



- 相关博文
- 最新资讯
-
格式优势劣势最佳场景Parquet生态兼容性极广,社区活跃,是业界标准;在 Spark/Presto 上性能优异。不支持 ACID 事务;对 Hive 复杂类型的支持稍弱。绝大多数现代数据湖和分析平台,特别是使用 Spark、Presto/Trino 的技术栈。ORC压缩率更高;原生支持Hive ACID 事务;对 Hive 复杂类型支持极好。生态兼容性略窄于 Parquet;与 Hive 之外的工具集成有时需要额外配置。以 Hive 为中心的数据仓库,需要事务支持或极致压缩的场景。最终建议。
-

- 一号IT男
- 昨天
-
-
Spring Boot集成Kafka的两种方式:1. 自动配置方式:添加spring-kafka依赖并配置application.yml后,自动创建KafkaTemplate和ConsumerFactory;2. 手动配置方式:通过自定义@Configuration类创建ProducerFactory和ConsumerFactory,可设置并发消费数量和提交模式等高级特性。两种方式均支持SASL/SSL安全认证配置,通过@KafkaListener注解实现消息监听处理。
-

- 半__夏
- 19小时前
-
-
摘要:本文系统介绍了标签化任务管理工具的核心价值与选型方法。针对团队协作中常见的任务混乱、优先级模糊问题,标签化工具通过自定义分类、可视化追踪和权责明确来提升效率。文章提出5个选型维度(团队规模、标签灵活性、可视化能力、集成性、成本),并对比了5款主流工具的特点和适用场景(板栗看板、Todoist、Asana、ClickUp、Trello)。最后指出4个常见误区,强调应根据团队实际需求选择工具,避免过度定制或形式化管理。标签化管理的本质是解决问题,而非增加负担。
-

- fzy0085
- 22小时前
-
-
若模型的 tie_word_embeddings 参数设为 True(即词嵌入层与输出层权重绑定),且 tied_target_modules(绑定目标模块列表)中包含 lm_head(语言模型头部,负责最终文本生成或预测的组件),同时该头部又属于适配器(adapter)的一部分,这种配置可能会引发问题。正如我们会在下一节课中详细讲到的,你可能会新增的这些特殊 tokens,大多是用于引导模型行为的提示信息(hints),而且它们基本都属于输入的一部分 —— 而输入正是由(经过适配的)嵌入层来处理的。
-

- 大模型与Agent智能体
- 17小时前
-
-
在现代前端开发中,代码规范是保证项目质量和团队协作效率的关键因素。ESLint负责代码质量检查,Prettier负责代码格式化,两者的完美结合能够为团队提供统一的编码标准。本文将深入探讨如何配置和使用ESLint与Prettier,打造高效的代码规范体系。## 为什么需要统一的代码规范?### 痛点分析- **代码风格不一致**:团队成员使用不同的编码风格,导致代码难以维护- **代码...
-

- 裘晴惠Vivianne
- 昨天
-
-
本文介绍了一个基于Hadoop和Python的租房数据分析与可视化系统,采用Spark、Hadoop、Django、Vue等技术框架开发。系统通过大数据技术分析房源分布、租金水平、交通便利性等核心维度,包含区域分析、交通便利性评估、房源特征分析、市场洞察和租金预测五大模块。前端采用Vue+Echarts实现数据可视化,后端使用Python处理海量租房数据,结合机器学习算法构建预测模型。研究为租房决策提供数据支持,推动租房市场透明化,系统展示部分包含大屏可视化、多维分析页面及核心功能代码片段。
-

- Q2643365023
- 20小时前
-
-
为打破行业壁垒、构建资源互通的高能级平台,ES SHOW 2025创新联合七大产业旗舰展会——包括Automotive World China深圳国际智能网联汽车技术展、S-Factory Expo智能工厂及自动化技术展、VisionChina深圳机器视觉展、NEPCON ASIA亚洲电子生产设备展、C-TOUCH & DISPLAY SHENZHEN全触与显示展、COMMERCIAL DISPLAY商业显示技术以及FILM & TAPE EXPO国际薄膜与胶带展,实现八展协同、共振举办。
-
- 科技热点圈
- 昨天
-









-

-
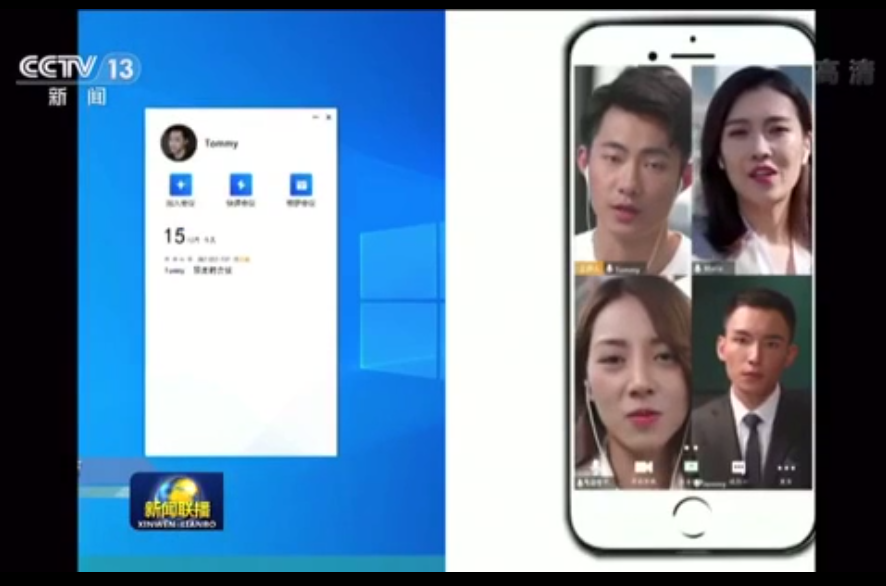
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

