



- 相关博文
- 最新资讯
-
特别推荐人工智能、计算机、智能科学与技术、软件工程、大数据、网络工程、自动化、通信、电子信息、数字媒体技术、电子信息工程、数据科学、统计、数学、物理、信管、金融科技、生。旨在联合高校、企业资源和开源社区力量,为学习者提供项目实践和学习机会,提升他们的专业能力和就业竞争力。AI秋训营是Datawhale在秋季发起的大规模AI学习活动,“至小有内,至大无外”的通用目的技术,其教育实践的发展轨迹。,高校和企业始终作为关键力量深度参与其中。只要你对AI方向感兴趣,有热情。AMD、浪潮信息,上智院等。
-

- Datawhale
- 昨天
-
-
Spring的依赖注入机制通过配置文件或注解,将对象间的依赖关系交由Spring容器管理,通过构造器、setter方法或接口注入实现。设计模式是软件开发中常见的解决方案,包括单例模式、工厂模式、观察者模式等,用于解决开发过程中遇到的常见问题。Java中的线程池通过Executor框架实现,提供了线程的复用与管理,避免频繁创建和销毁线程带来的开销。在一个阳光明媚的下午,谢飞机走进了一家互联网大厂的面试室,迎接他的是一位看起来相当严肃的面试官。线程池啊,就是为了重用线程,避免创建销毁的开销对吧……
-

- m0_64196716
- 昨天
-
-
4年,不算短也不算长,有同学从大一开始关注涤生跟着学习到毕业上岸。有人从小白转行到现在大数据架构师;也有人从观望还是停留在观望,也有人一直在守候。1.4年的蜕变与沉淀 4年,涤生大数据微信公众号更新了394篇大数据相关的文章;4年,涤生发布了299个大数据相关技术视频;4年,涤生的课程更新到了第3版;4年,涤生哥接待服务了10000+小伙伴的免费咨询并且给出建议;4年,涤生从1000个粉丝,到现在全网15w+粉丝;4年,涤生辅导上岸700+大数据学员,200+同学入职中大厂。
-

- 涤生大数据
- 昨天
-
-
因此,HR管理系统的选型和建设,成为集团企业数字化转型的重要一环。本文围绕大型多元业务集团企业的人力资源管理系统选型与评测,深度解析5款支持多业务协同的主流HR管理系统,包文章聚焦系统功能、协同能力、供应商实力、技术路线、部署模式及行业应用案例,并给出集团企业在数字化转型和HR系统选型中的实用建议,助力企业实现高效人力资源管理和业务协同。以“人才管理驱动组织成功”为核心,北森提供涵盖招聘、绩效、培训、继任管理、员工关系、薪酬福利、组织发展等全模块SaaS产品,支持集团型企业多组织、多业务场景协同。
-
- qyz_hr
- 14小时前
-
-
梯度函数:核心为“沿着最陡的方向下降移动”,过梯度向量来指示函数增长最快的方向,而梯度的反方向便是下降最快的方向,每次迭代都是从负梯度方向移动一个固定或自适应的步长,直至梯度趋于0。相对熵(KL散度):用于度量两个分布的差异,其典型使用场景是用来度量理想分布和模拟分布之间的差异→与理想分布最接近的模拟分布即为最优分布,所以求出最优分布的目的即为最小化相对熵,等价于最小化交叉熵。1. 模型:线性模型,输出值的范围为[0,1] ,近似阶跃的单调可微函数。优势:算法简洁,仅需求一阶导数,可用于处理大数据。
-

- 埃瑞llric
- 9小时前
-
-
计算机毕业设计Python+AI大模型智能路线规划数据分析与个性化推荐系统 旅游路线推荐系统 旅游路线规划系统 大数据毕业设计
-

- B站计算机毕业设计大学
- 昨天
-
-
配置./etc/hadoop下的core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers。集群遇到故障需要重新格式化的时候 停止集群、删除 ./logs ./data下的内容 再格式化。0、准备好jdk、免密登录、zk等前提环境。mapred-site.xml内容如下。core-site.xml内容如下。hdfs-site.xml内容如下。yarn-site.xml内容如下。2、下载并安装hadoop。worksers内容如下。
-

- 梁-大数据开发
- 昨天
-










-

近日,谷歌母公司Alphabet首次公布了谷歌云计算业务的数据,这一举动将云计算行业重新推到了聚光灯下。众所周知,全球云市场竞争激烈,在这场角逐战中,技术与市场能力就是战场上的武器。
-

腾讯会议扩容背后:100万核计算资源全由自研服务器星星海支撑
疫情期间,远程会议及协同办公需求暴增。从1月29日开始到2月6日,腾讯会议每天都在进行资源扩容,日均扩容云主机接近1.5万台,8天总共扩容超过10万台云主机,共涉及超百万核的计算资源投入。
-

当微软前首席软件架构师雷·奥兹(Ray Ozzie)在2008年的PDC大会上发布Windows Azure时,没人能预估这个软件平台将会为该公司和整个行业带来什么样的影响。
-

