



- 相关博文
- 最新资讯
-
摘要: 本文介绍了一个基于大数据技术的痴呆症预测与数据可视化分析系统。系统采用Hadoop+Spark架构进行分布式数据处理,后端使用Django/Spring Boot框架,前端结合Vue与Echarts实现交互式可视化。通过整合多源医疗数据,利用Spark SQL和机器学习模型进行特征分析与风险预测,最终以图表形式展示痴呆症发病趋势及人群特征分布。系统为研究人员、医生和管理者提供了一体化数据分析平台,支持从数据清洗到模型预测的全流程处理,提升了痴呆症早期筛查和辅助决策的效率。
-

- IT研究室
- 昨天
-
-
日常公司大量同事使用sq查询统计数据,基于这个背景,上级要求可以在sql中通过传入必要参数,去查询公司网站上的符合一定条件的最低价,比如传入用户uid、入住日期、离店日期、酒店ID,能够返回符合条件的最低价。1、通过调用公司网站接口,爬取相关条件数据,难点爬取相关数据后转为datafram,然后通过datafram过滤符合条件房型价格,最终返回最低价(解析网站数据结构相对较复杂)2、用python编写udf,udf中读取sql传入参数,并调用1的方案,最终将返回值返回。
-

- yipiantian
- 昨天
-
-
在大数据时代,数据已成为企业的核心资产,数据技能也变成了职场人士的必备能力。无论是技术岗位还是业务岗位,掌握数据分析能力都能为职业发展带来显著优势。推荐考过CDA数据分析师,CDA数据分析师的含金量高,适应了大数据时代的技能要求,企业认可度高,对职业提升非常有帮助。本文将为您系统介绍2025年值得考取的证书,并提供清晰的进阶路径规划。
-
- jiaozi_zzq
- 昨天
-
-
导师从不告诉你的秘密:为什么Spark+Hadoop的毕设题目最容易拿优?
-

- A 计算机毕业设计-小途
- 前天
-
-
为什么:大数据时代,传统数据中台的本地部署为什么不够用?怎么做:数据中台如何通过云化部署解决“弹性、成本、效率”问题?范围覆盖:数据中台云化的核心概念、架构设计、实战步骤、工具选择,以及未来趋势。故事引入:用“餐厅中央厨房搬家”类比数据中台云化;核心概念:把“数据中台”“云化部署”“弹性伸缩”变成“厨房”“共享空间”“可调节灶台”;架构设计:画一张“云化数据中台的积木图”,告诉你每块积木的作用;实战步骤:用“电商实时推荐”案例,手把手教你搭一个云化数据中台;未来趋势。
-
例如 insert后面没跟select ,或者 create view table1 as 后面没跟select。这个bug其实很好理解,就是 他说sql解析错误,没有查询操作,也就是你应该有select 的地方没有select。
-
想象你经营着一家网红奶茶店:当顾客排队超过10人时,你需要立即调配更多员工;当某款奶茶原料只剩5杯库存时,要马上通知仓库补货;当发现下午3点学生群体突然增多时,得临时推出学生优惠。这些决策如果等打烊后看报表再做,顾客早就流失了——实时数据洞察就是企业的"即时反应神经",让数据从"历史记录"变成"行动信号"。本文聚焦大数据领域中实时数据洞察的技术架构与实现方法数据如何从产生到分析实现"秒级响应"?实时数据架构需要哪些关键组件,如何协同工作?不同业务场景(如电商、金融、制造)如何落地实时洞察?
-

- AI大数据智能洞察
- 前天
-
-
但这种能力的背后,是海量数据的生成与存储挑战。更重要的是,它采用了多通道并行架构,即使某条通道因辐射受损,其余通道依旧能维持整体带宽,让数据传输不中断。它通过复合屏蔽层与低LET设计,将单粒子效应的触发阈值降低至0.6 MeV·cm²/mg以下,并通过中子与质子试验验证,确保在强辐射环境中依旧稳定。此外,它还内置三级冗余机制,并结合RAID与LDPC智能纠错算法,实现了多层次的容错保护。如果遇到突发情况,比如突然断电,X55还能通过断电自恢复机制迅速恢复,并导出完整Coredump数据,供地面工程师分析。
-
- 全国产SSD
- 昨天
-
-
业务系统像“烟囱”,电商、CRM、ERP的数据各玩各的,想查用户全链路行为得跑3个系统导出Excel拼接;数据团队天天做“报表机器”,业务部门要个“复购率”得等3天,结果出来时活动都结束了;老板问“怎么用数据涨销量”,技术团队说“我们有Hadoop集群”,业务团队说“我要的是能直接用的用户偏好”——两边鸡同鸭讲。这不是技术的错,而是数据没有“对齐业务增长的逻辑”。数据中台的本质,就是把分散的“数据碎片”变成可复用的“增长燃料”,让技术和业务用同一种语言对话。
-

