



- 相关博文
- 最新资讯
-
原子性和保证了一系列操作要么全部成功并记录,要么全部被撤销,使数据保持一致。基于变更集: 整个机制不是简单地保存整个文档的快照,而是高效地记录和应用“变更集” (TDF_Delta仅限 TDF 数据: 此机制只对TDF_Data内部的修改有效。任何外部副作用,如写入文件、更新UI、打印日志等,都不会被记录,也无法通过Undo或回滚。堆栈模型Undo和Redo的实现是经典的数据结构——双堆栈模型,一个用于撤销,一个用于重做。
-

- 心瞳几何造型
- 22小时前
-
-
方法一Ubuntu 18.04采用netplan来管理网络配置计划,在/etc/netplan/目录下有一个以yaml结尾的文件,例如00-installer-config.yaml,不同版本的系统这个文件名可能会有些差异,但是不影响,以实际为准。步骤1:先ifconfig查看电脑的网卡信息:找到物理网卡的名称,我这里是ens33,其他几个是虚拟网卡和本地回环,不用管。步骤2:输入route -n命令,打印路由表,这里主要是为了查看网关地址,后续会用到。
-

- 本自具足,莫向外求
- 昨天
-
-
【AI深究】CatBoost深度解析:原理、算法与工程实践——全网最详细全流程详解与案例(附Python代码演示)|集成学习算法细节、数学表达、与其他Boosting算法比较|参调技巧与代码示例可视化
大家好,我是爱酱。本篇延续我上三篇Boosting (XGBoost, LightGBM, AdaBoost),继续去讲解CatBoost(Categorical Boosting)的核心原理、算法细节、数学表达、优缺点、工程实现与实际意义,帮助你全面理解这一经典Boosting算法的本质与应用。注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!-

- 人工智能AI酱
- 16小时前
-
-
【AI深究】LightGBM深度解析:原理、算法与工程实践——全网最详细全流程详解与案例(附详尽Python代码演示)|集成方法核心原理、算法细节数学表达、工程实现与实际意义|参调技巧与代码示例可视化
大家好,我是爱酱。本篇延续爱酱上一篇XGBoost的深究专栏,系统的梳理LightGBM(Light Gradient Boosting Machine)的核心原理、算法细节、数学表达、工程实现与实际意义,帮助你全面理解这一高效、强大的Boosting算法。 注:本文章含大量数学算式、详细例子说明及大量代码演示,大量干货,建议先收藏再慢慢观看理解。新频道发展不易,你们的每个赞、收藏跟转发都是我继续分享的动力!-
- 人工智能AI酱
- 前天
-
-
本文介绍了Hive中JOIN操作的实现与优化方法。首先阐述了Hive的两种JOIN实现方式:CommonJoin和MapJoin,分析了数据倾斜的产生原因。其次详细介绍了四种JOIN类型及其特点:INNER JOIN、LEFT JOIN、RIGHT JOIN和FULL JOIN。接着提出Hive JOIN优化的五大策略:利用MapJoin、分区限制、优先使用LEFT JOIN、避免笛卡尔积和应用谓词下推。最后针对数据倾斜问题,给出了四种解决方案:数据过滤、MapJoin应用、数据分离和数据打散技术。
-

- 乌小云_
- 昨天
-
-
例句1只有1个mr,这个mr却只有1个reduce任务,导致这个reduce任务需要读取和处理大量的数据,这不仅导致执行慢,而且如果表a的数据量太大,可能导致执行reduce任务的节点挂掉。所以,请牢记当对某个数据集进行全局count distinct操作时,尽量用例句2的形式。3、对于各个限制条件,最好一个限制条件对应一个子查询,然后通过left join来联合所有限制条件。5、联表时如果使用到了terminal字段,联表条件中最好带上terminal字段(因为不同表的terminal粒度可能不一样)
-
- 乌小云_
- 昨天
-
-
希望这篇“血泪实录”能让大家少踩坑,让消息队列真正成为系统解耦、流量削峰、提升弹性的利器,而不是数据混乱的源头。监控显示,RabbitMQ在某个时间点出现了短暂的网络抖动,触发了消息重试机制,而我们的消费端...毫无防备!Broker未收到ACK,认为消息未被成功处理,会将该消息(或该Channel上未ACK的所有消息)重新入队(或投递给其他消费者),导致。如果状态不允许(如订单已是“已支付”,又收到“支付成功”消息),可能是重复或非法消息,记录告警并ACK。获取成功才处理,处理完释放锁。
-