-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
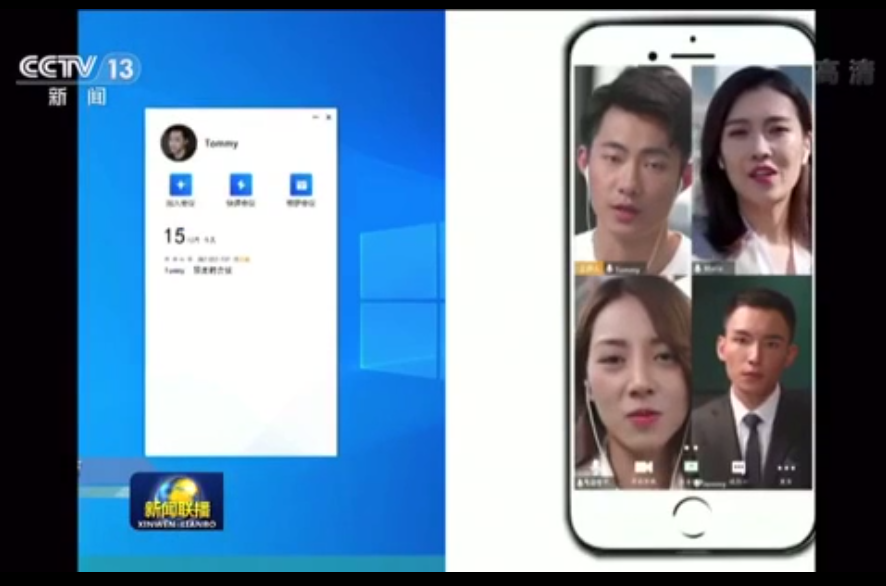
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

2月12日,钉钉已连续在苹果应用商店霸榜7天。记者采访获悉,春节以来,在家办公及在家上课的强需求,使得钉钉后台系统峰值流量暴增百倍。钉钉通过阿里云连续扩容10万台云服务器,成功抗住这一巨大的流量冲击!
-

开展人工智能和机器学习项目的人很早就知道,机器学习项目不是应用程序开发项目。机器学习项目的大部分价值在于模型、训练数据和配置信息,这些信息指导模型如何应用于特定的机器学习问题。
-

-

-

微服务架构模式经过5年多的发展,在各行各业如火如荼地应用和实践。如何在企业中优雅地设计微服务架构?是企业面对的一个重要问题。本文将讲述微服务架构1.0设计与实践以及面临问题和破局,最后讲述微服务架构2.0设计与实践等方面,尝试去回答这个难题。
-

-

-

武汉肺炎疫情把远程医疗又推向大家的视线中来。远程医疗作为近年来热度最高的新兴科学之一,融合了医学、通信、信息等领域,对推动我国医疗卫生事业的发展具有重要的战略意义。远程医疗能有效改善医院医疗资源偏态分布的情况,并支持医学互动和会诊降低对时间和空间的要求。
-

伴随5G技术加速落地,云游戏作为5G应用落地的最佳场景,已经成为全球游戏厂商和云服务厂商布局的重要战场。根据艾媒咨询数据显示,2018年中国云游戏市场规模为6.3亿元,而到2023年,市场规模将飙至千亿元。
-

十大类疫情服务紧缺 阿里广发英雄帖抗疫小程序开发者最高可获50万元奖励
全民积极响应国家抗击新冠肺炎疫情的号召,正催生出越来越多新的互联网服务缺口。基于对用户、政府、企事业单位抗疫服务需求的紧缺情况调查,支付宝今日面向社会各界开发者发布“10大疫情期最急需服务开发清单”,号召更多开发者投入进来开发更多服务,解决社会问题。据了解,清单涵盖了口罩预约、疫情上报、社区出入管理、代跑腿、餐饮外卖等疫情防护及便民生活类服务。
-

Docker 上手很容易,但如果将其应用于生产环境,则需要对它有更深入的理解。只有这样,才能确保应用符合我们的预期,或在遇到问题时可及时解决。所以,要想真正掌握 Docker 的核心知识,只靠网络上零散的信息往往是不够的,必须系统性地学习。
-

“云原生全家桶“KubeSphere 如何让企业从容迈进云原生时代?
最近两年,云原生大火。究其原因,“数字化转型”几乎成为所有企业当下最迫切的需求,在这样的趋势下,恰逢新旧IT架构升级的契机,容器、微服务等技术与理念得以发挥所长。众多“上云”企业,寄望于业务能够快速迭代、缩短交付周期、弹性敏捷以及成本控制更优……以支持现有业务的快速发展及创新。
-

2月3日是一个特殊的开工日,为防范疫情,在阿里巴巴钉钉上有超过1000万家企业组织的2亿上班族在线开工。为支持此次史无前例的办公需求,钉钉在阿里云上紧急扩容1万台云服务器来保障钉钉视频会议、群直播、办公协同等功能,保障用户流畅体验。
-

2月3日,华中科技大学同济医学院基础医学院、华中科技大学同济医学院附属武汉儿童医院、西安交通大学第一附属医院、中科院北京基因组研究所、华为云联合科研团队宣布,筛选出五种可能对2019新型冠状病毒(2019-nCoV)有效的抗病毒药物。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net