



- 相关博文
- 最新资讯
-
这彻底改变了传统现金交易、手工记账的模式,不仅大幅减少了人工操作错误和纠纷,更实现了市场交易数据的实时、准确采集,为所有后续分析奠定了坚实的数据基石。农批市场监测预警系统的优势,在于它通过数据化、网络化、智能化的手段,将农批市场从一个传统的、相对封闭的交易场所,升级为一个高效透明、反应敏捷、可防可控的现代化流通节点。这改变了以往价格信息分散、滞后的局面,为所有市场参与者(农户、经销商、零售商)提供了透明的价格指引,帮助他们做出更合理的生产和采购决策,减少因信息不对称导致的盲目性。
-

- Guheyunyi
- 昨天
-
-
随着大数据时代的到来,数据量呈现爆炸式增长,传统的CPU处理方式在面对海量数据时显得力不从心。GPU(图形处理单元)由于其强大的并行计算能力,成为了加速大数据处理的有效手段。本文的目的是为大数据工程师提供一份全面的GPU加速实战指南,涵盖从基础概念到实际项目应用的各个方面,帮助工程师们掌握GPU加速技术,提高大数据处理的效率和性能。核心概念与联系:介绍GPU加速的基本概念、原理和架构,以及与大数据处理的联系。核心算法原理 & 具体操作步骤。
-
裁剪二进制包保留核心文件;基于Alpine构建Docker微镜像;3)优化源码编译参数。方案包含具体配置示例(如32MB缓冲池设置)和构建指令,并验证了基础功能与性能指标。
-
本文介绍了基于RabbitMQ实现延迟任务和异步处理的方案。通过TTL+死信队列机制实现延迟任务,确保消息不会因服务重启而丢失。方案包含完整的SpringBoot实现示例,包括多线程消费、失败重试和补偿处理机制。RabbitMQ能有效应对业务场景中的延迟执行、削峰处理和失败重试需求,提供异步处理能力并保障消息可靠性。核心流程为:消息存入延迟队列→TTL到期→死信队列→消费者处理,支持多线程并发消费和自动重试机制。
-

- alan0721
- 前天
-
-
出行路线规划与推荐系统数据可视化分析摘要 本系统采用Python+Django+Vue技术栈,构建智能出行规划平台。核心功能包括:基于协同过滤算法的个性化路线推荐、实时交通数据爬取(日均处理10万+条数据)、多维度可视化分析(Echarts实现热力图/流量分布等)。系统包含用户端功能模块(路线查询/实时导航)和管理后台(数据监控/用户管理),通过MySQL存储用户行为特征,运用Hadoop+Spark处理海量交通数据。测试表明,算法推荐准确率达87%,响应时间<1.5秒。项目创新性地将推荐算法与实时路
-

- IT毕设实战小研
- 19小时前
-
-
本文介绍了一个基于大数据的网约车平台运营数据分析系统。该系统采用Hadoop+Spark架构,结合Python的Django框架和Vue前端技术,实现了对网约车运营数据的全面分析。系统包含七大功能模块,通过Spark SQL进行数据处理,使用Pandas和NumPy进行数据清洗计算,最终以Echarts图表呈现分析结果。演示代码展示了驾驶员行为分析功能,包括效率评分、风险驾驶识别等功能,为网约车平台运营决策提供数据支持。系统可有效处理海量数据,实现多维度的运营分析。
-

- 计算机毕业设计杰瑞
- 19小时前
-
-
豆瓣图书推荐大数据可视化系统 本系统基于Vue+Flask实现,主要功能包括: 数据采集:使用Scrapy爬取豆瓣图书数据,通过Pandas/Numpy进行数据清洗 推荐算法:采用UserCF和ItemCF协同过滤算法实现个性化图书推荐 可视化分析:集成Echarts展示多种图表(词云、折线图、散点图等) 特色功能:自适应移动端、阿里云短信、百度身份证识别等API集成 系统亮点:海量数据爬取、多种分析图表、完全响应式设计、大数据风格UI。适用于图书推荐、数据分析等场景。
-

