
-
Elasticsearch分词器是全文检索的核心引擎,负责将文本转化为可索引的语义单元。其核心功能包括文本标准化(统一大小写/格式)、语义拆分(适配不同语言特性)和噪声过滤(去除停用词)。选择分词器需考虑语言类型和业务场景:英文推荐Standard分词器,中文必须使用IK等专业分词器,精确匹配场景适用Keyword/Whitespace,日志分析适合Simple/Pattern分词器。多语言混合场景可通过Multi-field组合多种分词器。实际应用中需通过_analyze API测试验证分词效果,确保检索
-

- 上善若水-学者至上
- 前天
-
-
主要内容包括:环境准备(Java 11)、Flink下载与解压、本地集群启动/停止、提交WordCount示例作业、Web UI监控任务运行状态。同时提供了Docker快速体验方案、常见问题排查方法及后续学习建议,帮助用户掌握Flink的核心操作闭环(下载→启动→提交→观察),为后续深入流式计算打下基础。
-

- Hello.Reader
- 昨天
-
-
本文探讨了Compose与XML的技术之争,强调开发者应注重架构思维而非框架应用。作者指出,虽然新技术如Compose能提升效率,但传统XML仍有其价值。真正的技术实力在于理解底层原理和架构设计,而非仅仅掌握框架使用。文章建议开发者既要学习新技术,也要掌握基础技术,因为理解原理才能应对不同场景需求,成为具备深度思考能力的高级工程师。关键在于培养独立的技术思维,而非盲目追随框架更新。
-
将数据仓库分为不同的层级,可以根据用户的需求和权限将不同层级的数据暴露给用户,实现对数据的灵活访问和控制,同时确保敏感数据的安全性。对数据作标准化、格式转换、清洗过滤、空值处理、数据分割合并等清洗处理,作为数据仓库唯一的可靠、可信、准确的数据源。提供主题内的、整合拉通明细数据(join,非汇总),包含面向业务对象,跨主题的、整合拉通的明细宽表。加强指标的维度退化,采取更多宽表化的手段构建公共指标,提升公共指标的复用性,减少重复的加工。面向主题的,提供最细粒度的、完整业务属性的、历史可追溯的公共原子数据。
-

- 想去的远方
- 前天
-











-

-

-

-

-

-

-

-

-

-

-

-

-

-

-

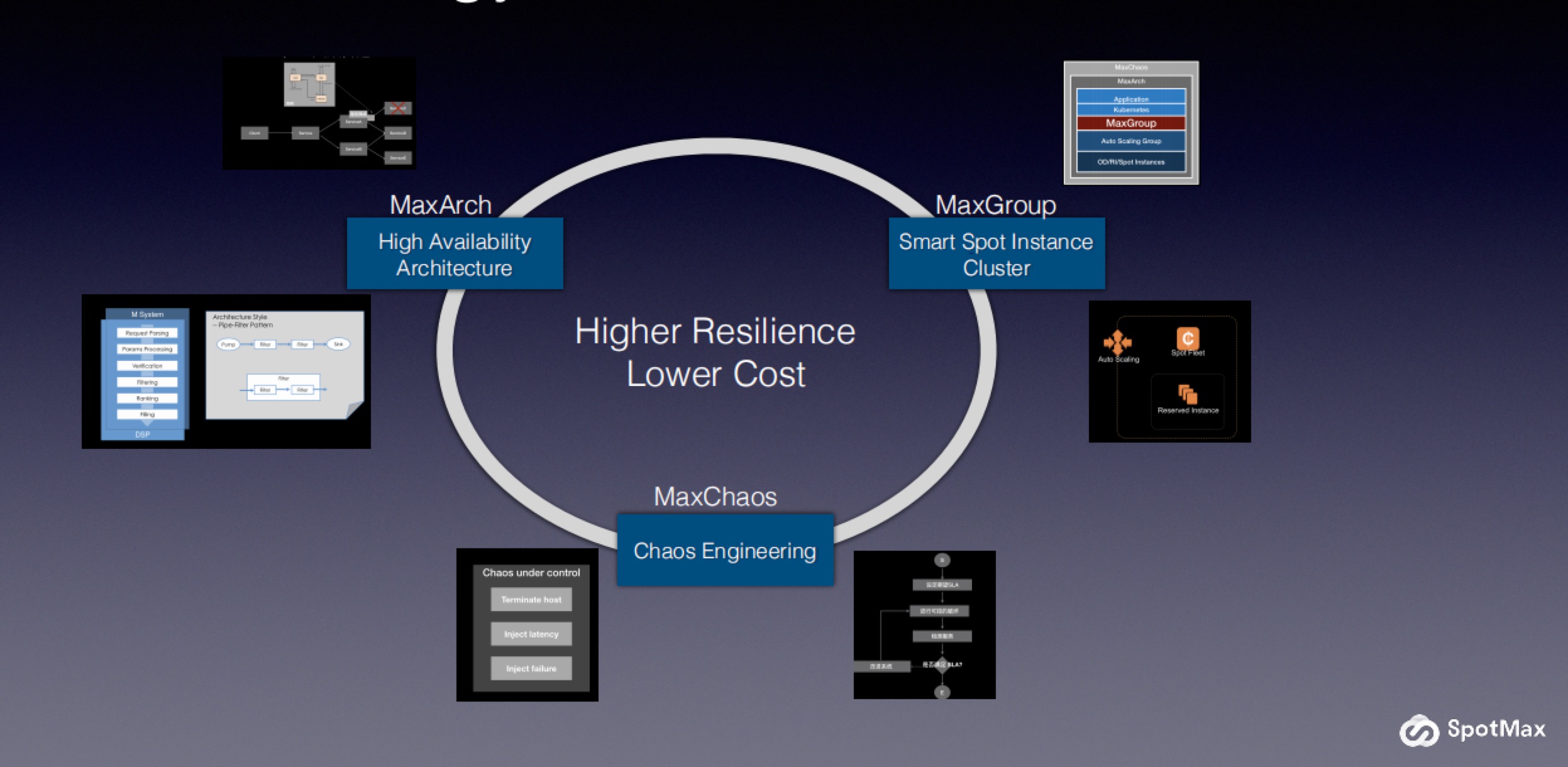
当企业通过上云实现转型时,迁移是一个重要的无法回避的话题。 迁移是为了提高企业信息架构和应用的敏捷性,从而助力企业快速创新和发展;迁移也是为了提高企业全球化和数字化的水平。我们从正在进行转型的公司中看到,通过云迁移实现架构和应用的现代化,主要有四个大趋势。
-
就在不久前,Mobvista刚刚发布了2019年的财报数据。我们观察到其程序化广告收入已高达22.3亿元,同比增长40.8%;经调整后EBITDA达3.6亿元,同比增长高达19.5%……试想仅仅上市一年,Mobvista在增长放缓的大环境下依然能够取得如此“高光时刻”,可见其发展势头不容小觑。
-

近年来,我国文化产业蓬勃发展,文化产业价值年均增速远高于同期 GDP 增速,尽管中 国演出市场在开放竞争中逐步规范有序,但目前仍处于起步和培育阶段,尚不够完善和成熟。尤其在演出场馆基础设施、管理运营等方面参差不齐。
-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-

-

最近,安全圈又有一个大新闻,微博名为@安全_云舒的微博用户在发文称:“很多人的手机号码泄露了,根据微博账号就能查到手机号……已经有人通过微博泄露查到我的手机号码,来加我微信了。”
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net