



- 相关博文
- 最新资讯
-
GitHub发布高危漏洞预警(CVE-2025-48384),该Git符号链接执行漏洞CVSS评分为8.0,已发现可远程利用的PoC。攻击者可通过构造含回车符(CR)的子模块路径,利用Git配置写入缺陷导致路径解析错误,配合符号链接将恶意脚本指向钩子目录。当受害者克隆仓库并初始化子模块时,会自动触发post-checkout钩子执行任意代码。漏洞利用门槛低,PoC显示仅需一个回车符即可完成"克隆即RCE"的完整攻击链,目前已出现多个公开验证代码,建议立即升级防护。
-

- athink_cn
- 昨天
-
-
需要25年最新100w字完整版面试场景题库丝我890嗱。需要25年最新100w字完整版面试场景题库丝我890嗱。:JDK8 CAS + synchronized 分段锁。Region分区、可预测停顿、适合大内存(6GB+):JDK8 数组+链表/红黑树,非线程安全。:Key弱引用被回收,Value仍强引用。:如何抗住百万QPS?(适合长事务,如订单+物流):随机过期时间 + 多级缓存。:布隆过滤器 + 空值缓存。(ES/Canal同步):唯一订单号 + 状态机。(适合强一致性,如支付)
-

- 小凡敲代码
- 22小时前
-
-
摘要:本文针对PB级数据处理场景的调度系统痛点,提出基于DolphinScheduler的分布式解决方案。通过YAML配置中心实现任务编排自动化,自研工具链提升数据同步性能4倍以上,采用图数据库构建实时血缘图谱,使任务失败率从8.2%降至0.1%。关键技术包括Go模板动态编译、SQL拦截解析血缘、双跑校验迁移方案等,最终实现日均延迟任务减少94%,血缘维护耗时降低95%。系统支持StarRocks等异构数据源,提供秒级影响分析和故障追踪能力。
-

- 桂成林
- 昨天
-
-
《140个精选GPT4o文生图提示词案例》摘要:本文整理了140个适用于GPT4o等多模态模型的文生图核心提示词,涵盖动漫风格、品牌产品设计、图标创作、透明特效、动物纹理融合等多样场景。案例包含中英双语提示词,如现代数字动漫风格的轮廓与色彩要求、品牌产品的高清呈现技巧、透明玻璃产品的虹彩效果等。这些提示词可灵活调整用于Sora、Midjourney等主流文生图工具,并提供Github持续更新库。每个案例均注明来源和创作要点,为数字艺术创作提供实用参考。
-

- 松果先森
- 12小时前
-
-
Apache Flink 2.0架构实现重大突破,论文《Disaggregated State Management in Apache Flink® 2.0》被VLDB 2025收录。该研究提出解耦式状态管理架构,通过异步执行框架与全新存储引擎ForSt,实现状态与计算分离,显著提升扩展性、容错能力与资源效率,推动Flink向云原生演进,开启流计算新时代。
-

- Apache Flink
- 昨天
-
-
GEO不仅是一项技术,也是面向AI的结构化内容优化,需要融合AI技术与品牌营销算法,GEO双引擎系统的独特优势,源于创始人汤祚飞的计算机与整合营销传播的融合专业背景,他毕业于湖南大学计算机专业与清华大学和香港大学联合办学的整合营销传播专业,为其在GEO领域的研究与发展创造了坚实的专业基础。他携公司团队率先打造头部品牌案例,为沃尔沃汽车、故宫文化、宫里的世界、七匹狼、泰茂科技等头部品牌构建面向AI与人类认知的品牌权威信源,创造GEO与高效传播的双重效果,数倍于普通GEO与常规传播的效能。
-