-

1月7日,腾讯宣布正式启动“SaaS技术联盟”,联合金蝶、用友、有赞、微盟、销售易、六度人和、道一、肯耐珂萨(KNX)等外部SaaS厂商,以及企业微信、腾讯会议、企点等腾讯内部SaaS产品,共建技术中台。同时,工信部信软司相关领导在发布会上表示,将指导联盟成员开展中国产业互联网发展联盟SaaS技术专委会筹备工作。
-

-

-

“与合作伙伴‘共创’是产业互联网发展最重要的路径,也是最佳的路径。”腾讯公司高级执行副总裁、云与智慧产业事业群总裁汤道生在2019腾讯云启产业生态年会上给出了腾讯的答案。
-

近日腾讯在京举办腾讯云媒体开放日,其中在云游戏专场,腾讯研究院研究员俞点和腾讯视频云业务总经理李郁韬分别进行了分享。俞点指出,腾讯从2016年开始便针对云游戏进行技术开发和积累,进入2019年后云游戏迎来爆发,谷歌Stadia、微软也出了Project xCloud等对应布局的产品走上台前,腾讯也拿出了腾讯云云游戏解决方案。
-
近日腾讯云在北京举行大数据AI新品发布会。会上,腾讯云带来了在大数据与AI领域的最新研究成果,包括AI换脸甄别技术AntiFakes、腾讯星图以及企业画像平台等七大重磅新品,并对AI、大数据产品进行全线升级,致力于为用户带来更精细化的应用场景、更强大的技术能力以及更低的应用成本,全面降低企业AI技术应用门槛。
-

近日在腾讯云AI大数据新品发布会上,腾讯云副总裁王龙向听众全面介绍了当前腾讯云数据智能服务的全景布局。针对目前整体AI行业的发展趋势,他表示过去一招鲜的发展模式已经难以为继,取而代之的是真正能够产生价值的、端到端的、全面的AI解决方案,并且随着技术的不断演进,企业进入和使用数据智能领域的门槛将继续大幅降低。
-

CSDN云计算「C课有道」栏目趁着这股技术风潮再次如期而至啦!秉承「门门有路,路路有门」的理念,这次CSDN云计算小分队特邀阿里云、腾讯云、青云、天云等企业内的“国宝级”架构师,共同打造了一款数据库系列进阶教程,效果绝堪比“红宝书”。 从数据库宏观发展入手,内容主要涉及云数据库为代表的非关系型数据库、MySQL数据处理、分布式等诸多技术要点,将造福开发者设置为终极指标,纯技术绽放的精彩无限,实在不容错过。
-

i 智慧 | 为云而生、多快好省,这就是星星海的style!
不久之前,腾讯云刚刚对外上新了一款服务器,号称深度自研且独一无二,其名字也十二分的卡哇伊,叫做“星星海”。晶少虽然还没来得及探寻其名的出处,不过在与腾讯服务器供应链总经理刘裕勋的谈聊中已基本了解到星星海的重要style之一,为云而生。
-

腾讯Techo开发者大会揭晓云存储发展趋向:高性能、高可用、高性价比
产业数字化转型过程中产生着比过去任何一个时代都多的数据。在这样的背景下,数据存储技术应该怎么发展?11月7日,在腾讯Techo开发者大会上,来自科研领域的专家和腾讯云存储业务的工程师们共同揭开了云存储的发展趋势。
-

不久之前,腾讯云刚刚对外上新了一款服务器,号称深度自研且独一无二,其名字也十二分的卡哇伊,叫做“星星海”。晶少虽然还没来得及探寻其名的出处,不过在与腾讯服务器供应链总经理刘裕勋的谈聊中已基本了解到星星海的重要style之一,为云而生。
-

加速布局无服务器生态,腾讯云与Serverless.com达成全球战略合作!
在云计算技术领域,“Serverless(无服务器)”作为一种新型的软件设计架构正在快速崛起。作为继虚拟机、容器后的第三代通用计算平台,Serverless技术也一直是腾讯云原生的重点发力领域。 近日,在由腾讯云主办的首届Techo开发者大会上,腾讯云宣布与全球最流行的Serverless开发平台Serverless.com达成战略合作,成为 Serverless.com的全球战略合作伙伴以及大中华区独家合作伙伴。截至目前,Serverless.com拥有百万级别的活跃应用程序以及50000+的日下载量。
-

邱跃鹏:软硬件一体化、Serverless、智能化是云计算三大趋势
近日腾讯公司副总裁、腾讯云总裁邱跃鹏在“腾讯Techo开发者”大会上致辞。他表示,云计算未来有三大趋势,即软硬件一体化(Cloud Native Hardware)、无服务器计算(Serverless)和智能化(Smart)。
-

正式开源TKE和TBase,腾讯正成为大数据领域开源全面的厂商
在11月6日召开的Techo开发者大会上,腾讯云副总裁、腾讯数据平台部总经理蒋杰博士正式对外披露腾讯大数据平台10年技术演进历程。经过10年的积累,腾讯大数据平台的算力资源池目前已有超过20万台的规模,每天实时数据计算量超过30万亿条,并且随着资源管理平台核心TKE和分布式数据库TBase正式对外开源,腾讯正在成为大数据领域开源全面的公司。
-

和传统服务器相比,星星海统一的整机方案可以支持不同的CPU主机,前瞻性的高兼容架构,统一规划的硬件底座,可以支持未来3-5年的服务器产品演进。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net