- 唐旺旺
- 昨天
-
-
Git 是一个功能强大且灵活的分布式版本控制系统,广泛应用于软件开发、文档管理和 DevOps 流程。随着 DevOps、CI/CD 和协作平台的普及,Git 已成为开发者必备技能。然而,Git 的安装过程并非总是顺利,特别是在不同操作系统(Windows、macOS、Linux)上,开发者可能遇到下载失败、版本不兼容、环境配置错误或权限问题等挑战。
-

- EndingCoder
- 18小时前
数据错误 -
-
摘要:本文介绍了Model Context Protocol(MCP)及其在多模型协作中的应用。MCP是一种促进AI模型间信息交换和上下文共享的协议,通过标准化管理和通信机制提升系统互操作性。文章详细解析了MCP的工作原理、技术架构、优势及典型应用场景(如多模态AI系统和决策支持),并与OpenAI Function Calling进行对比,突出其在复杂协作任务中的灵活性。此外,还推荐了GitHub上高star的MCP工具和Cursor使用技巧,为开发者提供实践指导。
-

- chelzi
- 18小时前
-
-
前言:在分布式系统架构中,消息队列作为数据流转的 “高速公路”,是微服务架构不可或缺的核心组件。RabbitMQ 凭借其稳定的性能、灵活的路由机制和强大的生态支持,成为企业级消息中间件的首选之一。不过,当我们聚焦 CentOS 7 系统时,会发现它的生态适配存在特殊之处 —— 由于系统内核与依赖限制,CentOS 7 最高仅能稳定运行 RabbitMQ 3.9.16 版本,而更高版本的 RabbitMQ(如 4.x)则更适合 CentOS 8/Stream 或 Ubuntu 等较新系统。
-

- Linux运维技术栈
- 19小时前
-
-
这就代表我们这个el-form表单的校验是根据rules来的,而在下面
里我们写了'prop="xxx"',这里的属性为rules里需要校验的字段名,也就是data里定义的。这里我们的表单里有‘活动名称(输入框)’和‘活动区域(下拉框)’两个选项,我们在 这里写了。这个定义的变量是用来动态判断是否需要加校验的,这个值你只需要放在你需要判断是否需要加校验的地方就行了。在使用vue2开发项目的时候使用element组件的el-form大多数情况都需要用到必填项校验。 -

- 攻城狮-申
- 昨天
-
-
单节点模式,部署快捷,能快速投入使用,但也存在很多风险,并不建议大规模生产环境使用,主要问题有:1. 单点风险:一旦某个组件崩溃,整个环境将无法使用,因此生产实践中,logstash和es都是多节点集群模式;2. 消息丢失:当前的ELFK架构,并不具备消息保持的功能,一旦elk环境异常,在恢复异常的这段时间内,所有的推送过来的日志将都会丢失,这在生产实践中是不能容忍的,因此生产实践中,往往会再接入一层消息中间件,比如kafka集群,这样即便elk异常,也能确保日志数据不会丢失。
-

- CloudNative Pilot
- 12小时前
-
- 数据错误
-
Apache StreamPark 作为流处理开发框架和管理平台,可显著提升网络安全态势感知系统中流量分析、设备监控等环节的实时性与智能化水平。
-

- flyair_China
- 23小时前
-
-
问题类型主机解决方案容器解决方案权限问题修改 rabbitmq 用户权限设置目录为 999:999端口冲突杀进程 + 调优内核参数清理容器 + 检查主机端口数据残留清理 /var/lib/rabbitmq清理挂载目录内容日志分析docker logs + 挂载日志目录灾难恢复备份 mnesia 目录备份挂载的 data 目录三维故障定位权限问题:检查权限端口冲突:排查 5672、15672、25672 端口状态和 TIME_WAIT数据残留:清理mnesia目录下的.pid。
-

- 代码怪兽大作战
- 昨天
-
-
RabbitMQ消息持久化机制解析 RabbitMQ通过持久化特性解决消息丢失问题,包括交换机、队列和消息三个层面的持久化设置。交换机持久化通过durable参数设置,队列持久化使用durable()或nonDurable()方法声明,消息持久化则通过MessageDeliveryMode指定PERSISTENT/NON_PERSISTENT。三者组合效果不同:仅当队列和消息都持久化时,重启后消息才会保留;非持久化队列中的消息即使设置为持久化也会丢失。合理配置这三个层级的持久化策略,才能有效保障消息可靠性。
-

- Bug退退退123
- 13小时前
-






-

近日,谷歌母公司Alphabet首次公布了谷歌云计算业务的数据,这一举动将云计算行业重新推到了聚光灯下。众所周知,全球云市场竞争激烈,在这场角逐战中,技术与市场能力就是战场上的武器。
-

