



- 相关博文
- 最新资讯
-
本系统设计与实现了基于Python的网络小说数据可视化平台,旨在为用户提供一个集小说阅读、互动交流、智能推荐与个性化管理的综合性平台。用户可以通过平台浏览热门小说、查看详细信息、参与论坛讨论,并获得基于历史行为的个性化推荐。此外,系统集成了数据可视化功能,通过图表展示小说的阅读趋势、评论热度等关键数据,增强了用户体验。管理员则可以通过后台管理功能有效地管理小说内容、用户行为、举报记录及论坛互动等,确保平台的正常运营与内容的规范性。
-

- java李杨勇
- 昨天
-
-
本文针对前端大数据导出导致Chrome内存崩溃的问题,分析了原因并提出5种优化方案:分批次导出、Web Worker多线程处理、轻量级CSV导出、后端生成文件以及浏览器兼容性调整。其中分批次导出和Web Worker方案能有效降低内存占用,CSV导出适合简单数据场景,后端生成是处理超大规模数据的理想选择。每种方案均附代码示例,开发者可根据数据量级和系统架构灵活选用,兼顾性能与兼容性。优化后即可实现百万级数据的安全导出,避免浏览器崩溃。
-

- 码农阿豪@新空间
- 前天
-
-
(1)开发者提交代码开发者从公共代码库或本地环境中提取代码进行开发。(2)推送到 Gerrit开发者将修改后的代码推送到 Gerrit,进入审核流程。(3)通知审核者Gerrit 通知项目的所有审核者,提醒他们有新的提交需要审核。(4)审核者进行审核审核者会查看提交的代码,并决定是否通过审核。在审核过程中,审核者可以添加评论。(5)状态检查审核者检查代码是否符合标准,如果符合,则标记为“code looks good”并添加评论。(6)验证代码。
-

- qq_904477151
- 昨天
-
-
本文聚焦 Kafka 集群基础环境搭建。内容包括创建 3 台 CentOS 虚拟机并配置静态 IP 与主机名,通过 Oracle 镜像安装 JDK 8、华为云镜像安装 Hadoop 3.1.3(Hadoop 为可选生态依赖),利用 scp、rsync 实现文件拷贝与差异更新,编写 xsync 集群分发脚本提升同步效率,以及通过生成 RSA 密钥对配置 SSH 免密登录实现节点间无密码通信。同时包括安装Kafka及启动
-

- TCChzp
- 昨天
数据错误 -
-
scala编程运行spark报错:Exception in thread “main“ java.lang.ClassNotFoundException: scala.math.Ordering$Re
我的pom.xml文件导入依赖的版本为。用2.12.15版本的scala就行。-

- abdgh123456
- 昨天
-
-
NoSQL数据库作为关系型数据库的重要补充,针对不同场景需求分为四大类型:1)K-V存储(如Redis),高效处理复杂数据结构但事务支持有限;2)文档数据库(如MongoDB),提供灵活的无schema存储;3)列式数据库(如HBase),优化大数据分析的I/O效率;4)全文搜索引擎(如Elasticsearch),实现毫秒级文本检索。各类NoSQL数据库分别解决了关系型数据库在数据结构、扩展性、大数据处理和全文搜索方面的短板,实际应用中需根据业务需求选择合适的数据库组合(Not Only SQL),构建高
-

- 佩奇的技术笔记
- 昨天
-
-
本文介绍了Elasticsearch中的聚合查询功能,主要包括指标聚合和桶聚合两种类型。指标聚合用于计算数据的最大值、最小值、平均值等统计指标,而桶聚合则用于对数据进行分组统计。文章通过实际案例演示了terms聚合和sum聚合的组合使用,展示了如何对商品销售数据进行分组并计算每组的销售总量。此外还介绍了max和min聚合的基本用法。作者在学习过程中结合了个人经历,将聚合查询与SQL中的group by和聚合函数进行类比,并表达了将其应用于SpringBoot项目的期待。文末提供了详细的DSL查询示例和结果截
-
- 关沐吖
- 16小时前
数据错误 -
-
基于上述的两点,从 Spark 1.6 开始出现 DataSet,作为 DataFrame API 的一个扩展,是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换,结合了 RDD 和 DataFrame 的优点,至 Spark 2.0 中将 DataFrame 与 DataSet 合并。Spark SQL 的核心是一个叫做 Catalyst 的查询编译器,它将用户程序中的 SQL/DataFrame/Dataset 经过一系列的操作,最终转化为 Spark 系统中执行的 RDD。
-

