



- 相关博文
- 最新资讯
-
比如说,有家企业升级信息化系统,要从 Oracle 换成国产数据库,因为 KingbaseES 对 Oracle 语法很熟悉,开发团队就改了改少量代码,系统就顺利迁移过去了,项目时间一下子缩短了不少。金仓数据库的代码都是自己写的,100% 自主,还通过了国家权威机构的严格认证,好几次通过中国信息安全测评中心、国家保密科技测评中心联合发布的《安全可靠测评结果》,还有国家信息安全产品认证、信息技术产品安全分级评估证书(EAL4+)这些资质。而且它的集群架构多样,企业业务发展了,能随时扩展。
-

- 程序边界
- 2025-08-31
-
-
文章摘要 Git-sizer是一款专业的Git仓库分析工具,可帮助开发者优化日益臃肿的代码库。本文深入解析了Git内部数据结构(Blob、Tree、Commit、Tag对象)及其对仓库大小的影响,详细介绍了Git-sizer的核心功能,包括尺寸统计、大文件检测和结构分析等。文章提供了多平台安装指南和配置选项说明,并演示了基础命令使用、文本/JSON格式输出解读以及详细模式分析。通过Git-sizer,开发者可以识别仓库膨胀根源,检测性能瓶颈,并制定有效的优化策略,从而提升团队协作效率。
-

- 止观止
- 昨天
-
-
遇到Elasticsearch导出超1万条数据时出现"Result window is too large"报错,原因是默认的index.max_result_window限制为10000条。解决方案包括:1)临时调大该参数(有性能风险);2)改用Scroll API(适合批量导出)。经验表明:from+size分页仅适合小数据量,大数据导出应使用Scroll API,实时分页推荐Search After。通过改用Scroll API成功解决了全量数据导出问题。
-

- 知彼解己
- 23小时前
-
-
RabbitMQ入门指南:解耦与异步通信的利器 RabbitMQ是一个强大的消息队列系统,解决了传统同步调用模式中的性能瓶颈、脆弱性和扩展性问题。通过将RabbitMQ作为"智能邮局"置于系统中间,实现了服务间的解耦、异步通信、削峰填谷和可靠性保障。RabbitMQ包含生产者、消费者、交换机、队列和绑定等核心组件,支持Fanout(广播)、Direct(精确匹配)和Topic(模式匹配)三种交换机类型,分别适用于不同的消息分发场景。与Redis的Pub/Sub相比,RabbitMQ提供了
-

- Asakeiii
- 昨天
-
-
当业务进入分布式与微服务化,网络就不再是“透明的管子”,而是系统设计的一等公民。理解南北/东西流量、掌握 Clos/Overlay 的取舍、用工程化的方法治理失败域与变更,把可观测性植入日常运维——这是把上万台服务器管“稳、顺、便宜”的唯一道路。---# 📖 专业名词速查表(网络与分布式架构)| 名词 | 全称/缩写 | 简单解释 || **南北流量** (North–South Traffic) | — | 数据中心和外部世界之间的流量,比如用户访问网站、APP 请求接口。
-

- 君科程序定做
- 前天
-
-
本文介绍了在Ubuntu 22.04上部署OpenStack传统架构的详细步骤。主要内容包括: 系统准备:更新系统、安装基础工具 核心服务配置: 配置主机名和时间同步 安装并优化MariaDB数据库 设置RabbitMQ消息队列 部署Memcached缓存服务 关键组件安装: Keystone身份认证服务 其他核心服务如Glance、Nova、Neutron、Cinder等 数据库初始化:为各服务创建专用数据库和用户 文中提供了详细的命令行操作和配置说明,特别强调了密码替换和网络设置等注意事项。该部署方案采
-

- 安全菜鸟
- 昨天
-
-
mysql命令行导出csv文件时,若字段里有换行符,输出的文件就会在换行符前面加一个反斜杠,这种非标准的csv导入到excel也乱行了。网上查了好多文章,都建议在相应的字段上加replace函数,把换行符替换成特殊标记,这显然是非常笨的做法,无法通用,特别是无法预测哪个字段会有换行符的。2、用sed把Csv中“+换行符”替换成“换行符”这时,再用excel打开,就不会有乱行的问题。1、导出csv时,给字符型字段值加上双引号。
-

- 无级程序员
- 前天
-
-
倒排索引:通过词项字典和倒排列表实现高效全文搜索,支持跳表、前缀压缩等优化技术。 数据操作:采用路由算法定位分片,写入需主分片确认后同步副本,读取可轮询主/副本分片。关键词检索采用两阶段查询机制(Query+Fetch)。 持久化机制:通过内存缓冲区、Translog日志和定期刷新/提交操作实现数据可靠性,默认1秒近实时可见。 并发控制:基于_seq_no和_primary_term的乐观锁机制,避免写冲突。 集群管理:包含Master选举流程和防脑裂策略。
-

