



- 相关博文
- 最新资讯
-
本文是一篇全面的Git进阶教程,重点介绍了远程仓库协作、分支管理和企业级Git工作流。主要内容包括: 远程仓库基础:详细讲解如何注册Gitee/GitHub账号、关联远程仓库、推送/拉取代码,以及配置SSH免密登录。 分支协作:介绍远程分支操作、Pull Request流程、冲突处理方法,以及git stash临时存储和tag版本标签的使用。 Git Rebase:讲解变基操作的原理、使用场景和注意事项,对比rebase与merge的区别。 企业级GitFlow工作流:详细说明5种分支(master/dev
-

- 逆境不可逃
- 昨天
-
-
本文介绍了机器学习中最基础的线性回归模型,通过券商用户续费预测的案例,通俗易懂地讲解了机器学习的基本原理和线性回归的核心概念。文章首先定义机器学习是通过数据自动发现规律并进行预测的过程,然后详细拆解了线性回归模型的组成要素(特征x、权重W、偏差b和预测值ŷ)。重点讲解了两种损失函数(MSE和MAE)的区别及适用场景,以及梯度下降优化算法的基本原理。最后讨论了训练过程中的超参数调整和不可避免的数据噪音问题。全文采用类比和实例说明的方式,适合零基础读者快速理解线性回归这一"机器学习Hello World"的核心
-

- 三毛 H
- 16小时前
-
-
Kafka 精确一次语义是分布式消息可靠性的终极保障。落地建议:第一步,对生产者启用幂等性配置(),防止单分区内消息重复;第二步,对"消费-处理-发送"场景启用事务,将 Offset 提交纳入事务保证原子性;第三步,对"消费-处理"场景使用幂等性消费者,通过去重存储保证业务幂等;第四步,设置合理的事务超时和去重 TTL,平衡一致性和性能。核心原则是"要么全成功,要么全回滚"——事务是精确一次的基石,幂等性是事务的补充。
-

- Dicky张
- 前天
-
-
消息队列面试高频题(2026版)精选20+道 RocketMQ / Kafka 大厂高频面试题,覆盖点对点/发布订阅、消息丢失与重复消费、事务消息、顺序消息、积压治理、ISR 机制、零拷贝、KRaft 模式、Serverless 趋势。每题配标准话术 + 加分项 + 避坑指南,助你轻松应对 MQ 面试,冲击资深后端岗位。
-

- 折哥|智能物流与Java实战
- 17小时前
-
-
本文档系统化整理了软件开发全流程中的关键检查点,分为六大类专项对话索引: 开工与环境类 - 包括项目启动前的环境检查和依赖风险审计 安全与版本控制类 - 涵盖敏感信息排查和Git规范清理 性能与并发类 - 专注于阻塞问题和并发风险排查 日志与可观测性类 - 审计日志系统的完备性 数据与输入类 - 检查输入处理、特殊字符和时间统一性 配置与测试类 - 关注配置治理和测试覆盖率 每个专项都明确了检查范围、重点注意事项和执行原则,形成了一套严谨的工程实践检查清单。
-

- 小空霸kongba007
- 昨天
-
-
淘宝商城数仓分层建设方案采用经典五层架构(ODS→DWD→DWS→ADS),以订单、会员、履约三大核心域为例。ODS层保留原始数据,DIM层构建一致性维度(会员/商品/店铺维等),DWD层按业务过程建模(订单/支付/发货事实表),DWS层按主题聚合(用户/店铺宽表),最终ADS层支撑报表/API等应用场景。方案强调数据标准化(命名规范)、维度退化、数据清洗和分层复用,形成从源数据到应用服务的完整链路。
-

- 瀧爷1939
- 22小时前
-
-
数据仓库分层的核心价值在于通过结构化设计解决复杂性问题。首先,分层架构(ODS→DWD→DWS→ADS)实现处理流程解耦,各层专注单一职责,避免"烟囱式"开发。其次,通过中间层统一指标口径,预计算减少重复加工,提升查询性能与数据一致性。此外,分层设计能有效隔离源系统变更影响,保障下游稳定性,同时建立清晰的数据血缘便于问题追溯。从协作角度看,分层明确了数据工程师、建模师和分析师的职责边界,支持从原始数据到聚合报表的多粒度查询需求。本质上,分层是以空间换时间、规范换效率的系统工程方法,是数仓可持续运维的基础保障
-
- 瀧爷1939
- 22小时前
-
-
数据仓库建模中,ODS层与DWD层的核心区别在于数据组织视角:ODS层按源系统划分(如交易、会员系统),保持原始数据结构和粒度;DWD层则按主题域和业务过程(如下单、支付)重组数据,进行清洗、标准化和粒度调整。关键差异包括: ODS保留源系统结构,DWD以业务需求为导向重构 ODS存在数据冗余,DWD确保单一业务过程对应唯一事实表 DWD层进行数据清洗、脱敏和维度退化等处理 二者紧密关联,DWD必须基于ODS加工,确保数仓与业务系统解耦,同时实现从技术视角到业务视角的转变。
-
- 瀧爷1939
- 21小时前
-
-
数据新概念被不断包装、放大,刻意弱化其背后传统数据管理的本质,营造 “旧架构过时、新架构才是未来” 的焦虑感。
-