- zh_19995
- 19小时前
-
-
摘要 该项目为社区老年人开发了一个在线学习平台,采用Spring Boot、MySQL、Redis等技术栈实现课程管理、直播教学等功能。开发者详细解答了面试中涉及的技术问题:Spring Boot简化配置,MyBatis Plus提升开发效率,Redis缓存热门数据,Kafka处理异步审核任务,RTMP优化直播体验。重点阐述了各技术组件的应用场景、解决方案和性能优化策略,如自定义Redis配置、复杂SQL处理、缓存一致性保障等,展现了扎实的技术实践能力。
-

- 程序员岳彬
- 12小时前
-








-

-

要想理解持续集成和持续部署,先要了解它的部分组成,以及各个组成部分之间的关系。下面这张图是我见过的最简洁、清晰的持续部署和集成的关系图。
-

从代码到 Docker、Kubernetes、Istio、Knative……,或许是时候重新思考从代码到云的编程了...
早些时候,开发人员只需编写程序、构建,然后运行。如今,开发人员还需要考虑各种运行方式,作为可执行文件在机器上运行(很有可能是虚拟机),还是打包到容器中;将容器部署到Kubernetes中,还是部署到serverless的环境中或服务网格中。然而,这些部署方式并不是开发人员编程经验的一部分。开发人员必须以某种方式编写代码才能在特定的执行环境中正常工作,因此编程时不考虑这些问题是不行的。
-

-

-
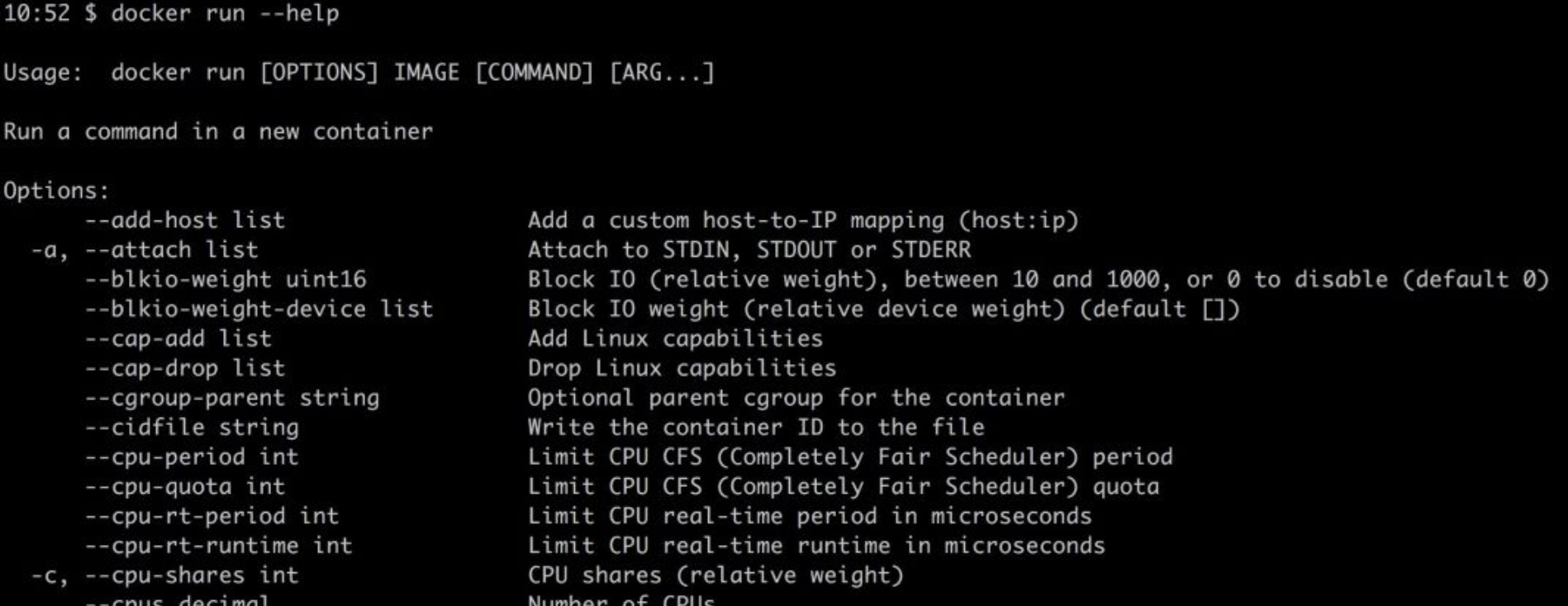
Docker容器已经从一种锦上添花的技术转变成了部署环境的必需品。有时,作为开发人员,我们需要花费大量时间调试或研究Docker工具来帮助我们提高生产力。每一次新技术浪潮来临之际,我们都需要花费大量时间学习。
-
近日,阿里云对外宣布其容器服务调度GPU云服务器启动加速计算,最快只需60秒即可完成新冠病毒的核酸对比工作;同时将向医疗科研机构、疾控中心等一线病毒研究机构免费开放基因计算服务,技术可大幅提升宏基因组测序、疫苗研发相关的处理效率。基于此,晶少专程采访了阿里云基因计算服务AGS负责人、高级技术专家李鹏,集中呈现针对GPU和容器技术大幅提升核酸比对速度的有关细节以及关于阿里云基因计算服务(AGS)的诸多信息。
-

