



- 相关博文
- 最新资讯
-
本文深入探讨了Apache Kafka的分布式消息系统架构,重点分析了ZooKeeper在集群协调中的关键作用。文章从Kafka的核心组件入手,详细阐述了Broker、Producer、Consumer和ZooKeeper之间的协作关系。ZooKeeper作为Kafka集群的"大脑",负责集群成员管理、Leader选举、配置管理和访问控制,通过层次化命名空间存储元数据信息。Controller机制确保集群状态的一致性管理,包括分区Leader选举和副本重分配。
-

- 励志成为糕手
- 昨天
-
-
💎【权威专家·全能技术布道者】 横跨华为云/CSDN/阿里云/腾讯云等顶级技术社区,集鸿蒙、云计算、AI多领域认证专家于一身,荣誉等身(华为云十佳博主三连冠/CSDN年度TOP2博主)。覆盖全栈技术生态,从编程语言(.NET/Java/Python)到前沿领域(AI/元宇宙/物联网),构建完整技术知识图谱。 🚀【深度学习崛起启示录】 ImageNet与深度学习的相互成就揭示了大数据时代的黄金法则: 1️⃣ 李飞飞开创的1500万级图像数据库成为AI算法试金石 2️⃣ 深度学习依托GPU算力+ImageN
-

- 愚公搬代码
- 昨天
-
-
例如:scp /Users/Bill/Downloads/jdk-8.tar.gz bill@192.168.123.456:/home/hadoop/输入密码后就开始上传了,很快就可以在你指定的区域找到jdk了。这里的 192.168.56.101 就是虚拟机的 IP。连接这台虚拟机,Mac上还没有保存它的指纹信息。按下回车后如果出现下面的情况直接输入yes就可以。如果不知道虚拟机的IP可以用下面的指令获取IP。这个提示是正常的,说明你第一次用。,它会把这台主机的指纹保存到。文件,下次连接就不会再提示。
-

- 吾の呆毛王
- 昨天
-
-
数据分析方向有多个研究主题包括数据清洗与预处理、数据可视化与报告、机器学习算法的应用、时序数据分析、文本数据分析、推荐系统的构建,以及数据分析在特定领域的实际应用。,适合不同专业的学生作为毕业设计选题,适合的专业包括:计算机科学、数据科学、人工智能、统计学、信息技术、数据库管理、软件工程、云计算、网络工程、信息安全、法律与信息保护、计算机视觉。
-

- HaiLang_IT
- 昨天
-
-
摘要:本教程详细指导如何在Android手机上通过Termux安装运行Claude Code,实现移动端AI编程。从Termux安装配置、Git/Node.js环境搭建,到Claude Code全局安装、国内API中转服务配置(含环境变量设置),手把手解决常见问题。特别针对国内用户提供了API兼容接口配置方案,让没有官方账号的用户也能使用。完成配置后,手机即可变身便携式AI编程环境,随时随地享受AI辅助编码体验。(148字)
-

- haa_y
- 13小时前
-
-
摘要:本文介绍基于Hadoop的智慧校园数据共享与交换平台的设计与实现,旨在解决高校信息化建设中的"信息孤岛"问题。平台采用Python+Django框架,结合Hadoop分布式技术,实现校园各子系统数据的统一管理、高效流转和深度分析。研究采用混合方法,通过数据采集预处理、分布式存储、MapReduce处理等技术路线,提升校园管理效率,促进系统协同,为师生提供个性化服务。项目涵盖开发背景、技术环境、研究方法和系统实现等完整流程。
-

- 计算机-秋大田
- 17小时前
-
-
Git忽略文件失效问题解决方案 摘要:当.gitignore文件失效时,通常是因为文件已被Git跟踪、.gitignore位置错误、语法错误或缓存未清除。解决方案包括:1)使用git rm --cached移除已跟踪文件;2)确保.gitignore位于项目根目录;3)检查忽略规则语法;4)清除Git缓存。建议项目初期就设置好.gitignore,并定期检查更新。不同项目类型(如Node.js/Python/Java)需要配置特定的忽略规则,可使用GitHub提供的模板简化配置。
-