- Legend NO24
- 21小时前
-
-
一旦 Leader 收到了过半的 ACK,它就会在本地提交这个事务,更新内存数据,并向所有节点(包括那些还没返回 ACK 的节点)广播一个 Commit(提交)消息。还有一种极端情况:机房 A 的 Leader 只是网络卡顿了(假死),机房 B 的 Follower 以为 Leader 挂了,选出了新 Leader。如果 Leader 把提案广播给了 Follower,也收到了部分 Follower 的 ACK,但还没凑够“过半数”的 ACK,或者凑够了还没来得及发送 COMMIT 消息就宕机了。
-

- Hui Baby
- 昨天
-
-
结合多浏览器使用情况,分析竞品格局与用户忠诚度。1. 拖拽【并行数据处理】节点至画布,在节点配置面板中新增2个处理方法,总计3个处理方法,分别命名为:各浏览器用户数、各浏览器总使用时长、各浏览器人均使用时长。在左侧「文字」分类中选择「通用标题」组件,添加至按钮背景上方,重命名为「市场分析」,匹配背景组件尺寸,修改文字内容、字体、颜色,设置为选中状态样式;3. 样式优化:选中折线图,在数据系列设置中,针对6类浏览器对应的6个图例,分别配置折线、标记点颜色,保证折线、标签、图例颜色统一,提升可视化效果。
-
(2)TuGraph:是一个支持大数据容量,低延迟查找和快读图分析功能的高效图数据库,包含图存储、图计算、图学习、图研发平台的无静的图技术体系,拥有业界领先规模的图集群,解决了图数据分析面临的大数据量、高吞吐率和低延迟等重大挑战。(3)数据集准备:对于一个数据集,关键在于确定其的点、边以及相应的属性,对于非表格型的数据集,还需要通过提炼信息来获得相应的点、边、属性等要素,从而构建表格数据集。”为点,其中“txId”和“class”是点属性,确定“(3)将两个CSV文件的数据进行导入,先导入“
-
- yyy0830
- 23小时前
-
-
本文深度拆解Python链式调用,从基础概念到工业级应用,涵盖5大类链式模型。主要内容包括: 核心分类:区分可变链式(原地修改)和不可变链式(生成新对象),分析各自适用场景及优缺点 底层实现:通过类方法返回self或新实例,详解链式调用的基础规则和常见报错原因 进阶模式: 管道运算符链式(重载__or__),类似LangChain的AI处理流水线 异常安全链式,实现生产级的容错处理 高阶应用: 分析链式调用的内存模型和执行时序 函数式无类链式实现 LangChain的工业级AI链式架构 文章通过大量可运行代
-

- 喵王龙
- 昨天
-
-
Exchange 负责路由,Queue 负责存储,Binding 和 Routing Key 共同决定消息投递到哪里。理解 AMQP 的这一层模型,才能用好 RabbitMQ 的灵活路由能力。碎碎念:后续会更新每天学习的八股和算法 题,开始准备秋招的第30天。努力连续更新100天!以后每天就按,秋招项目【java+agent】,科研,必做项目,算法,八股,锻炼身体来总结。总结:尝试认真学2小时,就有点用脑过度了,不想学习1.算法要系统过一遍【灵神】21/27【早上】1h。
-

- 兰令水
- 昨天
-
-
《升鲜宝AI助手使用指南》摘要: 该指南面向供应链系统用户,介绍AI助手的核心功能与操作流程。AI助手集成于升鲜宝系统,提供九大模块:智能工作台(经营总览)、经营分析、预警中心、报表中心等,支持自然语言查询、自动报表生成、异常预警及智能决策建议。数据基于真实业务表,通过指标中心统一口径。新用户可从经营驾驶舱入门,逐步掌握数据查询、预警处理、报告查看等功能。不同角色(如采购、财务)可聚焦对应模块,需注意数据准确性依赖底层配置。核心价值在于实现业务数据智能化分析与闭环管理。






-

近日,谷歌母公司Alphabet首次公布了谷歌云计算业务的数据,这一举动将云计算行业重新推到了聚光灯下。众所周知,全球云市场竞争激烈,在这场角逐战中,技术与市场能力就是战场上的武器。
-