- 倚-天-照-海
- 前天
-
-
网上很多让你在服务器上下载或者定位到githup上的我觉得都不太好,不够清晰。1.java开发,方便修改源码(比如文件内容加密,或者其他特定的分词处理)*******es版本要严格对应ik版本********上面收录了各个版本es对应的ik分词器版本,特别注意。比如es为6.3.2那么ik也要下载6.3.2。3.配置文件响相对于简单。2.中文分词效果比较好。
-

- Mr.Entropy
- 前天
-
-
Apache ZooKeeper 是一个开源的分布式协调服务,由 Apache 软件基金会托管。它旨在为分布式应用提供一个高性能、高可用且具有严格顺序访问控制能力的分布式配置管理、同步和命名注册服务。
-

- 时间裂缝里的猫-O-
- 昨天
-
-
对es输入指令可以用很多种方法比如用es的谷歌浏览器插件,亦或者postman,我个人比较喜欢用postman比较简单直接。网上针对es常用命令好多都是写的感觉非常复杂难以理解,所以我还是自己整理了一下相关的常用命令。1.删除指定索引下的所有数据。
-
- Mr.Entropy
- 昨天
-
-
本文介绍了使用FastAPI+Celery+RabbitMQ实现邮件发送功能的完整流程。首先安装必要依赖,配置Celery应用连接RabbitMQ消息队列和Redis存储后端。然后定义发送邮件的Celery任务,包括SMTP连接、异常处理和日志记录。通过FastAPI创建API接口接收邮件请求,调用Celery异步任务发送邮件。最后启动Celery Worker和FastAPI服务,测试验证邮件发送功能,并展示了任务执行日志和Redis存储的任务元数据。整个方案实现了高效可靠的异步邮件发送服务。
-

- logo23694
- 昨天
-





-

数据库是应用及计算机的核心元素,负责存储运行软件应用所需的一切重要数据。为了保障应用正常运行,总有一个甚至多个数据库在默默运作。我们可以把数据库视为信息仓库,以结构化的方式存储了大量的相关信息,并合理分类,方便搜索及使用。
-

数据库连接池和线程池等池技术存在的意义都是为了解决资源的重复利用问题。在计算机里,创建一个新的资源往往开销是非常大的。而池技术可以统一分配,管理某一类资源,它允许我们的程序可以重复的使用这个资源,只有在极端情况下(比如连接池满)才会创建新的资源。
-

随着业务的发展,MySQL数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
-

“删库跑路”这个词儿,经常被挂在嘴边当玩笑,是因为大家都知道,一旦真的发生这样的事情,企业损失是无比惨重的。
-
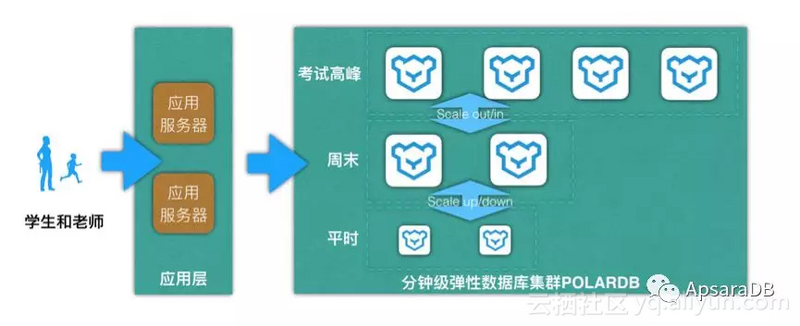
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

探索处理数据的新方法,8 个重点带你搞懂云数据库——DBaaS(数据库即服务)到底是什么!...
在分析的世界中,网站的每次点击都是数据分析的候选对象,显然,这会涉及大量的数据生成。
-

数据安全对企业生存发展有着举足轻重的影响,数据资产的外泄、破坏都会导致企业无可挽回的经济损失和核心竞争力缺失,而往往绝大多数中小企业侧重的是业务的快速发展,忽略了数据安全重要性。近年来,企业由于自身的安全防护机制不严谨,引发的数据安全事件频发。抛开事件本身的人为因素不谈,如何从技术角度避免类似的事件发生,才是我们需要认真总结的。
-