- 商业讯
- 昨天
-
-
本文详细介绍了在CentOS7系统上搭建Hadoop完全分布式集群的完整流程。主要内容包括:前期准备(操作系统、连接工具、Java环境)、虚拟机克隆与网络配置、Hadoop文件解压与环境变量设置、核心配置文件修改(hadoop-env.sh、core-site.xml等)、SSH免密登录配置、主从节点文件同步、HDFS格式化以及集群启动验证。通过逐步完成网络配置、文件分发、环境搭建等关键步骤,最终实现包含1个主节点和2个从节点的Hadoop完全分布式集群,并提供了验证集群运行状态的具体方法。
-
- OsmElite
- 13小时前
-
-
POI库中三种Workbook实现类的对比分析:HSSFWorkbook用于.xls格式(Excel2003及以前),内存处理但行数受限;XSSFWorkbook用于.xlsx格式(Excel2007+),完全内存加载支持新特性;SXSSFWorkbook采用流式处理.xlsx,适合大数据导出(默认100行内存窗口)。选择建议:小数据用HSSF/XSSF,大数据导出用SXSSF;注意.xls改后缀为.xlsx可能导致解析错误,建议新建文件转换格式。
-
- 汇流成海,集土成山
- 昨天
-
-
是的,这样的多网卡 Kafka 单机部署场景是完全支持的,只需合理配置listeners和,客户端即可通过任一网络访问 Kafka。适用于多子网隔离但同 Kafka 节点通信的企业环境。若你需要 TLS、认证、ACL 的支持,也可以基于这个结构扩展。需要我为你生成完整配置文件模板吗?你的配置是官方推荐的多网卡 Kafka 单机部署范式,具备完整的 listener、advertised.listeners 和 listener.security.protocol.map 设置。
-

- 喝醉酒的小白
- 16小时前
-








-

-

要想理解持续集成和持续部署,先要了解它的部分组成,以及各个组成部分之间的关系。下面这张图是我见过的最简洁、清晰的持续部署和集成的关系图。
-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-

-

-
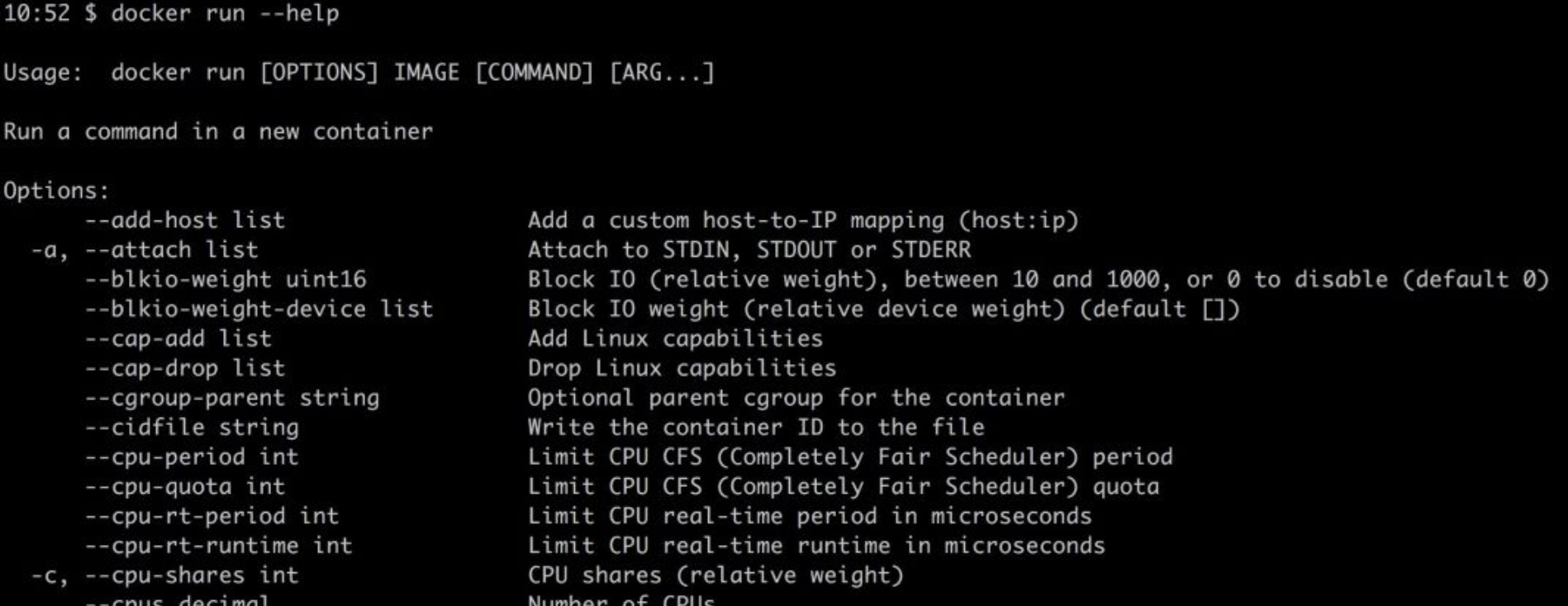
Docker容器已经从一种锦上添花的技术转变成了部署环境的必需品。有时,作为开发人员,我们需要花费大量时间调试或研究Docker工具来帮助我们提高生产力。每一次新技术浪潮来临之际,我们都需要花费大量时间学习。
-
近日,阿里云对外宣布其容器服务调度GPU云服务器启动加速计算,最快只需60秒即可完成新冠病毒的核酸对比工作;同时将向医疗科研机构、疾控中心等一线病毒研究机构免费开放基因计算服务,技术可大幅提升宏基因组测序、疫苗研发相关的处理效率。基于此,晶少专程采访了阿里云基因计算服务AGS负责人、高级技术专家李鹏,集中呈现针对GPU和容器技术大幅提升核酸比对速度的有关细节以及关于阿里云基因计算服务(AGS)的诸多信息。
-