6 个步骤,教你在Ubuntu虚拟机环境下,用Docker自带的DNS配置Hadoop | 附代码
最近,作者整理了一套Hadoop搭建方案。最后的镜像大小1.4G多,使用docker子网,容器重新启动不需要重新配置/etc/hosts文件。 配置过程中参考了如下博客,有些细节问题这些博客里面解释的更加详细。
-

自从Docker在2013年初上线以来,就与程序员及系统管理员之间产生了一种爱恨交加的奇妙关系。虽然与我交谈过的一些经验丰富的的开发人员都非常不喜欢容器化(稍后会详细介绍),但是为什么许多大公司,包括eBay、Twitter、Spotify和Lyft在内,都在他们的生产环境中采用了Docker呢?
-

稳定、可扩展、模块化、简化部署过程、版本控制……一文看懂 Kubernetes 到底如何运用!...
说实话,我是个Kubernetes爱好者。Kubernetes是软件开发的重要一步。当我遇到它时,我就想:“这就是将容器融入生产的方式”。我没有任何犹豫就投入了它的怀抱。有成千上万的架构师像我一样,已经深深爱上这项技术。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
数据错误 -

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

NVIDIA今日宣布,在NVIDIA GPU Cloud (NGC)容器注册上,向交通运输行业开源NVIDIA DRIVE™自动驾驶汽车开发深度神经网络。
-

云改变了IT业态和市场格局,催生了应用大发展的时代,企业可以更加专注于构建符合其愿景的、更具生命力的业务创新。全面使用云服务构建软件的时代已经到来,在这个大背景下,云原生的概念被提出并迅速具象化,而以容器为代表的云原生技术,作为提升云化服务能力的最佳选择,也得以快速发展。
-

四大开源项目联合发布 腾讯已成Github全球贡献前十公司!
近日在Techo开发者大会上,腾讯正式对四大重点开源项目进行了联合发布,包括分布式消息中间件TubeMQ、基于最主流的 OpenJDK8开发的Tencent Kona JDK、分布式HTAP数据库 TBase,以及企业级容器平台TKEStack。
数据错误 -

加速布局无服务器生态,腾讯云与Serverless.com达成全球战略合作!
在云计算技术领域,“Serverless(无服务器)”作为一种新型的软件设计架构正在快速崛起。作为继虚拟机、容器后的第三代通用计算平台,Serverless技术也一直是腾讯云原生的重点发力领域。 近日,在由腾讯云主办的首届Techo开发者大会上,腾讯云宣布与全球最流行的Serverless开发平台Serverless.com达成战略合作,成为 Serverless.com的全球战略合作伙伴以及大中华区独家合作伙伴。截至目前,Serverless.com拥有百万级别的活跃应用程序以及50000+的日下载量。
-

AWS在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。 据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
2019-11-05 -

据晶少了解,国庆假期后的首个工作日,AWS就在中国区域放出了一款“重量级”容器服务,名为 AWS Fargate,光环新网运营的 AWS 中国(北京)区域和西云数据运营的 AWS 中国(宁夏)区域均提供该项服务。据悉这是一款可以适用于 Amazon ECS的计算引擎,主要帮助企业在生产过程中运行容器、却无需部署或者管理服务器,换句话说就是专注设计和构建应用程序,而不用挂心太多基础设施的“那些事儿”。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net