



- 相关博文
- 最新资讯
-
本文详细介绍了Hadoop分布式系统搭建及HBase数据库配置的操作流程。首先通过创建3台虚拟机(v1、v2、v3)完成网络配置和主机名设置,实现v1免密登录其他节点。随后安装配置JDK、Hadoop和Zookeeper环境,包括核心配置文件的修改和环境变量设置。第二部分重点演示了HBase分布式数据库的安装与操作,包括创建major表(含inf和other两个列族)、数据插入/查询/删除操作,以及表结构的修改(设置单元格数目、删除列族、设为只读)和最终的删除验证。整个实验完整展示了从系统搭建到数据库操作的
-

- 无限-无畏
- 昨天
-
-
摘要:本文介绍了使用Anaconda创建Python虚拟环境并部署PySpark任务的完整流程。首先在本地安装Anaconda并创建指定Python版本的虚拟环境(如Python 3.7),调试PySpark脚本确保单机运行正常。然后将虚拟环境打包为zip文件,与脚本一起上传至HDFS。最后通过spark-submit命令提交任务,其中关键配置包括指定虚拟环境路径、Python解释器路径以及各类资源参数(内存、核心数等)。文末还提供了常用Spark参数说明(如driver/executor资源配置)
-

- C.R.xing
- 昨天
-
-
举个例子,如果第一条消息A过期时间30秒,第二条消息B过期时间10秒,即便消息B先过期了,基于RabbitMQ TTL的。3,队列A没有消费者,这样队列A中的消息会在TTL到期时自动经过死信交换机转发到死信队列B。如上所述,消息过期会被转发到死信队列,这样我们可以按照以下步骤实现延迟队列。4,消息会在交换机中等待到达延迟时间后再路由到绑定队列。1,创建普通队列A,设置消息TTL,没有消费者。机制,也是消息A进入死信队列后,才会检查消息B。4,消费者监听死信队列B,实现延迟消费。2,给队列A设置死信交换机。
-
- 秦小郎
- 前天
-
-
本文将介绍Java方向与Elasticsearch(ES)的集成应用。ES是一款分布式搜索分析引擎,具有实时搜索、高性能等特点。文章首先概述ES核心概念如文档、索引、分片等,然后详细讲解Java客户端API的两种类型(低级和高级REST客户端),以及通过Maven添加依赖和配置连接的具体步骤。接着提供了Java操作ES的代码示例,包括创建索引、插入数据和查询数据的关键API使用。全文旨在帮助Java开发者快速掌握ES集成与应用技术。
-
- 编程界的彭于晏qaq
- 昨天
-
- 数据错误
-
针对 Elasticsearch 6.8.23 在 Kubernetes 中运行、每节点 64GB 内存、曾出现 OOM 的情况,分析内存使用过高的原因,并提供一份详细的优化建议清单,内容将包括配置参数建议(如 jvm.options、elasticsearch.yml、limits.conf 以及 Pod 配置)。综上,在每节点64GB可用内存情形下,可以考虑将堆调整到约30GB(Xms=30g, Xmx=30g),剩余约34GB留给操作系统缓存和其他非堆用途。同时,应在容器启动脚本或宿主机设置。
-

- 喝醉酒的小白
- 19小时前
-
-
解决 docx文档 复杂表格合并问题
-
本文介绍了如何在本地部署阿里Qwen3大模型并连接到Elasticsearch实现RAG应用。主要内容包括: 创建Elasticsearch API key获取访问凭证 编写Python代码实现RAG流程,包括Elasticsearch查询、上下文构建和Qwen3模型调用 配置环境变量和证书,确保代码正常运行 测试Qwen3模型接口工作正常 修改代码适配最新Elasticsearch版本的数据结构 最终成功运行示例查询"哪些人在茶会",Qwen3准确识别出故事中的角色并给出详细回答 文章
- 数据错误
-
函数是组织好的、可重复使用的,用来实现单一、或相关功能的代码段。函数可以提高应用的模块性和代码的可重复性。python 有许多内置的函数比如 print 打印函数,python 也支持用户实现自己的函数,这类函数也称之为自定义函数。定义一个函数需要遵循以下规则:函数代码块以def关键词开头,后接函数标识符名称和圆括号()。任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。函数的第一行语句可以选择性地使用文档字符串 — 用于存放函数说明。函数内容以冒号。
-

- 程序员水冠
- 昨天
-
-
基于上述的项目背景和难点, 最终决定采用 Spark,首先数据量大及计算方式复杂, 如果使用传统的服务方式, 需要大量的服务器资源, 而目录不固定, 使数据读取变的复杂, 且普通服务不太可能在 4h 内处理完毕;2、 Drvier 的字节级别代码会分发至将要执行的 Executor 上, 这些计算过程实际上是在每个节点本地计算并完成,每个spark会在集群中有一个或多个Executor,Executor 之间也可能会有数据的传输,比如一些聚合函数执行。过少,并行度不足,任务处理数据量大,影响作业完成时间;
-

- 阳光下是个孩子
- 昨天
-
-
让我们以开放的心态拥抱变化,同时保持警惕,确保技术为人类福祉服务。产品个性化率超80%。工业化的特点是批量化、标准化(标品),只有标品,才能批量生产,才能提高效率,降低成本;数字化时代的特点是个性化、定制化(订制品)!5G将覆盖全球90%的人口,6G技术开始试点,实现毫秒级延迟和TB级传输速度。2100年前,人类将在火星建立永久定居点,开启星际殖民时代。22世纪,人类意识将实现数字化上传,实现“数字永生”。面对全球性挑战,人类将成立世界政府,协调各国行动。2045年前,AI将超越人类智能,引发技术奇点。
-

