



- 相关博文
- 最新资讯
-
HBase数据库不同于一般的数据库,如MySQL数据库和Oracle数据库是基于行进行数据的存储,而HBase则是基于列进行数据的存储,这样的话,HBase就可以随着存储数据的不断增加而实时动态的增加列,从而满足Spark计算框架可以实时的将处理好的数据存储到HBase数据库中的需求。从上述返回结果可看到,Hive中包含hive_hbase_emp_table表,HBase中包含hbase_emp_table表,说明Hive与HBase整合成功后,可以在Hive中创建与HBase相关联的表。
-

- 想你依然心痛
- 昨天
-
-
针对豆瓣电影TOP250页面(或其他分类页面),需设置合理的请求间隔(如2-3秒)避免被封禁。爬取字段包括电影名称、导演、主演、评分、评论人数、上映年份、类型等。使用Pandas处理缺失值、重复值及格式转换。评分需转换为数值类型,评论人数需去除“人评价”文本并转为整数。将Hive查询结果导出为CSV,使用Python的Matplotlib或Tableau生成图表。例如绘制评分分布直方图、类型占比饼图等,形成分析报告。通过HiveQL执行查询分析,例如计算各年份平均评分、类型分布、高评分导演排名等。
-

- m0_59969565
- 昨天
-
-
本文介绍了使用Docker容器快速部署Kafka、MySQL和Redis服务的方法。对于Kafka,使用wurstmeister镜像分别启动Zookeeper和Kafka容器,配置了消息大小限制、端口映射及数据卷挂载。MySQL和Redis则通过官方镜像部署,设置了自动重启、日志限制等参数。三种服务均配置了持久化运行(--restart always)和端口暴露,其中MySQL还设置了root密码。这些命令提供了快速搭建分布式系统基础组件的标准方案。
-

- xinLD6
- 昨天
-
-
本文详细介绍了基于SpringBoot集成RabbitMQ构建可靠消息系统的方案。系统采用DirectExchange实现精确路由,包含生产者、消费者和核心配置三部分。通过消息持久化、JSON序列化、事务管理和重试机制确保消息可靠传递,并支持动态调整消费者数量应对负载变化。文章重点讲解了交换机/队列配置、绑定关系、消息发送与消费的实现细节,以及幂等性处理、事务边界控制等最佳实践。该方案适用于需要异步通信和解耦的系统场景,具备高可靠性和扩展性。
-

- 绝顶少年
- 前天
-
-
最终需要得到一个类对象,而这需要内存来存放,因此需要分配内存空间,根据刚才读取到的内容,确定出类对象需要的内存空间,申请这样的内存空间,并且把内存空间中所有的内容,都初始化为0。魔幻数字,计算机圈子中约定俗成的做法,二进制文件中,会在开头的若干个字节,设置一个固定的常熟进去,通过这个常数,标识当前这个文件是什么样的文件。防止用户自己写的类,把标准库的类给覆盖掉,保证标准库的类,被加载的类优先级是最高的,扩展库其次,第三方库的优先级最低。谈到地址就是“内存”的地址,而文件(硬盘)中没有地址的概念。
-

- 默默无闻的白夜
- 前天
-
-
安装下eslinnt pnpm add eslint -d (这里指定下eslint8.0的版本更兼容,9.x的还需要装一些相关依赖)Vue // 支持 Vue 语法的模板(需 Umi 4+)Ant Design // 集成 Ant Design 组件库的模板。// 其他社区模板(视 Umi 版本而定)React // 纯 React 模板(默认)Simple // 基础模板(仅包含核心依赖)配置.vscode/settings.json文件。npm源 选择taobao。
-

- 小墨宝
- 前天
-













-

数据库是应用及计算机的核心元素,负责存储运行软件应用所需的一切重要数据。为了保障应用正常运行,总有一个甚至多个数据库在默默运作。我们可以把数据库视为信息仓库,以结构化的方式存储了大量的相关信息,并合理分类,方便搜索及使用。
-

数据库连接池和线程池等池技术存在的意义都是为了解决资源的重复利用问题。在计算机里,创建一个新的资源往往开销是非常大的。而池技术可以统一分配,管理某一类资源,它允许我们的程序可以重复的使用这个资源,只有在极端情况下(比如连接池满)才会创建新的资源。
-