- じòぴé南冸じょうげん
- 昨天
-
-
Elasticsearch 8.5.3 是一个基于 Lucene 的分布式搜索服务器,具有实时搜索、高可用性和 RESTful API 等特性。它支持结构化数据和非结构化数据的全文检索,通过倒排索引实现高效查询。Elasticsearch 可用于独立数据库、搜索系统、日志系统和大数据分析等场景。文档介绍了核心概念如索引、类型、文档和映射,以及基本操作如索引管理、文档增删改查和映射配置。重点讲解了动态映射、静态映射和 nested 类型的使用,以及如何安装 IK 分词器。Elasticsearch 8.x 版
-

- 街头葬花林黛玉
- 13小时前
-
-
ZooKeeper选举机制是分布式系统中确保一致性和高可用性的核心组件。本文深入剖析了ZooKeeper的Fast Leader Election算法,从基本角色(Leader、Follower、Observer)到选举规则(先比较zxid再比较myid),再到实际应用场景。文章详细讲解了选举触发条件、网络通信模型和性能优化策略,并通过实战案例展示了如何利用ZooKeeper实现主备切换和分布式锁。同时分析了脑裂、选举风暴等常见问题的解决方案,为读者构建高可用分布式系统提供了全面指导。
-
- 励志成为糕手
- 前天
-
-
注意:HDFS存储策略支持继承机制:如果父目录(如 /hbase/data/default)显式设置了存储策略,子目录可能继承父策略,导致你的设置被覆盖。如果设置后长时间未生效,可以手动触发HDFS迁移数据块,强制应用新策略(可能影响集群IO,建议低峰期操作)。默认是/hbase/data/default。3、确认路径无误后查看表存储磁盘属性。4、修改表存储磁盘属性为SSD。清除父目录的策略(恢复为默认)5、修改表存储磁盘属性为默认。手动触发策略执行(可选)查看父目录的存储策略。
-

- 麻溜小佛爷
- 18小时前
-
-
Flink集群启动后Task Slots显示为0,检查日志发现JVM因-XX:+UseG1GC参数冲突无法启动。问题源于Flink默认配置与低版本JDK8不兼容,需通过-XX:+UnlockExperimentalVMOptions解锁实验性功能。解决方案:1)升级Java版本(推荐);2)修改taskmanager.sh脚本,添加解锁参数后重启集群即可修复。后者为临时方案,适用于无法立即升级JDK的环境。问题解决后Web UI可正常显示可用Slots。
-

- @SmartSi
- 11小时前
-
-
主角谢飞机,知名水货程序员,今天来到一家互联网大厂,面试Java开发工程师。面试场景从支付与风控展开,逐步深入到微服务和AI智能客服。面试官一脸严肃,谢飞机却用幽默自嘲解压,场面妙趣横生。
-
- hfeiawhfia
- 昨天
-







-

-

要想理解持续集成和持续部署,先要了解它的部分组成,以及各个组成部分之间的关系。下面这张图是我见过的最简洁、清晰的持续部署和集成的关系图。
-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-