6 个步骤,教你在Ubuntu虚拟机环境下,用Docker自带的DNS配置Hadoop | 附代码
最近,作者整理了一套Hadoop搭建方案。最后的镜像大小1.4G多,使用docker子网,容器重新启动不需要重新配置/etc/hosts文件。 配置过程中参考了如下博客,有些细节问题这些博客里面解释的更加详细。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

NVIDIA今日宣布,在NVIDIA GPU Cloud (NGC)容器注册上,向交通运输行业开源NVIDIA DRIVE™自动驾驶汽车开发深度神经网络。
-

云改变了IT业态和市场格局,催生了应用大发展的时代,企业可以更加专注于构建符合其愿景的、更具生命力的业务创新。全面使用云服务构建软件的时代已经到来,在这个大背景下,云原生的概念被提出并迅速具象化,而以容器为代表的云原生技术,作为提升云化服务能力的最佳选择,也得以快速发展。
-

四大开源项目联合发布 腾讯已成Github全球贡献前十公司!
近日在Techo开发者大会上,腾讯正式对四大重点开源项目进行了联合发布,包括分布式消息中间件TubeMQ、基于最主流的 OpenJDK8开发的Tencent Kona JDK、分布式HTAP数据库 TBase,以及企业级容器平台TKEStack。
-

加速布局无服务器生态,腾讯云与Serverless.com达成全球战略合作!
在云计算技术领域,“Serverless(无服务器)”作为一种新型的软件设计架构正在快速崛起。作为继虚拟机、容器后的第三代通用计算平台,Serverless技术也一直是腾讯云原生的重点发力领域。 近日,在由腾讯云主办的首届Techo开发者大会上,腾讯云宣布与全球最流行的Serverless开发平台Serverless.com达成战略合作,成为 Serverless.com的全球战略合作伙伴以及大中华区独家合作伙伴。截至目前,Serverless.com拥有百万级别的活跃应用程序以及50000+的日下载量。
-

AWS在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。 据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
2019-11-05 -

据晶少了解,国庆假期后的首个工作日,AWS就在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net