腾讯会议扩容背后:100万核计算资源全由自研服务器星星海支撑
疫情期间,远程会议及协同办公需求暴增。从1月29日开始到2月6日,腾讯会议每天都在进行资源扩容,日均扩容云主机接近1.5万台,8天总共扩容超过10万台云主机,共涉及超百万核的计算资源投入。
-

当微软前首席软件架构师雷·奥兹(Ray Ozzie)在2008年的PDC大会上发布Windows Azure时,没人能预估这个软件平台将会为该公司和整个行业带来什么样的影响。
-

-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
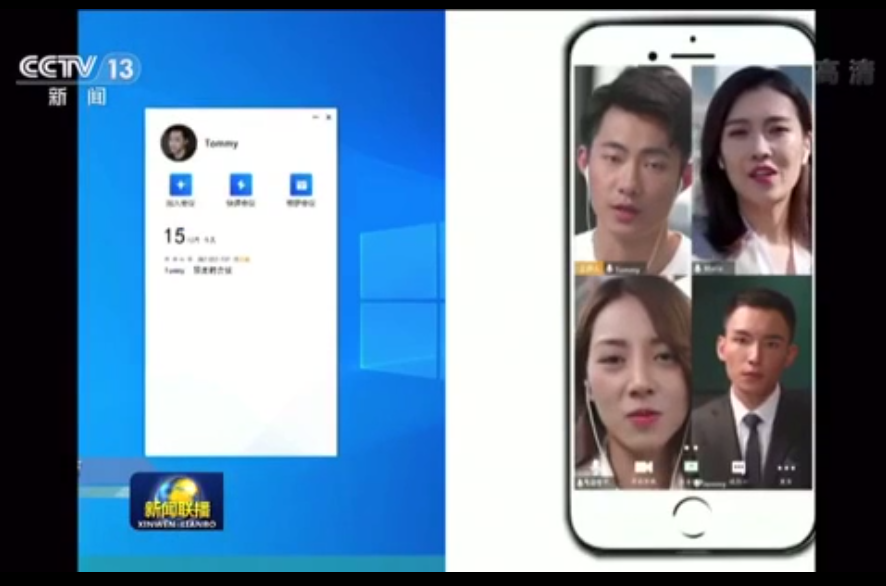
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

2月12日,钉钉已连续在苹果应用商店霸榜7天。记者采访获悉,春节以来,在家办公及在家上课的强需求,使得钉钉后台系统峰值流量暴增百倍。钉钉通过阿里云连续扩容10万台云服务器,成功抗住这一巨大的流量冲击!
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

-

-

微服务架构模式经过5年多的发展,在各行各业如火如荼地应用和实践。如何在企业中优雅地设计微服务架构?是企业面对的一个重要问题。本文将讲述微服务架构1.0设计与实践以及面临问题和破局,最后讲述微服务架构2.0设计与实践等方面,尝试去回答这个难题。
-

-

-

武汉肺炎疫情把远程医疗又推向大家的视线中来。远程医疗作为近年来热度最高的新兴科学之一,融合了医学、通信、信息等领域,对推动我国医疗卫生事业的发展具有重要的战略意义。远程医疗能有效改善医院医疗资源偏态分布的情况,并支持医学互动和会诊降低对时间和空间的要求。
-

伴随5G技术加速落地,云游戏作为5G应用落地的最佳场景,已经成为全球游戏厂商和云服务厂商布局的重要战场。根据艾媒咨询数据显示,2018年中国云游戏市场规模为6.3亿元,而到2023年,市场规模将飙至千亿元。
-

十大类疫情服务紧缺 阿里广发英雄帖抗疫小程序开发者最高可获50万元奖励
全民积极响应国家抗击新冠肺炎疫情的号召,正催生出越来越多新的互联网服务缺口。基于对用户、政府、企事业单位抗疫服务需求的紧缺情况调查,支付宝今日面向社会各界开发者发布“10大疫情期最急需服务开发清单”,号召更多开发者投入进来开发更多服务,解决社会问题。据了解,清单涵盖了口罩预约、疫情上报、社区出入管理、代跑腿、餐饮外卖等疫情防护及便民生活类服务。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

2月3日是一个特殊的开工日,为防范疫情,在阿里巴巴钉钉上有超过1000万家企业组织的2亿上班族在线开工。为支持此次史无前例的办公需求,钉钉在阿里云上紧急扩容1万台云服务器来保障钉钉视频会议、群直播、办公协同等功能,保障用户流畅体验。
-

2月3日,华中科技大学同济医学院基础医学院、华中科技大学同济医学院附属武汉儿童医院、西安交通大学第一附属医院、中科院北京基因组研究所、华为云联合科研团队宣布,筛选出五种可能对2019新型冠状病毒(2019-nCoV)有效的抗病毒药物。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐
关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net