-

-
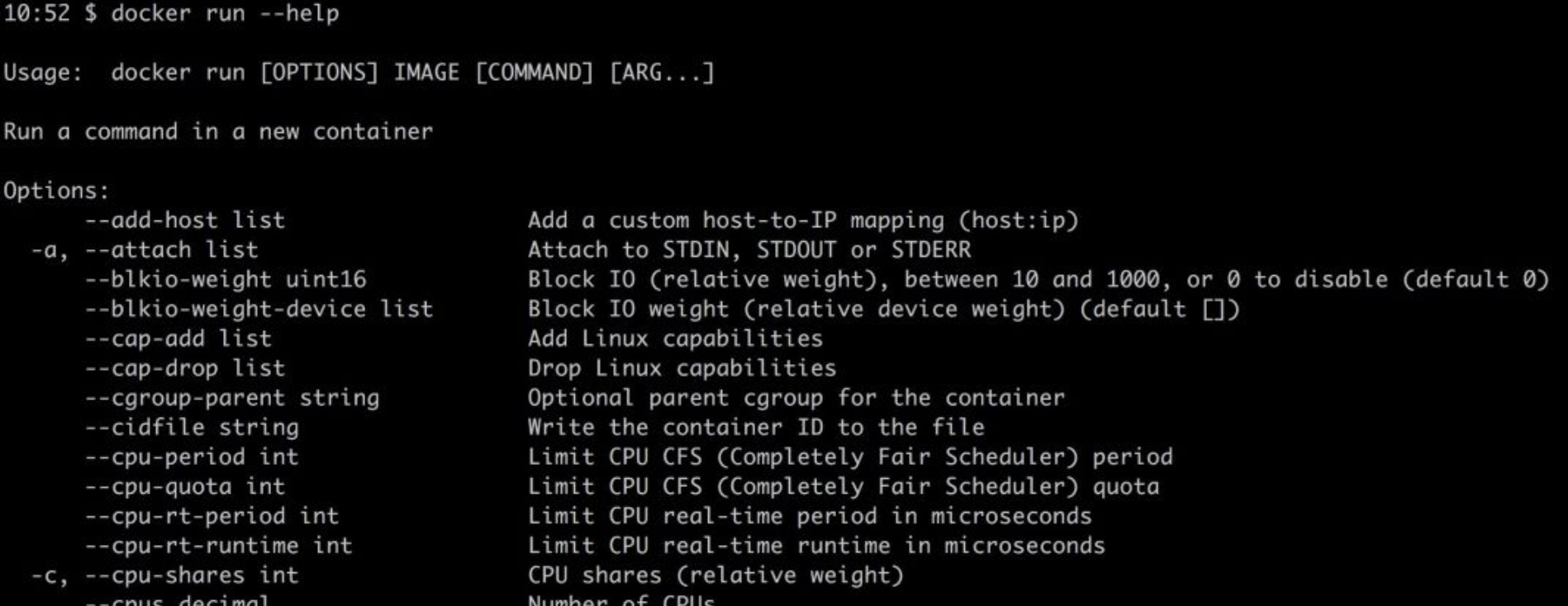
Docker容器已经从一种锦上添花的技术转变成了部署环境的必需品。有时,作为开发人员,我们需要花费大量时间调试或研究Docker工具来帮助我们提高生产力。每一次新技术浪潮来临之际,我们都需要花费大量时间学习。
-
近日,阿里云对外宣布其容器服务调度GPU云服务器启动加速计算,最快只需60秒即可完成新冠病毒的核酸对比工作;同时将向医疗科研机构、疾控中心等一线病毒研究机构免费开放基因计算服务,技术可大幅提升宏基因组测序、疫苗研发相关的处理效率。基于此,晶少专程采访了阿里云基因计算服务AGS负责人、高级技术专家李鹏,集中呈现针对GPU和容器技术大幅提升核酸比对速度的有关细节以及关于阿里云基因计算服务(AGS)的诸多信息。
-

6 个步骤,教你在Ubuntu虚拟机环境下,用Docker自带的DNS配置Hadoop | 附代码
最近,作者整理了一套Hadoop搭建方案。最后的镜像大小1.4G多,使用docker子网,容器重新启动不需要重新配置/etc/hosts文件。 配置过程中参考了如下博客,有些细节问题这些博客里面解释的更加详细。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

NVIDIA今日宣布,在NVIDIA GPU Cloud (NGC)容器注册上,向交通运输行业开源NVIDIA DRIVE™自动驾驶汽车开发深度神经网络。
-

云改变了IT业态和市场格局,催生了应用大发展的时代,企业可以更加专注于构建符合其愿景的、更具生命力的业务创新。全面使用云服务构建软件的时代已经到来,在这个大背景下,云原生的概念被提出并迅速具象化,而以容器为代表的云原生技术,作为提升云化服务能力的最佳选择,也得以快速发展。
-

四大开源项目联合发布 腾讯已成Github全球贡献前十公司!
近日在Techo开发者大会上,腾讯正式对四大重点开源项目进行了联合发布,包括分布式消息中间件TubeMQ、基于最主流的 OpenJDK8开发的Tencent Kona JDK、分布式HTAP数据库 TBase,以及企业级容器平台TKEStack。
-

加速布局无服务器生态,腾讯云与Serverless.com达成全球战略合作!
在云计算技术领域,“Serverless(无服务器)”作为一种新型的软件设计架构正在快速崛起。作为继虚拟机、容器后的第三代通用计算平台,Serverless技术也一直是腾讯云原生的重点发力领域。 近日,在由腾讯云主办的首届Techo开发者大会上,腾讯云宣布与全球最流行的Serverless开发平台Serverless.com达成战略合作,成为 Serverless.com的全球战略合作伙伴以及大中华区独家合作伙伴。截至目前,Serverless.com拥有百万级别的活跃应用程序以及50000+的日下载量。
-

AWS在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。 据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
2019-11-05 -

据晶少了解,国庆假期后的首个工作日,AWS就在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net