众志成城 共克时艰 TigerGraph免费开放企业级版本授权全力支持疫情防控
新型冠状病毒肺炎疫情自发生以来,一直牵动着全国人民的心。全球领先的可扩展企业级图数据库TigerGraph宣布,利用强大的企业级图数据库产品,免费开放企业级版本授权,为政府机构、公共事业和科研机构赋能,帮助实现更加科学和有效的研究和决策,减轻疫情对社会和经济的影响。
-
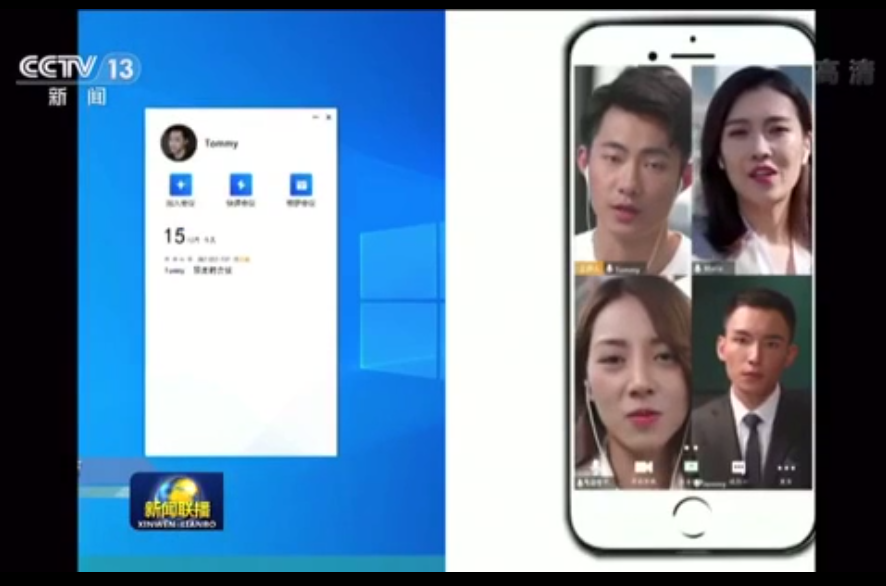
受疫情影响,多数企业员工目前无法回到写字楼办公,学生推迟开学,稳定高效的远程办公和直播授课成为2020年的开年刚需。腾讯从1月24日开始向全国免费开放可支持300人同时在线会议的“腾讯会议”,直至疫情结束。央视新闻联播对此也给予了报道。
-

近年来超融合在国内迎来快速增长,根据IDC最新发布的报告,2019上半年中国超融合市场增长率达56.7%,大幅超越去年同期。Gartner发布的最新报告,到2023年我国超融合市场依旧保持23%的快速增长。超融合覆盖范围正在进一步扩大,不仅服务的客户在向大规模企业扩张,应用场景也从服务器虚拟化、VDI扩展到数据库、私有云等关键业务。
-

12月3日,广州云峰会上,阿里云宣布推出面向混合云场景的CPFS一体机和视觉AI一体机,两款新品具备超高性能、开箱即用等特性,极大降低企业上云的周期和门槛。加上此前推出的POLARDB数据库一体机和蚂蚁mPaaS一体机,阿里云已为客户提供了四款一体机家族产品,集结了云、网、边、端一体化的能力,打破云的边界,让企业能够随时随地全栈、全态、甚至全域上云。
-

-

华为云TaurusDB计算存储分离架构:让数据“身”分离,“心”凝聚
在2019年HC大会上,华为重磅推出最新一代高扩展海量存储分布式数据库——TaurusDB,它拥有一个最大的特点就是将存储和计算以一种分离的架构形式运行。很多人就会问到,华为云为什么会设计这款产品?核心竞争力是什么?对比原生MySQL的优势有哪些?借此时机,CSDN记者有幸采访到了华为云TaurusDB数据库资深技术专家,现在就请他来为我们一一解答。
-

-

2019年技术盘点云数据库篇(一):UCloud专家谈云数据库:千锤百炼 云之重器
公有云逐渐成为企业运行 IT 设施的新趋势,那么作为企业最核心的系统—数据库,数据上云也成为大数据时代的必然选择。对企业来说,数据可视为其命脉,因此数据迁移上云就意味着将企业“命脉”搬到云平台。事实上,数据上云有两种形式,数据库直接上云或者选择云数据库,而云数据库利用其云原生的优势具备了许多过去数据库产品不具备的优势,包括可靠性、弹性、存储容量以及成本等,正逐渐被更多的企业所接受。
-

-

近日,开源数据库厂商MongoDB与阿里云在北京达成战略合作,作为合作的第一步,最新版MongoDB 4.2数据库产品正式上线阿里云平台。
-

CSDN云计算「C课有道」栏目趁着这股技术风潮再次如期而至啦!秉承「门门有路,路路有门」的理念,这次CSDN云计算小分队特邀阿里云、腾讯云、青云、天云等企业内的“国宝级”架构师,共同打造了一款数据库系列进阶教程,效果绝堪比“红宝书”。 从数据库宏观发展入手,内容主要涉及云数据库为代表的非关系型数据库、MySQL数据处理、分布式等诸多技术要点,将造福开发者设置为终极指标,纯技术绽放的精彩无限,实在不容错过。
-

四大开源项目联合发布 腾讯已成Github全球贡献前十公司!
近日在Techo开发者大会上,腾讯正式对四大重点开源项目进行了联合发布,包括分布式消息中间件TubeMQ、基于最主流的 OpenJDK8开发的Tencent Kona JDK、分布式HTAP数据库 TBase,以及企业级容器平台TKEStack。
-

正式开源TKE和TBase,腾讯正成为大数据领域开源全面的厂商
在11月6日召开的Techo开发者大会上,腾讯云副总裁、腾讯数据平台部总经理蒋杰博士正式对外披露腾讯大数据平台10年技术演进历程。经过10年的积累,腾讯大数据平台的算力资源池目前已有超过20万台的规模,每天实时数据计算量超过30万亿条,并且随着资源管理平台核心TKE和分布式数据库TBase正式对外开源,腾讯正在成为大数据领域开源全面的公司。
活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net