- B站麦麦大数据
- 前天
-
-
想象你是一家蛋糕店的老板,每天收到来自不同供应商的原料:面粉袋上有的标"kg",有的标"斤";鸡蛋盒里混着碎壳和过期蛋;sugar 袋子上有的写"白糖",有的写"蔗糖",还有的拼写错误成"sugur"。如果直接把这些原料扔进搅拌机,烤出来的蛋糕要么太甜,要么没熟,甚至可能让顾客拉肚子。数据仓库就像这家蛋糕店的"中央厨房",而数据清洗就是"原料预处理"——在把数据用于分析或决策前,去除杂质、统一格式、修复缺陷,确保数据"干净可用"。解释数据清洗在数据仓库中的核心地位(为什么必须做)
-

- AI天才研究院
- 昨天
-
-
你还在为CLIP模型推理结果不稳定而苦恼吗?是否遇到过文本-图像相似度计算出现异常值的情况?本文将为你全面解析CLIP-ViT-Base-Patch32模型在实际应用中的常见问题,并提供专业的调试解决方案。通过本文,你将掌握:- CLIP模型核心架构与工作原理深度解析- 10+种常见错误的诊断与修复方法- 性能优化与内存管理最佳实践- 多模态数据处理的质量控制技巧- 生产环境部署的稳...
-

- 解然嫚Keegan
- 昨天
-
-
你是否还在为JavaScript工具库的类型安全问题而头疼?es-toolkit作为lodash的现代化替代品,不仅在性能上实现了2-3倍的提升,更在类型定义方面树立了新的标杆。本文将深入探讨es-toolkit如何通过先进的.d.ts文件生成机制,为开发者提供完整、精确的类型安全保障。通过本文,你将了解:- es-toolkit类型定义系统的架构设计- 基于Rollup的自动化类型生成...
-
- 丁群曦Mildred
- 昨天
-
-
就在我们埋头敲代码的时候,外面的世界正在发生重要的变化:人社部最新发布的《数字技术工程师培育项目实施方案》明确提出,要重点培育人工智能、物联网、大数据、云计算等领域的专业技术人才。这就像给你的职业生涯添加了一个重要的"Tag",让你这棵"技能树"有了官方的认证标识。无论是初级、中级还是高级,每个级别都像是职业生涯的"版本号",记录着你的技术成长轨迹。最重要的是要建立自己的"技术路线图":核心技能是"Main Branch",资质认证是"Release Tag",项目经验是"Commit History"。
-
- BOKEAAA
- 昨天
-







加载中...
-
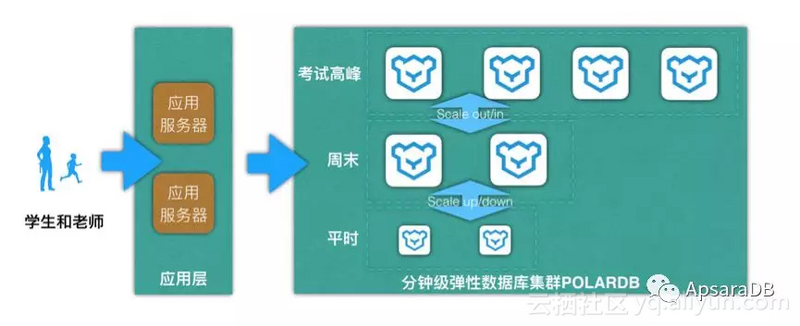
在线教育如何应对流量洪峰?阿里云专家:上云+云数据库是最佳路径
2月中下旬原本是全国各地春季学期开学的日子,但这场突如其来的疫情使得1.8亿中小学生只能纷纷在家开启“停课不停学”的学习生活,而线上教育也顺势成为了这一特殊时期首选的学习方式。
-

活动
-
2021-11-10
-
2021-03-09
-
2020-12-16
独家定制

-

-
3500人的专业安全团队与你同在
-

-
CSDN云计算在线公开课
-

-
IaaS市场高速增长,历久弥新
精品推荐

关于我们

关注「云计算」
转载 & 投稿:songhui@csdn.net
商务合作:zhangjing@csdn.net