- AI算力网络与通信
- 昨天
-
-
在多系统环境下,管理跨系统的主数据是企业数字化转型的基石。通过建立统一的数据模型、实施数据清洗、实现实时同步和提供可追溯的审计功能,企业可以有效打破数据孤岛,提升运营效率和决策质量。集成平台方案如KPaaS通过其灵活的主数据管理能力,为企业提供了从单一系统到独立数据中心的多种解决方案,帮助企业轻松应对复杂的数据管理挑战。无论是初次尝试数据整合的中小企业,还是业务复杂的大型企业,借助合适的工具和策略,主数据管理都能为企业带来显著的业务价值。












-
近日,阿里云对外宣布其容器服务调度GPU云服务器启动加速计算,最快只需60秒即可完成新冠病毒的核酸对比工作;同时将向医疗科研机构、疾控中心等一线病毒研究机构免费开放基因计算服务,技术可大幅提升宏基因组测序、疫苗研发相关的处理效率。基于此,晶少专程采访了阿里云基因计算服务AGS负责人、高级技术专家李鹏,集中呈现针对GPU和容器技术大幅提升核酸比对速度的有关细节以及关于阿里云基因计算服务(AGS)的诸多信息。
-

日前,ASPLOS 2020公布了计算机界最新科技成果,其中包括阿里云提交的名为《High-density Multi-tenant Bare-metal Cloud》的论文,该论文阐述了阿里云自研的神龙服务器架构如何解决困扰云计算行业多年的虚拟化性能损耗问题,打破物理机的性能神话,让云服务器突破性能极限。
-

让服务器突破性能极限 阿里云神龙论文入选计算机顶会ASPLOS
日前,ASPLOS 2020公布了计算机界最新科技成果,其中包括阿里云提交的名为《High-density Multi-tenant Bare-metal Cloud》的论文,该论文阐述了阿里云自研的神龙服务器架构如何解决困扰云计算行业多年的虚拟化性能损耗问题,打破物理机的性能神话,让云服务器突破性能极限。此次入选意味着全球计算机顶会对阿里云自研技术的认可,也意味着中国创新技术在全球计算机界争得了一席之地。
-
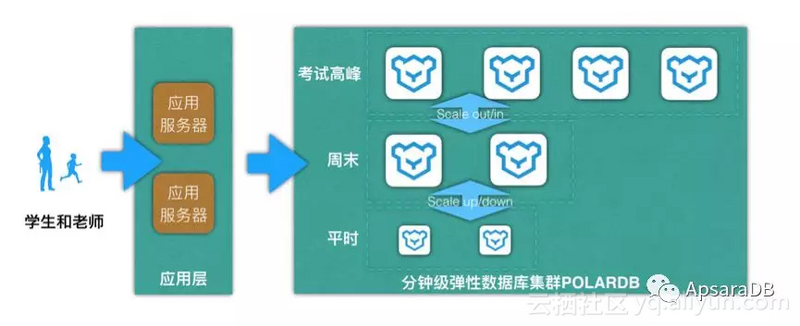
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

2月18日,阿里云在官网宣布,河源数据中心正式对外提供服务。这是华南地区规模最大的绿色数据中心,可容纳超过30万台服务器,作为深圳地域的新可用区为华南地区上百万企业客户提供领先的云计算、人工智能、物联网等服务。
-

2月12日,钉钉已连续在苹果应用商店霸榜7天。记者采访获悉,春节以来,在家办公及在家上课的强需求,使得钉钉后台系统峰值流量暴增百倍。钉钉通过阿里云连续扩容10万台云服务器,成功抗住这一巨大的流量冲击!
-