腾讯会议扩容背后:100万核计算资源全由自研服务器星星海支撑
疫情期间,远程会议及协同办公需求暴增。从1月29日开始到2月6日,腾讯会议每天都在进行资源扩容,日均扩容云主机接近1.5万台,8天总共扩容超过10万台云主机,共涉及超百万核的计算资源投入。
-

当微软前首席软件架构师雷·奥兹(Ray Ozzie)在2008年的PDC大会上发布Windows Azure时,没人能预估这个软件平台将会为该公司和整个行业带来什么样的影响。
-

-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
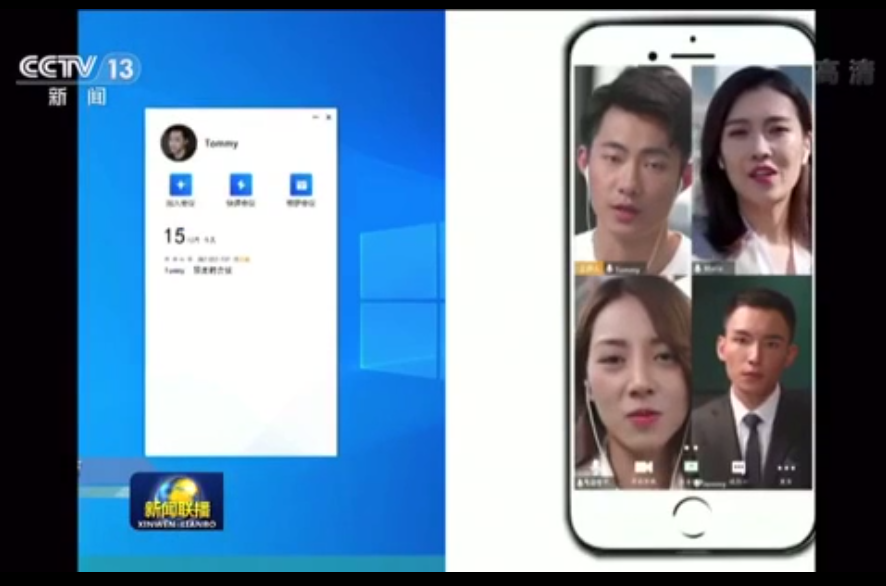
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

2月12日,钉钉已连续在苹果应用商店霸榜7天。记者采访获悉,春节以来,在家办公及在家上课的强需求,使得钉钉后台系统峰值流量暴增百倍。钉钉通过阿里云连续扩容10万台云服务器,成功抗住这一巨大的流量冲击!
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

-

-

微服务架构模式经过5年多的发展,在各行各业如火如荼地应用和实践。如何在企业中优雅地设计微服务架构?是企业面对的一个重要问题。本文将讲述微服务架构1.0设计与实践以及面临问题和破局,最后讲述微服务架构2.0设计与实践等方面,尝试去回答这个难题。
-

-

-

武汉肺炎疫情把远程医疗又推向大家的视线中来。远程医疗作为近年来热度最高的新兴科学之一,融合了医学、通信、信息等领域,对推动我国医疗卫生事业的发展具有重要的战略意义。远程医疗能有效改善医院医疗资源偏态分布的情况,并支持医学互动和会诊降低对时间和空间的要求。
-

伴随5G技术加速落地,云游戏作为5G应用落地的最佳场景,已经成为全球游戏厂商和云服务厂商布局的重要战场。根据艾媒咨询数据显示,2018年中国云游戏市场规模为6.3亿元,而到2023年,市场规模将飙至千亿元。
-

十大类疫情服务紧缺 阿里广发英雄帖抗疫小程序开发者最高可获50万元奖励
全民积极响应国家抗击新冠肺炎疫情的号召,正催生出越来越多新的互联网服务缺口。基于对用户、政府、企事业单位抗疫服务需求的紧缺情况调查,支付宝今日面向社会各界开发者发布“10大疫情期最急需服务开发清单”,号召更多开发者投入进来开发更多服务,解决社会问题。据了解,清单涵盖了口罩预约、疫情上报、社区出入管理、代跑腿、餐饮外卖等疫情防护及便民生活类服务。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

2月3日是一个特殊的开工日,为防范疫情,在阿里巴巴钉钉上有超过1000万家企业组织的2亿上班族在线开工。为支持此次史无前例的办公需求,钉钉在阿里云上紧急扩容1万台云服务器来保障钉钉视频会议、群直播、办公协同等功能,保障用户流畅体验。
-

2月3日,华中科技大学同济医学院基础医学院、华中科技大学同济医学院附属武汉儿童医院、西安交通大学第一附属医院、中科院北京基因组研究所、华为云联合科研团队宣布,筛选出五种可能对2019新型冠状病毒(2019-nCoV)有效的抗病毒药物。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net