- 文火冰糖的硅基工坊
- 昨天
-
-
面试突击指南:高效备战Java岗位 针对Java面试,建议分三梯队学习:第一梯队(核心必会)包括Java基础、Spring框架、数据库和微服务,需精通原理并能手写代码;第二梯队(竞争力提升)涵盖Docker、Git、Kafka等工具,需熟悉应用场景;第三梯队(加分项)如设计模式、监控工具等,了解概念即可。 突击技巧:整理高频面试题(如String不可变性、Spring事务原理),模拟面试练习,克服紧张。心态上避免完美主义,优先掌握核心技能,遇到不会的问题可引导至熟悉领域。抓重点+实战,足以应对初/中级岗位。
-

- Jasmine65590
- 昨天
-









-

近日,谷歌母公司Alphabet首次公布了谷歌云计算业务的数据,这一举动将云计算行业重新推到了聚光灯下。众所周知,全球云市场竞争激烈,在这场角逐战中,技术与市场能力就是战场上的武器。
-

腾讯会议扩容背后:100万核计算资源全由自研服务器星星海支撑
疫情期间,远程会议及协同办公需求暴增。从1月29日开始到2月6日,腾讯会议每天都在进行资源扩容,日均扩容云主机接近1.5万台,8天总共扩容超过10万台云主机,共涉及超百万核的计算资源投入。
-

当微软前首席软件架构师雷·奥兹(Ray Ozzie)在2008年的PDC大会上发布Windows Azure时,没人能预估这个软件平台将会为该公司和整个行业带来什么样的影响。
-

-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
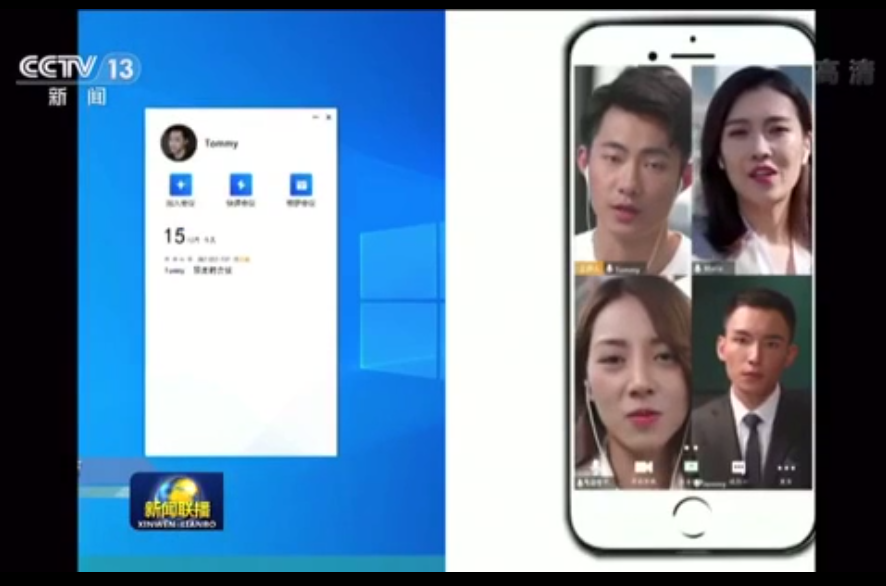
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

2月12日,钉钉已连续在苹果应用商店霸榜7天。记者采访获悉,春节以来,在家办公及在家上课的强需求,使得钉钉后台系统峰值流量暴增百倍。钉钉通过阿里云连续扩容10万台云服务器,成功抗住这一巨大的流量冲击!
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

-

-

微服务架构模式经过5年多的发展,在各行各业如火如荼地应用和实践。如何在企业中优雅地设计微服务架构?是企业面对的一个重要问题。本文将讲述微服务架构1.0设计与实践以及面临问题和破局,最后讲述微服务架构2.0设计与实践等方面,尝试去回答这个难题。
-

-

-

武汉肺炎疫情把远程医疗又推向大家的视线中来。远程医疗作为近年来热度最高的新兴科学之一,融合了医学、通信、信息等领域,对推动我国医疗卫生事业的发展具有重要的战略意义。远程医疗能有效改善医院医疗资源偏态分布的情况,并支持医学互动和会诊降低对时间和空间的要求。
-

伴随5G技术加速落地,云游戏作为5G应用落地的最佳场景,已经成为全球游戏厂商和云服务厂商布局的重要战场。根据艾媒咨询数据显示,2018年中国云游戏市场规模为6.3亿元,而到2023年,市场规模将飙至千亿元。
-

十大类疫情服务紧缺 阿里广发英雄帖抗疫小程序开发者最高可获50万元奖励
全民积极响应国家抗击新冠肺炎疫情的号召,正催生出越来越多新的互联网服务缺口。基于对用户、政府、企事业单位抗疫服务需求的紧缺情况调查,支付宝今日面向社会各界开发者发布“10大疫情期最急需服务开发清单”,号召更多开发者投入进来开发更多服务,解决社会问题。据了解,清单涵盖了口罩预约、疫情上报、社区出入管理、代跑腿、餐饮外卖等疫情防护及便民生活类服务。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

2月3日是一个特殊的开工日,为防范疫情,在阿里巴巴钉钉上有超过1000万家企业组织的2亿上班族在线开工。为支持此次史无前例的办公需求,钉钉在阿里云上紧急扩容1万台云服务器来保障钉钉视频会议、群直播、办公协同等功能,保障用户流畅体验。
-

2月3日,华中科技大学同济医学院基础医学院、华中科技大学同济医学院附属武汉儿童医院、西安交通大学第一附属医院、中科院北京基因组研究所、华为云联合科研团队宣布,筛选出五种可能对2019新型冠状病毒(2019-nCoV)有效的抗病毒药物。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net