2月3日是一个特殊的开工日,为防范疫情,在阿里巴巴钉钉上有超过1000万家企业组织的2亿上班族在线开工。为支持此次史无前例的办公需求,钉钉在阿里云上紧急扩容1万台云服务器来保障钉钉视频会议、群直播、办公协同等功能,保障用户流畅体验。
-

云改变了IT业态和市场格局,催生了应用大发展的时代,企业可以更加专注于构建符合其愿景的、更具生命力的业务创新。全面使用云服务构建软件的时代已经到来,在这个大背景下,云原生的概念被提出并迅速具象化,而以容器为代表的云原生技术,作为提升云化服务能力的最佳选择,也得以快速发展。
-
雅士利牵手阿里云实现新零售改造,双11全渠道成交金额同比增长超过200%
12月3日在阿里云峰会·广州站上,雅士利分享了与阿里云的合作,借助数据中台实现新零售改造。在刚刚结束的天猫双11中,雅士利旗舰店整体线上交易同比增长超3倍,旗下羊奶粉品牌“朵拉小羊”50秒成交额超越618全天成交总额,朵拉小羊3段成交订单全网第一,消费者资产实现10倍增长。
-

12月3日,广东省农村信用社联合社银信中心副总裁周丹在2019年阿里云广东峰会上透露,通过携手阿里云,广东农信实现了从传统架构向云化的转型升级,金融业务系统的搭建工期从按月计算缩短至按天计算,效率大幅提升。
-

12月3日,广州云峰会上,阿里云宣布推出面向混合云场景的CPFS一体机和视觉AI一体机,两款新品具备超高性能、开箱即用等特性,极大降低企业上云的周期和门槛。加上此前推出的POLARDB数据库一体机和蚂蚁mPaaS一体机,阿里云已为客户提供了四款一体机家族产品,集结了云、网、边、端一体化的能力,打破云的边界,让企业能够随时随地全栈、全态、甚至全域上云。
-

阿里云提出“云+Fintech”新金融战略 已助上万家金融机构上云
12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

12月3日,阿里云峰会广东期间,阿里巴巴副总裁、阿里云智能数字政府事业部总裁许诗军表示,目前阿里云已成为中国数字政府大数据整体市场第一,也是数字政府大数据基础平台软件市场第一。
-

12月3日,在阿里云广东峰会上,阿里云联合超图软件、长光卫星、Maxar技术、四维测绘等顶级卫星影像产业链公司发布数字地球引擎,提供开放式的影像数据集、遥感AI能力、丰富的API接口等,在国土资源监管、水利河道治理、自然环境保护和农业估产等领域帮助政府和企业提升效率。
-

12月3日,阿里云广东峰会期间,大横琴科技公司联合阿里云发布了全国首个跨境服务创新平台。基于该平台,全国首个跨境服务APP“琴澳通”也正式发布。“琴澳通”将为澳门企业及个人提供服务,推动澳门和广东两地的产业经济联动,数字化升级。
-

“我们希望帮助工厂从原来的单点变成全产业链、全价值链、全要素的融合,变成数字化智能化的工厂,并为工业产品带来智能化。”库伟表示。
-

12月3日,在2019阿里云广东峰会上,阿里云智能总裁张建锋表示,全面迈入数字经济时代,数据成为社会经济发展的新生产要素,云智能是新基础设施。
-

11月28日,阿里云正式开源机器学习平台 Alink,这也是全球首个批流一体的算法平台,旨在降低算法开发门槛,帮助开发者掌握机器学习的生命全周期。
-

近日,开源数据库厂商MongoDB与阿里云在北京达成战略合作,作为合作的第一步,最新版MongoDB 4.2数据库产品正式上线阿里云平台。
-

CSDN云计算「C课有道」栏目趁着这股技术风潮再次如期而至啦!秉承「门门有路,路路有门」的理念,这次CSDN云计算小分队特邀阿里云、腾讯云、青云、天云等企业内的“国宝级”架构师,共同打造了一款数据库系列进阶教程,效果绝堪比“红宝书”。 从数据库宏观发展入手,内容主要涉及云数据库为代表的非关系型数据库、MySQL数据处理、分布式等诸多技术要点,将造福开发者设置为终极指标,纯技术绽放的精彩无限,实在不容错过。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net