随着业务的发展,MySQL数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
-

“删库跑路”这个词儿,经常被挂在嘴边当玩笑,是因为大家都知道,一旦真的发生这样的事情,企业损失是无比惨重的。
-
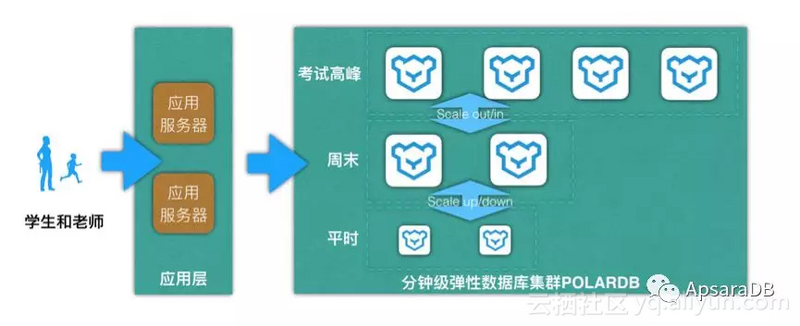
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
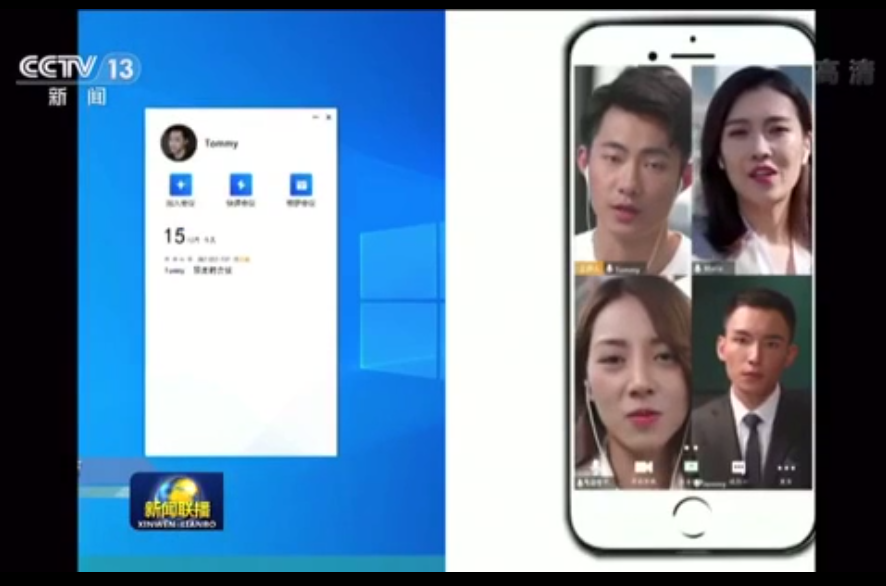
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

近年来超融合在国内迎来快速增长,根据IDC最新发布的报告,2019上半年中国超融合市场增长率达56.7%,大幅超越去年同期。Gartner发布的最新报告,到2023年我国超融合市场依旧保持23%的快速增长。超融合覆盖范围正在进一步扩大,不仅服务的客户在向大规模企业扩张,应用场景也从服务器虚拟化、VDI扩展到数据库、私有云等关键业务。
-

12月3日,广州云峰会上,阿里云宣布推出面向混合云场景的CPFS一体机和视觉AI一体机,两款新品具备超高性能、开箱即用等特性,极大降低企业上云的周期和门槛。加上此前推出的POLARDB数据库一体机和蚂蚁mPaaS一体机,阿里云已为客户提供了四款一体机家族产品,集结了云、网、边、端一体化的能力,打破云的边界,让企业能够随时随地全栈、全态、甚至全域上云。
-

-

华为云TaurusDB计算存储分离架构:让数据“身”分离,“心”凝聚
在2019年HC大会上,华为重磅推出最新一代高扩展海量存储分布式数据库——TaurusDB,它拥有一个最大的特点就是将存储和计算以一种分离的架构形式运行。很多人就会问到,华为云为什么会设计这款产品?核心竞争力是什么?对比原生MySQL的优势有哪些?借此时机,CSDN记者有幸采访到了华为云TaurusDB数据库资深技术专家,现在就请他来为我们一一解答。
-

-

2019年技术盘点云数据库篇(一):UCloud专家谈云数据库:千锤百炼 云之重器
公有云逐渐成为企业运行 IT 设施的新趋势,那么作为企业最核心的系统—数据库,数据上云也成为大数据时代的必然选择。对企业来说,数据可视为其命脉,因此数据迁移上云就意味着将企业“命脉”搬到云平台。事实上,数据上云有两种形式,数据库直接上云或者选择云数据库,而云数据库利用其云原生的优势具备了许多过去数据库产品不具备的优势,包括可靠性、弹性、存储容量以及成本等,正逐渐被更多的企业所接受。
-

-

近日,开源数据库厂商MongoDB与阿里云在北京达成战略合作,作为合作的第一步,最新版MongoDB 4.2数据库产品正式上线阿里云平台。
-

CSDN云计算「C课有道」栏目趁着这股技术风潮再次如期而至啦!秉承「门门有路,路路有门」的理念,这次CSDN云计算小分队特邀阿里云、腾讯云、青云、天云等企业内的“国宝级”架构师,共同打造了一款数据库系列进阶教程,效果绝堪比“红宝书”。 从数据库宏观发展入手,内容主要涉及云数据库为代表的非关系型数据库、MySQL数据处理、分布式等诸多技术要点,将造福开发者设置为终极指标,纯技术绽放的精彩无限,实在不容错过。
-

四大开源项目联合发布 腾讯已成Github全球贡献前十公司!
近日在Techo开发者大会上,腾讯正式对四大重点开源项目进行了联合发布,包括分布式消息中间件TubeMQ、基于最主流的 OpenJDK8开发的Tencent Kona JDK、分布式HTAP数据库 TBase,以及企业级容器平台TKEStack。
-

正式开源TKE和TBase,腾讯正成为大数据领域开源全面的厂商
在11月6日召开的Techo开发者大会上,腾讯云副总裁、腾讯数据平台部总经理蒋杰博士正式对外披露腾讯大数据平台10年技术演进历程。经过10年的积累,腾讯大数据平台的算力资源池目前已有超过20万台的规模,每天实时数据计算量超过30万亿条,并且随着资源管理平台核心TKE和分布式数据库TBase正式对外开源,腾讯正在成为大数据领域开源全面的公司。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net